![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
12 Cards in this Set
- Front
- Back
|
What are advantages and disadvantages of multimodal compared to purely speech-based dialog systems? |
+ more natural |
|
|
What is the difference between a multimedia and a multimodal system? |
Multimedia system doen't summarize the information from user to make the dessicion. |
|
|
Name some input and output modalities
|
For the classification of output modalities, Bernsen (1999) employs the 5 properties
- Linguistic vs. non-linguistic: Linguistic modalities are based on a syntactic-semantic-pragmatic system of meaning. Examples for this are e.g. written text, or spoken language - Analogous vs. non-analogous: Analog modalities rest on a similarity between the designator and the designated; therefore, they are alternatively called iconic modalities. Examples for analog modalities are pictures and diagrams. - arbitrary vs. non-arbitrary: Non-arbitrary modalities are based upon an established system of meaning, arbitrary ones don’t. - static vs. dynamic: Static modalities may perceived by a user in principle in any order, and by any duration, while dynamic modalities may not. - Class of media: graphical (visually perceivable), acoustic (to be perceived auditorily) or haptical. Input modalities: As above, but without static/dynamic |
|
|
According to which "rules“ can you select appropriate input and output modalities? |
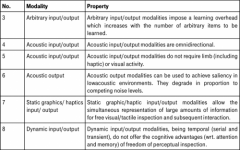
|
|
|
Explain the set-up and the functions of a multimodal dialog system! |
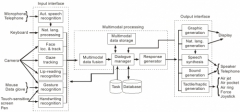
|
|
|
How can a face be recognized automatically? |
1. Rule-based: Description of the facial area (relative position of features like mouth, eyes, nose) via a set of rules |
|

How can you detect and track gazes?
|
1. Cornea Reflex Method: Reflextion of a beam of light at the cornea surface
2. Electro Oculograms (EOG): Measurement of the electrical potential between cornea and retina 3. Preparated contact lenses |
|
|
What is the advantage of audio-visual over purely audio speech recognition? |
Fusion of acoustic and visual information |
|
|
What are the classes of Text Recognition? |
- Offline recognition of fixed shapes: Static Optical Character Recognition (OCR) of typed or handwritten characters |
|
|
Explain the terms fusion and fission. |
The basic idea is that the system makes decisions/reacts based on all the input modalities. Thus, it has to "fuse" the data in order to make a decision. |
|
|
Which types of gestures do you know, and how can you recognize them automatically? |
Classification of Gestures: |
|
|
What is an Embodied Conversational Agent (ECA), and how does it work? |
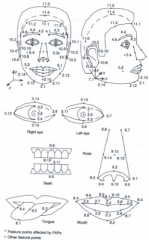
- Output of speech, mimics and gestures |