![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
15 Cards in this Set
- Front
- Back
|
What things have to be considered when transforming speech signal to symbol level? |
1. Speech: Language, dialect, speaking style, …
|
|
|
What makes speech recognition difficult? |
1. Variances and invariances in the speech signal have to be differentiated 2. Contextual knowledge helps to understand: „to recognize speech“ <-> „to wreck a nice beach“
|
|
|
Explain the schematic setup of speech recognizer (ASR). |
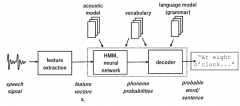
1. Feature extraction from signal |
|
|
In which state of speech recognizer are HMM and neural networks usually used? |
Acoustic model and lexicon. Language model usually utilized HMM. |
|
|
Name 3 ideas of Feature Extraction |
Feature Extraction - Extract information which allow to differentiate between sounds - First idea: (Fourier) Spectrum
|
|
|
Explain how feature extraction of Mel-scaled ceptrum works. |
1. FFT for a signal window |
|
|
Explain the steps of perceptual linear predictive (PLP) coding. |
1. Windowed via a Hamming-window |
|
|
Explain what RASTA tries to solve and how it works. |
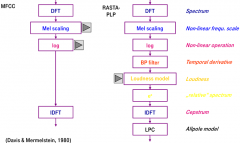
Tries to be robust against interferences, additive and multiplicative. It is better against multiplicative. |
|
|
What is the idea of Markov chain in speech recognition. When is it called hidden? |
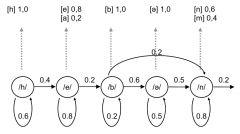
One state corresponds to one symbol. Transitions to next states (and to itself) determined by transition probabilities. In speech recognition usually only one way, i.e. no going back in the chain. The result is the emitted symbols. One state can emit several symbols and these several symbols have emission probabilities (not one-to-one match). This means output sequence doesn't tell which states were visited, that's why it's called a hidden model. Hidden = two stochastic levels 1)transitions 2)emitted symbols |
|
|
What is phoneme HMM? How does it differ from normal HMM? |
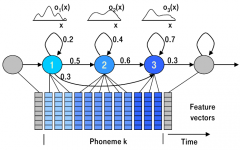
Doesn't output discrete symbols, but ... Takes co-articulation into account. |
|
|
What can be achieved with Viterbi algorithm? |
Finding the most likely path in HMM quickly. |
|
|
What does perceptron do in speech recognition? What is its basic structure? |
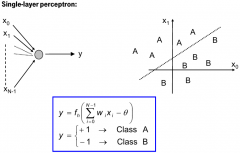
It's a two class classifier. It calculated the weighted sum of feature vector and outputs either class 1 or 2. Putting perceptions in series makes it possible to have more than two classes. Good for one phoneme classification. |
|
|
What is n-gram language model? |
The probabilities of n words succeeding each other are analysed from texts. Those probabilities are used in making decisions in speech recognition. If certains words are not succeeded by each other in grammar, single word probabilities are used, that is called n-gram back-off language model. |
|
|
How can you measure speech recognizer error? |
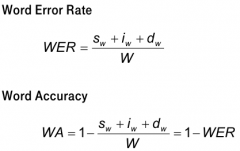
1. Two ways: Word Error Rate (WER) or Word Accuracy (WA). Also sentence error rates etc. possible.
|
|
|
What can be done to improve speech recognizer results? |
1. Training material in real conditions
|