Reading...
![]()
Play button
![]()
Play button
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
159 Cards in this Set
- Front
- Back
|
adjacent speech sounds that
require the same articulator use a single articulatory gesture for both sounds |
assimilation
|
|
|
"I miss you", the /s/
and /j/ phonemes both require particular articulations of the tongue tip and blade, so the /s/ is often produced with the palatal gesture of the /j/, resulting in a // sound (and similar sequences are found with other alveolar and palatal combinations, like in "did you") |
example of assimilation
|
|
|
adjacent speech sounds that
use different articulators can be overlapped in production (two articulations simultaneously) |
coarticulation
|
|
|
For example, the /s/ does not require the use of
the lips, so lip rounding in an adjacent sound (like /u/) can begin during the /s/ (compare "seat" and "suit", similarly for "tea" and "two") – Another example is nasalization, as the velum can be lowered for nasal sounds during the production of the vowel before the nasal |
example of coarticulation
|
|
|
Variation in the degree to which the articulators
reach their "ideal articulatory goals" is referred to as degrees of |
hyperarticulation and hypoarticulation
|
|
|
very careful
pronunciation |
hyperarticulation
|
|
|
pronunciation that undershoots the target
|
hypoarticulation
|
|
|
do not
achieve the extreme articulations that they would if produced in isolation as in rapid speech |
corner vowels
|
|
|
Assimilation or coarticulation can create an
acoustic result for an articulation that is different from what is produced in isolation. In many cases, the combined articulation reflects information about the two (or more) sounds that are combined together. Part of why speech sounds are hard to read from spectrograms. |
what happens to acoustics of context effects and their affects on formants?
|
|
|
As articulatory positions change, the resonating
frequencies of the vocal tract change. Changing resonant frequencies in the vocal tract result in transitions in the formants of vowels and resonant consonants. Formant transitions in neighboring vowels are a commonly observed cue for the place of articulation of stops |
explain formant transitions
|
|
|
F1: expected to be rising following release
for all stops due to lowering of the jaw/tongue. F2 & F3: differences following release expected for different places of articulation. /b/ : F2 & F3 rise due to release of lip rounding /d/ : F2 & F3 flat of fall (point to high freq.) /g/ : F2 & F3 move apart (point to mid freq.) For all – greater formant movement expected for greater articulatory movement (varies depending on the vowel context). |
explain changes in f1, f2, etc in formant transitions for b, d, and g.
|
|
|
Coarticulation most noticeable for sounds
that are |
adjacent (next to one another)
|
|
|
effects of coarticulation for
sounds 2 or 3 phonemes away depending on |
the speech rate and the particular
articulatory configuration |
|
|
There can be effects of coarticulation for
sounds 2 or 3 phonemes away depending on the speech rate and the particular articulatory configuration. Start of low F3 during the initial vowel in "every") |
every is an example of
|
|
|
aspects of production
that carry over more than one segment |
“Over” segmental
|
|
|
found when two different articulators overlap their productin
|
coarticulation
|
|
|
when producing the common phrase "is she going?", the loudest fricative noise for the /z/ phoneme in "is" is lower than expected, b/c the tongue blade constriction is father back on the palate than it would normally be. This is an example of what?
|
assimilmation
|
|
|
when producing the common phrase "is she going?", the loudest fricative noise for the /z/ phoneme in "is" is lower than expected, b/c the tongue blade constriction is father back on the palate than it would normally be. this effect would be classified as a(n)_______ type of effect.
|
anticipatory
|
|
|
I am talking to a hearing-impaired adult who is having trouble understanding. I make an extra effort to be understood for the word "dog." In looking at this production, I find that the /a/ is "dog" has a higher F1 than it would normally have. This is because of what type of articulatory process?
|
hyperarticulation
|
|
|
the ____ scale is special scale used to model the way the ear processes frequency.
|
Bark
|
|
|
most of the amplification of sound that occurs in the middle ear is due to ______.
|
the difference in SA b/w the tympanic membrane and the oval window
|
|
|
differences b/w frequiences at ___________ are easier to hear
|
low frequiences (20-1000 Hz)
|
|
|
what difference in frequenies is the eaiest for a listener to perceive?
|
differences b/w high vowels and low vowels
|
|
|
from studies of listeners' perception of acoustic properties of speech sounds, which formants are more important for vowel identification
|
f1 and f2 are more important than f3 for vowel identification
|
|
|
Stress
Intonation Duration Juncture |
examples of suprasegmentals
|
|
|
get exaggerated
when talking to children/animals or in “clear” speech. |
Stress
Intonation Duration Juncture as do artic. positions --> formant diffs |
|
|
Tells which syllable of a word or sentence
is most important. |
stress
|
|
|
sometimes tells whether word is a
noun or verb |
lexical stress
|
|
|
english does what to syllables?
|
alternation weak and strong...can tell difference between verb and noun aka lexical stress
|
|
|
primary, secondary, unstressed
|
what are the 3 levels of lexical stress?
|
|
|
"I miss you", the /s/
and /j/ phonemes both require particular articulations of the tongue tip and blade, so the /s/ is often produced with the palatal gesture of the /j/, resulting in a // sound (and similar sequences are found with other alveolar and palatal combinations, like in "did you") |
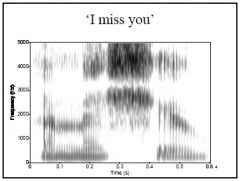
what type of coarticulation is going on here?
|
|
|
Coarticulation- the /s/ does not require the use of
the lips, so lip rounding in an adjacent sound (like /u/) can begin during the /s/ (compare "seat" and "suit", similarly for "tea" and "two") |
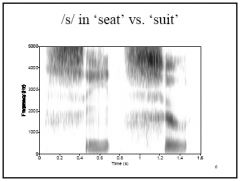
what is going on here in the /s/ in both words?
|
|
|
F1: expected to be rising following release
for all stops due to lowering of the jaw/tongue. • F2 & F3: differences following release expected for different places of articulation. – /b/ : F2 & F3 rise due to release of lip rounding – /d/ : F2 & F3 flat of fall (point to high freq.) – /g/ : F2 & F3 move apart (point to mid freq.) • For all – greater formant movement expected for greater articulatory movement (varies depending on the vowel context) |
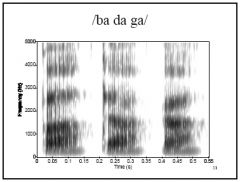
explain the formant differences b/w ba, da, and ga.
|
|
|
special case to distinguish from
a similar word |
Contrastive
|
|
|
Stressed syllables: typically longer in
duration, higher in F0, and greater intensity than the same syllable in non-primary stress position. |
explain the effect of stressed syllables acoustically
|
|
|
Vowel reduction: many vowels reduced to
schwa when in unstressed position, but you see full vowel when put in more stress position. |
explain the effect of vowel reduction acoustically
|
|
|
what creates stress?
|
increase vocal effort
|
|
|
Tells us about a talker’s emotional state,
overall meaning of a sentence, whether done talking or not. |
intonation
|
|
|
rise-fall
(declarative sentence, non yes/no question), fall (emphasis, short unemotional), rise (yes/no question, not finished) |
what are the three general contours?
|
|
|
what is important formantin contours?
|
F0
|
|
|
Different speech sounds differ in duration, even
when in the same context (e.g., tense and lax vowels). (look at some). This helps talkers identify the vowel (especially in noise). |
explain intrinsic duration.
|
|
|
vowels tend to be
longer before voiced than before voiceless stops (helps because final stops often unreleased) |
how does duration change vowels?
|
|
|
relates to pronunciation depending
on location of syllable boundaries |
juncture
|
|
|
when a __________ is
between two _______ you can tell what syllable/word it “belongs” to |
when a consonant is
between two vowels you can tell what syllable/word it “belongs” to |
|
|
when you cannot tell where a consonant belongs to?
|
ambisyllabic
|
|
|
“patty” vs. “party”
|
example of ambisyllabic
|
|
|
How is sound produced differently to show
where word juncture is? |
It sprays, worth less, how to wreck a nice
beach. |
|
|
pinna to tympanic membrane
|
outer ear
|
|
|
Protection, resonator, and localization
|
function of outer ear
|
|
|
tympanic membrane to oval
window (including 3 ossicles) |
Middle Ear
|
|
|
-Conversion of sound from pressure variations
to mechanical vibrations; amplification (lever action and decrease in surface area). – Acoustic reflex (stapedius m.); pressure equalizing. |
function of middle ear
|
|
|
fluid filled space (coiled)
with access to middle ear via oval and round windows |
inner ear aka cochlea
|
|
|
Pressure variations in fluid cause vibration of
basilar membrane (more depending on frequency – basal end --> high frequency; apex end --> low frequency). |
explain the effect of pressure of fluid in the ear
|
|
|
contains hair cells and support cells
|
orgin of corti
|
|
|
contact b/w
tectorial membrane and hair cells causes nerve fiber stimulation |
what does contact with tectorial membrane cause?
|
|
|
Different hair cells (& nerve fibers) for different
frequencies, depending on place (also in cortex) |
explain about hair cells and frequencies
|
|
|
when is hearing is
less sensitive to small changes in frequency or amplitude? |
at higher frequencies or amplitudes
|
|
|
Hearing becomes habituated to a steady sound,
and is more sensitive to dynamic (changing, varying) sounds. |
how is hearing affected by steady and dynamic sounds?
|
|
|
Frequency and amplitude scales for hearing
are (approximately) __________ |
logarithmic
|
|
|
The higher the frequency or amplitude, what to make it audible?
|
The higher the frequency or amplitude, the
larger a change in frequency or amplitude needs to be in order to be audible |
|
|
Special frequency scale
|
bark
|
|
|
Special amplitude scale
|
db
|
|
|
how to spectrograms display amplitude and frequency?
|
Spectrograms do display amplitude in dB, but
usually do not display frequency in Bark. |
|
|
Non-linear frequency in hearing comes in
part from the structure of the |
basilar membrane
|
|
|
Range of hearing is 20-20,000 Hz
– About 1/3 of the basilar membrane for the lowest 1000 Hz of hearing (or 5% of range) - apex to 3rd cochlear turn – Remaining 2/3 of the basilar membrane for 1000-20,000 Hz (95% of range) |
explain about hearing and the basilar membrane
|
|
|
Also, hair cells tend to be less densely
distributed at the basal end. |
how are hair cells distributed on basal end of baslar membrane?
|
|
|
While the dB scale does approximate nonlinearity
in perception of amplitude, it does not reflect the differential sensitivity of the ear at different frequencies |
what does and doesn't the db scale do?
|
|
|
the ear canal amplifies sounds in
the |
3000-5000 hz
|
|
|
what do spectrograms do to reflect the differential sensitivity of the
ear at different frequencies? |
use “pre-emphasis”, raising
the amplitude by 6 dB/octave, to reflect this sensitivity somewhat (not specific enough) |
|
|
Hearing is based on the firing of auditory
nerves, which can habituate |
habituation
|
|
|
After a nerve is fired, its action potential is
depleted and it is more difficult to make it fire again – As a result, the neural response to a steady, unchanging stimulus diminishes in strength over time The stapedius muscle can adjust the amplification level provided by the ossicular chain – Amplitude adjustments by the stapedius muscle are continual and rapid – As a result, unvarying amplitudes will be muted (e.g. vowel steady states) – A sharp rise in amplitude (e.g. stop burst) will have maximum effect, as the stapedius will ‘turn up the volume’ during the closure silence |
explain habituation
|
|
|
the most
useful parts of the spectrogram |
long, steady state portions like stressed
vowels and strident fricatives |
|
|
know Spectrograms vs. Cochleagrams
|
know Spectrograms vs. Cochleagrams
|
|
|
Computer simulations of the function of the
cochlea |
cochleagram
|
|
|
reflects the actual
output of the auditory nerve to the brain better than a spectrogram does |
what do cochleagrams reflect?
|
|
|
which are easier to derive cochleagram or spectrogram?
|
spectrogram
|
|
|
shown researchers
what acoustic features are characteristic of certain categories of sounds |
acoustic cues
|
|
|
the regularities that have
been shown to actually be used by listeners |
acoustic cues
|
|
|
are regularities the same for everyone?
|
NO!
|
|
|
cues don’t vary over a continuum
in real speech (people don’t produce “in between” sounds) |
problem with studying acoustic cues
|
|
|
One (or more) acoustic
properties are varied in steps from what is typical for one phoneme to what is typical for another phoneme |
continum
|
|
|
syllables are presented one at a time;
listeners must decide which sound they heard from among a small number of alternatives |
identification
|
|
|
sounds are presented in
pairs; listeners must decide whether sounds are same or different. |
discrimination
|
|
|
slide 20 acoustic cues throug 22...in hearing and speech perception lecture
|
slide 20 acoustic cues throug 22...in hearing and speech perception lecture
|
|
|
Some cues were clearly found to be more
important than others for some phonemes |
primary cues
|
|
|
most potential cues have been
found to be useful if others not available |
secondary cues
|
|
|
computer processing
of speech |
Speech processing
|
|
|
applications of speech
processing (programs and devices for many purposes) |
Speech technology
|
|
|
producing intelligible
speech via commands to a machine |
Speech synthesis
|
|
|
identifying
phonemes or words via machine |
Automatic speech recognition
|
|
|
take written text and
convert to speech that is easily recognized by listener |
purpose of speech synthesis
|
|
|
Text-to-speech
|
tts
|
|
|
morphology, syntax & prosody (affect how
words are spoken – stress, phrasing, etc.) • print to phonetic symbols (spelling rules) • phonetic symbols to acoustic productions (acoustic cues & coarticulation effects) |
what are the major tasks of speech synthesis?
|
|
|
uses sourcefilter
theory of speech production to create a source sound and filters that can be changed to create desired acoustic output. – Rules for individual phonemes – Rules for phoneme to phoneme transitions (coarticulation/assimilation) – specify type of source for each sound (noise, buzz, both) and shape of filters for each sound at 15 ms increments. – Example: “saw me” (book). /a/ to /m/; /m/ to /i/ |
explain formant synthesis by rule
|
|
|
Small storage needs (computer program) for any
number of voices (pos) • Requires a lot of background knowledge (neg) – Must develop rules for each phoneme and transition to every other possible neighboring phoneme (neg) – Must develop rules for prosody, phrasing, stress rules, etc. |
what are the pros and cons of formant synthesis?
|
|
|
uses natural
speech segmented at areas of “less variability” including diphone and demisyllable |
Concatenative synthesis
|
|
|
phoneme center to phoneme center
|
diphone
|
|
|
syllable onset to nucleus or
nucleus to end |
demisyllable
|
|
|
– Must store every possible combination as a
separate file for each voice used (neg). – Prosody may be too unvarying / breaks (neg). – Hard to speed up appropriately (neg). – Relatively easy to create (pos). |
what are the pros and cons of concatentative synthesis?
|
|
|
speech synthesis application for for speech impaired
(autistic, dysarthric, etc.) |
AAC (augmentative & alternative
communication) |
|
|
why do blind like formant synthesis?
|
(formant
synthesis better because they like up to 600 wpm |
|
|
type of speech synthesis for blind
|
Screen readers
|
|
|
Voice response systems (phone/car/etc.)
• Other automated, repetitive tasks (weather reader) • Toys (Speak-n-Spell) • Create stimuli for research. are examples of |
speech synthesis applications
|
|
|
Alternative approach to formant synthesis. Parameters are based on acoustic
consequences of articulatory positions. |
Articulatory synthesis
|
|
|
• Impossible combinations are not allowed,
unlike for formant synthesis (pos) • Not enough knowledge for it to work well yet (need more imaging of tongue, etc. and mapping to acoustic outputs). |
what are pros and cons of articulatory synthesis?
|
|
|
Use of computer program to take acoustic
input and identify words/phonemes. |
Automatic Speech Recognition
|
|
|
Different from speech understanding
|
Automatic Speech Recognition
|
|
|
– Digitize speech input
– Identify acoustic features in input (may correspond to different phonemes). – Select word/phoneme with most matching features. |
major steps of automatic speech recognition
|
|
|
Requires all our knowledge about how
listeners identify speech sounds. Still not as good as human listeners. |
automatic speech recognition
|
|
|
• Easier if words are separated slightly so
that system knows where they are (human listener doesn’t need this). • Variability is a big challenge: must recognize “same” sounds in different contexts/different talkers as the same. • Background noise is a much bigger problem than for human listeners. • Typically needs training on new talkers / words (depends on type of system) |
what are some Speech Recognizer Issues?
|
|
|
words must be separated by 500 ms
or more |
isolated
|
|
|
words must be separated by only
short pauses |
connected
|
|
|
no pauses needed – accepts
normal conversational speech. |
continuous
|
|
|
another word for connected
|
Dragon system
|
|
|
200 words or less
|
small vocab
|
|
|
200-1000 words
|
large vocab
|
|
|
1000 + words to 20,000 words
|
vary large vocab
|
|
|
needs to be trained for
each new talker |
speaker dependent like cell phone
|
|
|
can recognize any
talker (constrained usually by dialect, voice quality). Much harder, esp. for high accuracy. |
speaker independent
|
|
|
phone system
(needs speaker independent, but small vocab. often okay) – menu systems |
Voice response systems
|
|
|
typing by voice for mobility
challenged or to avoid overuse injuries (Dragon Naturally Talking). Also for hearing impaired. |
Speech to text
|
|
|
decides whether talker achieved goal or
not. |
Computer-Based Speech Training Aids
|
|
|
drive system
selected |
goals and populatione
|
|
|
designed to be used in conjunction
with a speech pathologist. – Small vocabulary, speaker dependent – Speech of children with speech delay is too variable for speaker independent. – Needs multiple goals to avoid frustration (therapists selects and trains). |
explain ISTRA
|
|
|
speaker independent; language specific.
|
hearsay
|
|
|
Want to understand what speech cues
listeners use and whether different groups use them differently. – Understand how language is processed/learned by normal listeners. – Understand differences/disorders. – Create better training methods |
purpose of speech perception experiments
|
|
|
– Type of experiment (identification or
discrimination) – Type of stimuli (synthesized or natural). |
How to study speech perception?
|
|
|
• Specify what formant frequency values
should be (either unchanging or must specify each point in time). • Source is created, goes through filters, output is a file. Create a new file for each stimulus. |
how to use Synthetic Speech for
Research? |
|
|
• Observed: CV and VC formant transitions
vary depending on place of articulation of stops. • Question: Do listeners use it? • Stimuli: vary onset of F2 for transition from consonant to vowel (CV) from steeply rising (/bae/ to steeply falling (/gae/). Each step is same amount higher than last. (Same acoustic difference between neighboring stimuli). |
explain Consonant place of articulation
experiments |
|
|
Identification: Play each stimulus: three
choices (bae/dae/gae). • Analyze data: typically people are very sure for most stimuli – high percent identification. 1 or 2 stimuli at 50% • This means steep identification functions |
explain Place of articulation experiments
|
|
|
Category boundary:
|
where the function of
identification is at 50%. |
|
|
play pairs of stimuli. Some
two steps apart; some exactly the same. Task is to say same or different. |
Discrimination
|
|
|
when you get typical results for place articulation experiments
|
good discrimination only when
two stimuli identified as different phonemes--baffeling result b/c physical differences are equal across all steps |
|
|
The combination of steep identification
functions AND good discrimination only at category boundaries |
categorical perception
|
|
|
• Create a continuum by varying both F1
and F2 to go from /I/ to /E/ to /ae/. – Same type of id. and discrimination tasks as for consonants, but very different results – identification function NOT steeply sloping – Fairly good discrimination across the whole continuum. – NOT categorical perception --> continuous perception. |
explain vocal experiments
|
|
|
way to explain categorical
perception |
Motor Theory of Speech Perception
|
|
|
we identify phonemes through
access to the underlying motor gestures that produced them, not directly through acoustic features (innate and special for humans). |
Motor Theory of Speech Perception
|
|
|
invariance exists (just need to do more
research) and speech system developed on existing auditory sensitivities. |
Alternative Theory: Acoustic Invariance
|
|
|
Support: infants apparently born with
categorical perception. • Support: sort of avoids problem of variability (gestures are consistent?). • Problem: some non-human animals seem to have categorical perception. • Alternative Theory: Acoustic Invariance – invariance exists (just need to do more research) and speech system developed on existing auditory sensitivities. |
alternative to motor theory
|
|
|
steeper slope
|
stop
|
|
|
gentler slope
|
vowel
|
|
|
are things that can change alot
|
dipthongs
|
|
|
perceptions drives production --> phonemes --> word
|
perceptions drives production -->
|
|
|
uses natural speech synthesis and higher storage space
|
cognitive synthesis
|
|
|
steeper the slope the
|
faster articulators moving
|
|
|
computer speech programing
|
formant synthesis
|
|
|
very unnatural sounding
|
isolated
|
|
|
alters input
|
cochlea
|
|
|
doesn't drop dramatically
|
pitch
|
|
|
relates to pronunciation and how it changes to syllable boundaries
|
duration
|
|
|
smaller bone in the human body
|
stapes
|
|
|
fewer HCs designated to higher frequencies than low
|
explain nonlineary in hearing
|
|
|
f3 and f4 on coch merge together; see f1, f2-f4 together, then f5
|
what is a big difference b/w coch and spectro?
|
|
|
what is poor for formant synthesis?
|
fricatives and stops
|
|
|
___ db loss from ossicles missing
|
30 db loss
|
|
|
____ db loss of SA from oval window to TM
|
25 db loss
|
|
|
____ db loss b/c of stapedius
|
5 db loss
|
|
|
tm=.85cm2
ow=.03cm2 |
surface area of tm and ow
|
|
|
higher sa lower pressure
lower sa higher pressure |
realtionship b/w sa and p
|