![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
22 Cards in this Set
- Front
- Back
|
The degree to which a statistical model represents the data collected |
The fit of the model |
|
|
A hypothetical value that can be calculated for any data set (not necessarily actually observed in the data set) |
The mean value |
|
|
The deviance between the observed data and the model |
The error in the model (the bigger the number, the poorer the fit of the model) |
|
|
Calculate the magnitude of deviance |
Subtract the mean value from each of the observed values. (For example, in a problem where the mean amount of friends for a lecturer is 2.6. And lecturer 1 had only 1 friend, so the difference is x1 - x = 1 - 2.6 = - 1.6. Our model OVERESTIMATES his popularity, it predicts he will have 2.6 friends but he only has 1) |
|
|
A good measure of how well the mean represents the data (how well our model fits the data) |
Sum of squared error |
|
|
Variance |
Sum of squared error (SS) / sample size minus 1 (n - 1) |
|
|
Standard deviation |
Variance gives an answer in united squared (because each error was squared in the calculation)
SO, the square root of the variance is needed. This is called the Standard Deviation - a measure of how well the mean represents the data. |
|
|
Standard deviation: Size |
Small standard deviations (relative to the value of the mean itself) indicate that data points are close to the mean
A large standard deviation (relative to the mean) indicates that the data points are distant from the mean |
|
|
If we're looking at how well a model fits the data, then we generallly look at deviation from the model, we look at the sum of squared error |
deviation = sum (observed - model)2 |
|
|
A graph of how many times each score occurs
(A graph plotting values of observations on the horizontal axis, with a bar showing how many times each value ocurred in the data set) |
Frequency Distribution / Histogram |
|
|
The score that occurs most frequently in the data set |
The mode |
|
|
The normal distribution |
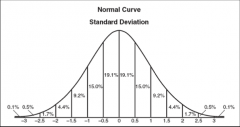
|
|
|
Frequency Distribution: Symmetry |
Skewness. Positively skewed - the frequent scores are clustered at the lower end and the tail points towards the higher / more positive scores Negatively skewed - the frequent scores are clustered at the higher end of and the tail points towards the lower, more negative scores |
|
|
Frequency Distribution: Pointyness |
Kurtosis: the degree to which scores cluster in the tails of the distribution.
Platykurtic - many scores in the tails, and is therefore flat
Leptokurtic - thin in the tails, so look quite pointy |
|
|
Standard Deviation & Shape of Distribution |
As the standard deviation gets larger, the distribution gets wider |
|
|
Probability distributions |
Statisticians have identified several common distributions. For each one, they have worked out mathematical formulae that specify idealised versions of these distributions, called Probability Distributions. From one of these distributions, it is possible to calculate the probability of getting particular scores based on the frequencies with which a particular score occurs in a distribution with these common shapes. |
|
|
Z Scores |
Any data set (even if it has a mean of 567 and an SD of 52.98!) can be converted into a data set that has a mean of 0 and a standard deviation of 1 |
|
|
Z Scores: Equation |
First, to centre the data at zero, we take each score and subtract it from the mean of all scores. Then, we divide the resulting score by the standard deviation to ensure all data have a standard deviation of 1
z = score - (mean of scores) / SD |
|
|
95% of z scores lie between |
- 1.96 and 1.96 |
|
|
99% of z scores lie between |
- 2.58 and 2.58 |
|
|
99.9% of z scores lie between |
- 3.29 and 3.29 |
|
|
How well a particular sample represents the population |
Standard Error |