![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
93 Cards in this Set
- Front
- Back
|
What is the mathematical expression of Classical Test Theory?
|
Test Score X = obtained Score T + Random Error
|
|
|
What is the Standard Error of Measurement?
|
The standard deviation of errors around an individual OBTAINED SCORE around the true score. |
|
|
What is a con to having a highly reliable test?
|
It reduces sensitivity because the distribution is too leptokurtic.
|
|
|
What is the general family of statistical methods used in Inferential Statistics? |
GENERAL LINEAR MODEL |
|
|
What are examples of the General Linear Model tests? |
t-Test ANOVA/ANCOVA Regression Factor Analysis Cluster Analysis Linear Discriminant Function Structural Equation Modeling Multidimensional Scaling |
|
|
What is the major advantage of Item Response Theory?
|
Observed Scores and True Scores are not test dependent (as in classical test theory). Instead, scores are ITEM DEPENDENT.
In other words, IRT is focused on item-level characteristics. |
|
|
What is the simplest IRT model? |
The Rasch Model: Because it is only concerned with item thresholds and uses Item Characteristic Curves to do so. |
|
|
How does an Item Characteristic Curve work? |
It compares the probability of a correct answer against an underlying trait or ability. This then allows items to be examined for discrimination and difficulty levels. |
|
|
What do you get when you combine the Item Characteristic Curves of a measure? |
A Test Characteristic Curve |
|
|
What does a Test Characteristic Curve provide? |
Direct analysis of underlying ability. |
|
|
What is probability? |
The ratio of outcomes over an infinite number of trials. |
|
|
What is Bayes' Theorem? |
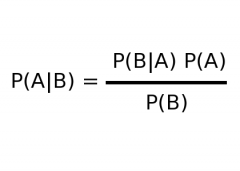
|
|
|
What is variance?
|
Standard Deviation squared.
It is the average of the squared differences of each observation from the mean of a distribution. |
|
|
What is the classical definition on of reliability? |
The ratio of true variance to total variance.
It acts as a measure of how much a measure is affected by random error. |
|
|
Name the 5 main types of reliability |
Test-retest Alternate forms Split-half Internal consistency Interrater |
|
|
What is the purpose of test-retest reliability? |
TEMPORAL STABILITY. To account for error variance that could affect consistency of test performance. There is always a trade off between sensitivity and test-retest reliability. |
|
|
What is the purpose of Alternate Forms reliability? |
CONSISTENCY ACROSS FORMS. To assess content sampling and minimize error variance due to practice effects and to capture stability over time. |
|
|
What is the purpose of split-half reliability? |
To evaluate the internal consistency (i.e., content sampling) of a test in a single administration. |
|
|
What is the Spearman-Brown formula used for? |
In split-half reliability measures, the formula is used to determine the effect of lengthening a measure.
LENGTHENING HELPS IMPROVE INTERNAL CONSISTENCY BUT NOT STABILITY (i.e., test-retest reliability). |
|
|
What is the purpose of establishing Internal Reliability? |
TO DETERMINE IF ITEMS OF A TEST ALL ASSESS THE SAME COGNITIVE DOMAIN.
Assesses two sources of error: Content sampling Heterogeneity of the domain being assessed |
|
|
Does item heterogeneity or homogeneity improve internal reliability? |
Homogeneity improves reliability, but for it to be useful, the homogeneity of a test has to match the homogeneity of the construct being measured. |
|
|
What tests are used to establish Internal reliability? |
Kuder Richardson 20 for dichotomous items Cronbach's Alpha for Likert-type items |
|
|
Name the various types of Validity
|
Content Validity
Criterion Validity (Predictive and Concurrent) Construct Validity (Convergent and Discriminant) |
|
|
What is content validity? |
The degree to which a test measures all facets of a domain of interest.
Not expressed mathematically, but is established by an 'expert' panel. |
|
|
What is predictive validity? |
How well a test predicts a predetermined criterion
|
|
|
What is concurrent validity? |
How well a test correlates with a current established criterion (i.e., other validated tests measuring the same construct)
Can be expressed as a coefficient. The math for predictive and concurrent validity is the same. |
|
|
What is construct validity? |
How well a test measures a theoretical construct or trait. |
|
|
How do content and construct validity differ? |
Content validity is concerned with how well items of a test sample the domain of interest.
Construct validity is concerned with how well those items actually measure the domain of interest. |
|
|
What are convergent and discriminant validity? |
Forms of construct validity. Convergent validity is different items or tests that are supposed to correlated do. Discriminant validity is the opposite. |
|
|
What tool is used to establish construct validity? |
Multi-trait Multi-Method Matrix |
|
|
Define positive predictive power |
The proportion of the time we are correct when we say a disease is present based on a positive test result.
PPP=True Positive/(True Positive + False Positive)
Row-based index: PPP = A/(A+B) |
|
|
Define negative predictive power |
The proportion of the time we are correct when we say someone does not have a disease based on a negative test result.
NPP= True Neg./(True Neg. + False Neg.)
Row-based index: NPP= D/(D+C) |
|
|
Are positive and negative predictive power affected by the base rate & prevalence of a condition? |
YES! Unlike Sensitivity and Specificity, which are fixed properties of a test. |
|
|
Define Sensitivity |
The number of people who DO have a disease that are correctly classified as having the disease by a test.
MINIMIZES FALSE NEGATIVES but may lead to more false positives |
|
|
Define Specificity
|
The number of people who do NOT have a disease that are correctly classified as not having the disease by a test.
MINIMIZES FALSE POSITIVES but may lead to more false negatives |
|
|
Define Positive Liklihood Ratio |
A combination of sensitivity and specificity into a single index that indicates the ODDS THAT A POSITIVE TEST RESULT MEANS A PERSON HAS THE DISEASE For example, if the ratio is 3.0, then it means the test result is three times more likely to be because the person has the disease than from someone who does not have the disease. Column-based index |
|
|
Define Negative Liklihood Ratio |
A combination of sensitivity and specificity into a single index that indicates the ODDS THAT A NEGATIVE TEST RESULT MEANS A PERSON DOES NOT HAVE THE DISEASE. For example, if the ratio is 3.0, then it means a the test result is three times more likely to have come from someone without the condition than someone with the condition. Column-based index |
|
|
What happens if +/- Liklihood Ratios approach a value of 1? |

Then your test is no better than random guessing. |
|
|
Which are characteristics of the test itself: Sensitivity, Specificity, Liklihood Ratios, and/or Predictve Powers?
|
Sensitivity, Specificity, and Liklihood Ratios
Predictive powers are NOT, but rather are properties of specific test scores in specific contexts.
|
|
|
Does good Sensitivity and Specificity guarantee a clinically useful test? |
No! No! No! NEVER! No! Not. Ever. No! No!
This is because they are developed at the group level, and we are concerned with how tests apply to INDIVIDUALS. |
|
|
What classification method is used to classify INDIVIDUALS rather than groups? |
Positive and Negative Predictive Power |
|
|
What value do positive and negative predictive power need to exceed in order for a test to be useful? |
.50 .50 is chance level; Less than .50 means you will be wrong more than you are correct. |
|
|
Does positive predictive power increase or decrease with increased prevalence of a disease? |
INCREASE. Negative predictive power will simultaneously decrease. |
|
|
What is the mathematical expression of prevalence? |
Prevalence = (True Pos. + False Neg.)/N |
|
|
What is the danger of using data from test validity studies to calculate PPP and NPP? |
Because the prevalence of diseases in validity studies is often 50% (artificially high) in order to facilitate other statistical comparisons (e.g., case vs. control analyses)
OR! 50% may be artificially low, and lead to false negatives, if you are in a setting where 100% of your sample has a condition of interest (e.g., 100% of patients in a severe TBI clinic have a TBI) |
|
|
What does the area under a ROC curve represent? |
Overall accuracy of a test (i.e., correctly classified portion of a sample). |
|
|
What is plotted on the y-axis of a ROC curve? The x-axis? |
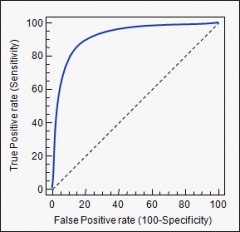
y-Axis is True Positive Probability
x-Axis is False Positive Probability |
|
|
What does the slope of any point of a ROC curve represent? |
The POSITIVE LIKLIHOOD RATIO |
|
|
Do reliability coefficients need to be squared in order to determine variance? |
NO! The coefficient is the variance. Only correlation coefficients need to be squared in order to obtain variance. |
|
|
What are the minimal acceptable standards for reliability coefficients? |
.80 to .90 for internal consistency .70 or higher for test-retest |
|
|
What types of tests tend to have the highest reliability?
|
Verbal tests |
|
|
What is the standard error of estimation? |
The standard error surrounding estimated true scores. |
|
|
What is an estimated true score? |
It corrects bias in an observed score by regressing it to the mean of the population.
This is necessary since observed scores above the mean are likely to be higher than true scores (and vice versa for observed scores below the mean). |
|
|
How is an estimated true score calculated? |
Estimated True Score (t') =
Mean Test Score+[test reliability (Observed Score-Mean Test Score)]
or
t'=test reliability(z score) |
|
|
What is the standard error of prediction? |
The likely range of observed scores expected upon retest using an alternative form. |
|
|
What types of tests produce stupidly high reliability coefficients in split-half reliability?
|
Speed tests |
|
|
If a number of patients are at or near the lowest possible score of the test, then what problem is the test distribution said to have?
|
A High Floor. More easier items are needed. |
|
|
If a test has a low ceiling, then what type of scores will patients produce? |
Scores close to the highest possible score on the test. More difficult items are needed. |
|
|
For a test to best differentiate between groups, what percentage of items should most people get correct? |
50% |
|
|
What is Type I Error? |
Alpha error: Indicating that a condition is present when it is not |
|
|
What is Type II error? |
Beta error: Indicating that no condition is present when it is. |
|
|
Describe the Deficit Measurement Model. |
The measurement of impairment when an examinee’s performance is significantly below an actual or estimated previous level of functioning. |
|
|
What comparison standards are used in deficit measurement? |
Normative comparison standards; Individual comparison standards; Criterion comparison standards |
|
|
What are the two primary types of normative comparison standards? |
Species Comparison & Population Averages |
|
|
How do species comparison standards work? |
They look at capacities shared by all healthy members of a species (i.e., language). A lack of these capacities is called a pathognomonic sign. |
|
|
How do comparisons to population averages work? |
Compares individual performances against the distribution of performances for healthy individuals in a population to identify deficient performances.
[If you don't know this, then you fail at neuropsychology...forever.] |
|
|
What are key weaknesses of population normative comparisons? |
It only tells you how the individual compares to the average population, it does not allow you to identify a key deficit in an individual. |
|
|
Describe individual comparison standards. |
Compares individuals to their premorbid performance. |
|
|
What is a criterion referenced comparison standard? |
A score on a pre-specified standard that differentiates between those who pass or fail. The goal is not to look at differences between examinees.
Focused on everyone achieving MASTERY or the SAME LEVEL OF PERFORMANCE. |
|
|
What does the Standard Error of Measurement quantify? |
Index of the amount of error expected in obtained scores due to the unreliability of a test. |
|
|
What is the advantage of a test with High Sensitivity? |
A NEGATIVE result rules OUT the diagnosis
SN-NOUT
|
|
|
What is the advantage of a test with High Specificity? |
A POSITIVE result rules IN a diagnosis SP-PIN |
|
|
What is the mathematical expression of Sensitivity? |
Sn = True Positives/(True Positives+False Negatives)
or
Sn = A/(A+C) |
|
|
What is the mathematical expression of Specificity? |
Sp = True Negatives/(False Positives + True Negatives)
or
Sp= D/(D+B) |
|
|
What is another name for pre-test probability? |
Prevalence |
|
|
What is the mathematical expression of disease prevalence (i.e., pre-test probability)? |
Prevalence = (True positives + False Negatives)/(True Pos. + False Pos.+ True Neg. + False Neg.)
OR
Prevalence = (A+C)/(A+B+C+D)
OR
Prevalance = People who actually have the condition/The entire population
|
|
|
What is the mathematical expression of the Liklihood Ratio for a positive result? |
LR+ = (Sensitivity)/(1-Specificity) |
|
|
What is the mathematical expression of the Liklihood Ratio for a negative test result? |
LR- = (1-Sensitivity)/(Specificity) |
|
|
How are the pretest odds of a condition calculated? |
Pretest odds = (Prevalence)/(1-Prevalence) |
|
|
What is the difference between Pretest Probability and Pretest Odds?
|
Probability: the proportion of people with a condition
Odds: a ratio of two probabilities. In this case, the the ratio is (probability of having a condition):(probability of not having a condition) |
|
|
What is the mathematical expression of pretest odds? |
Pre-test Odds = (prevalence)/(1-prevalence)
|
|
|
What is post-test odds for a positive test result equal to(i.e., synonymous with)? |
Positive Predictive Value |
|
|
What is the practical definition of post-test odds? |
The added value of a test result over pre-test probability (i.e., prevalence). Can be positive or negative value.
|
|
|
What is the mathematical expression of post-test odds given a positive result? |
Post-test odds = (Pre-test odds) X (LR+) |
|
|
What is the mathematical expression of post-test probability for a positive result? |
Post-test probability = (Post-test odds)/(Post-test Odds + 1) |
|
|
What is the mathematical relationship between probability and odds? |
Probability = (odds)/(1+ odds) Odds = (probability)/(1-probability) |
|
|
How is parametric statistical modeling used to define impairment? |
Compares performance relative to normative population through an extrapolation of the central limit theorem. BASED ON NORMATIVE COMPARISON STANDARD |
|
|
How is Bayesian statistical modeling used to define impairment? |
Through the use of a probability model and corrective variables to improve the accuracy of prediction. BASED ON INDIVIDUAL COMPARISON STANDARD. |
|
|
How does choosing lower cut offs (i.e., -1.5 SD vs. -1 SD) affect specificity? |
A lower cut off will increase specificity (i.e., less false positives but more false negatives). |
|
|
How does choosing a higher cut score (i.e., -1 instead of -1.5) affect sensitivity? |
Sensitivity will increase (i.e., a negative test result will rule a disease out), but this results in more false positives. |
|
|
When examining discrepancies between scores (e.g., VCI vs. PRI), is it more meaningful to look at statistical significance or base rates for the difference? |
BASE RATES! A statistically significant difference may still occur in 25+% of the population, meaning it is common. |
|
|
Are patient's with low IQ more likely to have more variability in their scores? |
NO, but they do tend to have more scores that normally fall in the impaired range.
In contrast, those with high IQ tend to have greater variability in scores, but less that fall in the impaired range. |
|
|
TRUE OR FALSE: Pediatric tests always have the same psychometric properties across age groups. |
FALSE
Contributors to this problem include:
Different start/stop points on tests; Remarkable variability due to developmental differences; Occasionally limited normative sample sizes; |