![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
46 Cards in this Set
- Front
- Back
|
Co implementuje jądro SO? |
- Szeregowanie zadań i synchronizacja procesów: przydział czasu procesorów i przestrzenie adresowej - system plików: wymiana, obsługa in/out - gniazda i sygnały: protokoły obsługi sieci |
|
|
Jakie SO ma interfejsy z otoczeniem?
|
powłoka(shell) np bash, sh(powłoka Bourne'a) |
|
|
Jakie znaczenie ma wiedza z zakresu SO?
|
Pozwala na lepsze zrozumienie działania komputera. Bez tej wiedzy komunikacja z jadrem za pomocą powłoki byłaby niemożliwa. Pozwala na dalsze rozwijanie systemów komputerowych. |
|
|
Które elementy architektury sprzetowej komputera bezpośrednio sterują SO? |
zegar/licznik, kontrolery przerwań |
|
|
Wymienić stany procesów i przedstawić cykl tych zmian. |
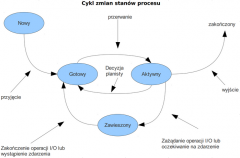
Nowy, Gotowy, Aktywny, Zawieszony, Zakończony |
|
|
Podaj def złożoności obliczeniowej algorytumo operacyjnego. |
funkcja podająca zależność między czasem zużywanym przez ten algorytm na skonstruowanie rozwiązania dla konkretnego problemu, a rozmiarem problemu. IN: wilkość problemu OUT: zas obliczeń. |
|
|
Problem decyzyjny to. |
uporządkowany zbiór parametrów z których nie wszystkie muszą mieć ustalone wartości, dotyczących zbioru zasobów, zbioru zadań i kryterium działania. |
|
|
notacja trójpolowa |
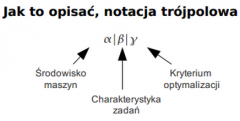
|
|
|
Podać przykład problemu szeregowania zadań o otwartej(nieokreślonej) złożoności obliczeniowej - przedstawić go w postaci trójpolowej.
|
znalezienie czasu wykonania wszystkich zadań na trzech procesorach w systemie otwartym(open shop) O3||Cmax |
|
|
Jak radzimy sobie z NP-trudnością
|
- wielomianowe algorytmy o gwarantowanej dokładności względnej - dokładne algorytmy pseudo-wielomianowe - algorytmy dokładne, szybkie tylko w średnim przypadku - heurystyki wyszukujące(np. tabu search, algorytmy genetyczne) - dla małych rozmiarów danych - wykładnicze przeszukiwanie wyczerpujące |
|
|
Zdefiniować problem pakowania i określić jego złożoność obliczeniową
|
Przykład problemu NP-zupełnego (niewielomianowego) -> złożoność nie wielomianowa trudna do określenia znanymi nażędziami matematycznymi. problem pakowania (w zagadnieniu przydziału pamięci) n elementów o rozmiarach ai, przyjmujemy, że ten rozmiar jest od (0 do 1), elementy te mamy włożyć do pudełek o jednostkowych pojemnościach tak, aby liczba pudełek była jak najmniejsza. Aproksymacyjne algorytmy pakowania: – według kolejności (FF – first fit), wkładanie do pudełka o możliwie najmniejszym numerze – według dopasowania elementów (BF – best fit), dopasowanie do pudełka w którym została jak najmniejsza przestrzeń – dopasowanie uporządkowanych elementów (FFD – first fit decreasing), wersja FF, nierosnące wartości elementów – najlepsze dopasowanie uporządkowanych elementów (BFD – best fit decreasing), wersja BF, nierosnące wartości elementów |
|
|
Zdefiniować procosory uniform
|
procesoy jednorodne - mogą mieć różną szybkość, ale stosunki czasu wykonania zadania są niezależne od maszyn |
|
|
Przykład zastosowania procesorów uniform
|
szeregowanie zadań o znanych czasach do wykonania na maszynie o trzech procesorach uniform |
|
|
Przydział listowy w podsystemie plików - na czym polega, zalety, wady.
|
(ang. Linked allocation) def1 plik jest listą powiązanych bloków, dowolnie rozproszonych w dostępnej przestrzeni dyskowej. def2 polega na przechowywaniu danych za pomocą wielu spójnych bloków które sa połaczone za pomoca wskaźników w listę. Zalety: - nie ma problemu z fragmentacji zewnętrznej i wynikających z niej wad metody przydziału - łatwa realizacja dostępu sekwencyjnego Wady: - problem realizacji dostępu swobodnego (bezpośredniego), przejście do poprzedniego bloku wymaga rozpoczęcia przeglądania listy bloków od początku - konieczność pamiętania wewnątrz bloku wskaźnika do bloku następnego - utrata jednego bloku pociąga za sobą stratę wszystkich następnych |
|
|
Podać idee działania pamięci asocjacyjnej.
|
asocjacyjną pamięcią podręczną (ang. fully associative cache memory). W przypadku takiej pamięci podręcznej adres fizyczny dzielony jest na dwie tylko części: młodszą, określającą offset bajtu w ramach jednej linii cache, oraz starszą, będącą tagiem umożliwiającym odszukanie linii cache buforującej potrzebny fragment pamięci operacyjnej. |
|
|
Co to jest fragmentacja wewnętrzna?
|
internal fragmentation - straty pamięci powodowane nieużytkami występującymi w ostatnich blokach plików lub w końcowych stronach programu. |
|
|
Co to jest fragmentacja zewnętrzna?
|
external fragmentation - straty pamięci powodowane nieużytkami, czyli dziurami (holes) występującymi na dysku lub w pamięci operacyjnej między poszczególnymi blokami informacji. |
|
|
Opisać rodzaje gniazdek "sockets"(w systemie Unix). |
◦ Strumieniowe – umożliwiają dwukierunkowe i niezawodne przekazywanie sekwencyjnych strumieni danych, przy przesyłaniu żadne dane nie giną ani nie są podwajane nie ma również ograniczeń na rekordy. Gniazdko to występuje w domenie Internet w której używa się protokołu TCP. Gniazdko to występuje także w domenie UNIX-a, potoki implementuje się jako pracy komunikacyjnych gniazdek strumieniowych ◦ Pakietów sekwencyjnych – te gniazdka tworzą strumienie danych tak jak w gniazdkach strumieniowych lecz stosuje się tu ograniczenia rekordów – rozdaj gniazdek używanych w sieci Xerox ◦ Datagramów – takie gniazdka przesyłają w każdym kierunku komunikaty mające zmienną długość, nie gwarantują że komunikaty dotrą w takim samym porządku, w którym zostały wysłane, że nie będą powtórzone, ani też że nadejdą w ogóle – ten rodzaj gniazdek jest zaimplementowany w domenie sieci Internet przez protokół UDP ◦ Surowe – te gniazdka umożliwiają procesom bezpośredni dostęp do protokołów implementujących inne rodzaje gniazdek – na przykład w domenie Internetu jest możliwe osiągnięcie protokołu TCP oraz IP, jak również protokołu sieci Ethernet, ta właściwość jest przydatna przy opracowywaniu nowych protokołów. |
|
|
Podaj schematyczne współdziałanie funkcji fork, execeve, wait i exit w systemie unix’owym. |
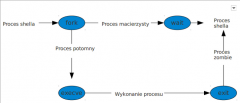
|
|
|
co to jest martwy punkt, wyjaśnij |
Deadlock - załóżmy, że w systemie operacyjnym są 2 procesy: proces A i proces B. A potrzebuje ingerencji w dane dysku, następnie chce wykonać obliczenia, a potem wydrukować wyniki. B najpierw chce coś wydrukować, potem wykonać obliczenia, a następnie ingerować w dane dysku. Systemy operacyjny ma jedną jednostkę dyskową i jedną drukarkę. Procesy A i B zaczynają się i otrzymują kwant czasu. Proces A otrzymuje dysk, a proces B drukarkę, obydwa procesy trzymają to co otrzymały aż skończą swoje działanie. Nie mogą otrzymać tego czego potrzebują w dalszej części swojego działania (wzajemnie się blokują) i system się zawiesza |
|
|
Podaj warunki konieczne zaistnienia deadlocka/martwego punktu
|
- Wzajemne wykluczenie - w danym czasie tylko jedno zadanie może z niego korzystać; w ogólności warunkiem do zakleszczenia jest też sytuacja w której do zasobu jest możliwy jednoczesny równoległy dostęp wielu zadań, lecz liczba jednocześnie zadanych żądań do zasobu jest większa od liczby maksymalnych równoległych dostępów do zasobu, które mogą zostać obsłużone; - Trzymanie zasobu i oczekiwanie - zadanie utrzymuje jeden z zasobów, ale do ukończenia pracy niezbędne jest także zaalokowanie zasobów innego typu; - Cykliczne oczekiwanie - zadania w taki sposób żądają zasobów, że powstaje cykliczny graf skierowany; - Brak wywłaszczania z zasobu - zadania dobrowolnie nie rezygnują z przydzielonych im zasobów; zwolnienie zasobów możliwe jest po zakończeniu zadania |
|
|
Podać ideę algorytmu dla rozwiązania problemu 5 filozofów. Jaki zastosowano w tym algorytmie sposób synchronizacji? |
Rozwiązanie przy użyciu hierarchii zasobów Proste rozwiązanie jest osiągalne poprzez częściowe uporządkowanie lub ustalenie hierarchii dla zasobów (w tym wypadku widelców) i wprowadzenie zasady, że kolejność dostępu do zasobów jest ustalona przez ów porządek, a ich zwalnianie następuje w odwrotnej kolejności, oraz że dwa zasoby niepowiązane relacją porządku nie mogą zostać użyte przez jedną jednostkę w tym samym czasie.W tym przykładzie oznaczmy zasoby (widelce) numerami od 1 do 5 – w ustalonym porządku – oraz ustalmy, że jednostki (filozofowie) zawsze najpierw podnoszą widelec oznaczony niższym numerem, a dopiero potem ten oznaczony wyższym. Następnie, zwracając widelce, najpierw oddają widelec z wyższym numerem, a potem z niższym. W tym wypadku, jeśli czterech filozofów jednocześnie podniesie swoje widelce z niższymi numerami, na stole pozostanie widelec z najwyższym numerem, przez co piąty filozof nie będzie mógł podnieść żadnego. Ponadto, tylko jeden filozof ma dostęp do widelca z najwyższym numerem, więc będzie on mógł jeść dwoma widelcami. Gdy skończy, najpierw odłoży widelec z najwyższym numerem, a następnie z niższym, umożliwiając kolejnemu filozofowi zabranie drugiego sztućca.Właśnie takie rozwiązanie swojego zadania proponował Dijkstra.Pomimo że rozwiązanie hierarchii zasobów zapobiega zakleszczeniom, nie zawsze jest ono praktyczne, zwłaszcza gdy lista wymaganych zasobów nie jest z góry znana. Na przykład, jeśli jednostka zajmuje zasoby 3 i 5, po czym stwierdza, że potrzebuje zasobu 2, musi zwolnić 5, a następnie 3, aby zająć 2, a następnie ponownie zająć 3 i 5 (w tej kolejności). Programy komputerowe, które uzyskują dostęp do dużej liczby rekordów w bazie danych, nie działałyby wydajnie, gdyby przed uzyskaniem dostępu do nowego wiersza musiały zwalniać dostęp do wierszy z wyższymi numerami, przez co metoda jest niepraktyczna dla takiego zastosowania.Jest to często najbardziej praktyczne rozwiązanie dla rzeczywistych problemów informatyki; poprzez ustalenie stałej hierarchii blokad oraz wymuszanie porządku nabywania blokad, można zapobiec temu problemowi. |
|
|
co to jest relokacja dynamiczna? Jak jest ona implementowana w systemach komputerowych?
|
program napisany jest tak aby być całością:zaczyna się adresem 0 czyli bazą(base), zmienne i procedury adresowane są względem bazy czyli odległość miedzy bazą a jakimś bitem to offset(adres danej procedury to base+offset). relokacja polega zatem na przeniesieniu całości programu w inne miejsce a w momencie odwołania się do konkretnych danych dodajemy to przesunięcie(offset pozostaje bez zmian tylko basa sie zmienia). |
|
|
Algorytm Mc Naughtona -czego dotyczy -schemat działania -złożoność -przykład |
Szeregowanie zadań podzielnych, na procesorach identycznych, zadania niezależnych, w celu minimalizacji Cmax.Cmax*=max( max(t[i]), (1/m)Et[i] ) (E to duża sigma, suma)
1.Rozpocznij wykonywanie dowolnego zadania na dowolnym procesorze w chwili t=0. 2.Wybierz dowolne nie uszeregowane jeszcze zadanie i rozpocznij jego wykonywanie na tym samym procesorze w chwili zakończenia wykonywania poprzedniego zadaaia. 3.Powtarzaj krok 2 do chwili gdy wszystkie zadania zostaną uszeregowane lub t=Cmax*. 4.Część zadania pozostającą do wykonywania po ociągnięciu Cmax* przydziel do innego wolnego procesora, rozpocznij jej wykonanie od chwili t=0. Wróć do kroku 2.
Optymalność algorytmu wynika z faktu że Cmax* jest z góry znane, złożoność to:O(n), gdyż każde zadanie jest rozpatrywane raz a czas wykonywania jest stały. |
|
|
Algorytm Muntza Coffmana(nazywany przez Draba również jako Gantta)-czego dotyczy-schemat działania-złożoność-przykład
|
Szeregowanie zadań podzielnych na procesorach identycznych, dla dowolnej liczby procesorów zadania tworzą graf typu lasu, dla dwóch procesorach zadań tworzących dowolny graf, w celu minimalizacji Cmax.B=m/a (gdzie B-beta, m -liczba proc., a-liczba zadań o najwyższym poziomie)
1.Wyznacz poziomy nie wykonanych zadań. 2.Przydziel zadania o najwyższym poziomie do procesorów, przy czym jeśli zadań tych jest więcej niż procesorów - przydziel każdemu zadaniu B mocy obliczeniowej procesorów. 3. Zasymuluj wykonywanie przydzielonych zadań do chwili, w której zadanie o niższym poziomie byłoby wykonywane szybciej(większe B) niz zadanie o poziomie wyższym. 4. Wracaj do 1 aż wszystkie zadania zostaną wykonane. 5. Zastosuj Algorytm Mc Naughtona w celu uszeregowania optymalnego.
Złożoność wynosi O(n^2). Wynika z faktu iż graf o n wierzchołkach może mieć O(n^2) łuków. |
|
|
Algorytm Hu-czego dotyczy-schemat działania-złożoność-przykład
|
Szeregowanie zadań o jednostkowych czasach wykonywania, na procesorach identycznych, dla zadań tworzących digraf typu antydrzewo, dla zadań tworzących las antydrzewo tworzymy puste zadanie będące następnikiem wszystkich drzew grafu, w celu minimalizacji Cmax.
1.Okreś poziom zadań. 2.Jeśli liczba zadań bez poprzedników jest mniesza lub równa m: 2.TRUE to przydziel tym zadaniom procesy. 2.FALSE to wybierz spośród nich m zadań o najwyższych poziomach i przydziel im procesory(spośród zadań o równym poziomie wybór jest dowolny) 3. Usuń wybrane zadania z grafu. 4. Powtarzaj krok 2 aż wszystkie zadania zostaną wykonane.
Złożoność wynosi O(n), co wynika z liczby łuków w grafie typu drzewa. |
|
|
Algorytm przydziału etykiet do zadań w grafie
|
Przydzielaj etykiety kolejno do zadań których wszyscy potomkowie mają już przydzielone etykiety. |
|
|
Algorytm Coffmana Grahama-czego dotyczy-schemat działania-złożoność-przykład |
Szeregowanie zadań o jednostkowych czasach wykonywania, na dwóch procesorach identycznych, dla zadań tworzących dowolny graf, w celu minimalizacji Cmax. 1.Przydziel etykiety wszystkim zadaniom. 2.Jeżeli jakiś procesor jest wolny w danej chwili to przydziel do niego zadanie, którego wszystkie poprzedniki zostały wykonane i które ma największą etykietę spośród zadań jeszcze nie przydzielonych. 3.Powtarzaj krok 2 aż wszystkie zadania nie zostaną przydzielone.
Złożoność wynosi O(n^2), Wynika z faktu iż graf o n wierzchołkach może mieć O(n^2) łuków. |
|
|
Algorytm Baera-czego dotyczy-schemat działania-złożoność-przykład
|
Szeregowanie zadań o jednostkowych czasach wykonywania, na dwóch procesorach jednorodnych, dla zadań tworzących digraf typu antydrzewo, w celu minimalizacji Cmax.
1.Określ poziomy zadań, licznik zadań q=n, k1=k2=0, 2.Przydziel dostępne w chwili k1 zadanie o najwyższym poziomie do procesora P1, q-=1, k+=1. 3.Jeśli są dostępne zadania w chwili k2, to przydziel jedno z nich o najwyższym poziomie do procesora P2, q-=1, k2+=2. 4.Jeśli są dostępne zadania w chwili k1, to przydziel jedno z nich o najwyższym poziomie do procesora P1, q-=1, k1+=1. 5.Jeśli q>1 to przejdz do 2.6.Przydziel ostatnie zadanie do procesora P1, Cmax*=k1+1.
Złożoność wynosi O(n), ponieważ każde zadanie jest rozpatrywane tylko raz. |
|
|
Algorytm Conway, Maxwell, Miller(SPT)-czego dotyczy-schemat działania-złożoność-przykład
|
Szeregowanie zadań zależnych i niepodzielnych, dla procesorów identycznych, w celu minimalizacja średniego czasu przepływu F.
1.Przydziel m najdłuższych zadań do m procesorów. 2.Usuń przydzielone zadania ze zbioru. 3.Jeśli nie wszystkie zadania zostały przydzielone -> 1 4.Dla każdego procesora uszereguj zadania według czasów wykonywania(od najmniejszego)
brak optymalnego rozwiązania 1<=(CmaxSPT*/Cmax*)<=2-(1/m)CmaxSPT* to długość uszeregowania SPTCmax* minimalna długość uszeregowania
Złożoność wynosi O(nlogn) |
|
|
Algorytm Bruno, Coffman, Sethi(RPT) -czego dotyczy -schemat działania -złożoność -przykład |
Szeregowanie zadań zależnych i niepodzielnych, dla procesorów identycznych, w celu minimalizacja średniego czasu przepływu F i minimalnej długość Cmax.
1. Przydziel zadania do poszczególnych procesorów według algorytmu LPT(przydziel aktualnie wolne procesory do najdłuższego zadania) 2. Dla każdego procesora uszereguj zadania według czasów wykonywania(od najmniejszego)
Złożoność wynosi O(nlogn) |
|
|
Algorytm Horna Sidneya-czego dotyczy-schemat działania-złożoność-przykład
|
Szeregowanie zadań niepodzielnych, na jednym procesorze, dla zadań tworzących graf typu drzewo, w celu minimalizacja średniego czasu przepływu F
1.Dla wszystkich zadań końcowych w grafie oblicz pj=tj/wj. 2.Dla zadania Zk, dla którego nie określono jeszcze współczynnika pk, a którego wszystkie następniki mają już określone wartosci tego współczynnika, podstaw pk=tk/wk. 3.Wyznacz zadanie Zi o minimalnej wartości współczynnika pi, będące bezpośrednim następnikiem zadania Zk. 4.Jeśli pk>pi, podstaw tk+=ti', wk+=wi', pk=tk/wk (ti'-,wi'-). Skreś zadanie Zi z listy bezpośredni następników Zk. Idz do 3 5.Jeśli nie wszystkim zadaniom przydzielono współczynniki pj to przejdz do kroku 2. 6.Skonstruuj uszeregowanie optymalne dla wyjściowego grafu, wykonując zadania według współczynnika pj(od najmniejszego), przestrzegając ograniczeń kolejnosciowych.
Złożoność wynosi O(nlogn), ponieważ musiymy upożatkować zadania niemalejąco a złożonosc takiego uporzadkowania to O(nlogn) |
|
|
Algorytm Johnsona-czego dotyczy-schemat działania-złożoność-przykład
|
Szeregowanie zadań niepodzielnych, na dwóch procesorach, w przepływowym systemie obsługi, w celu minimalizacji Cmax.
1.Wybierz zadanie, dla któreych t1j<=t2j, Przydzielaj operacje tych zadań do odpowiednich procesorów w kolejności nie malejących wartości t1j. 2.Operacje pozostałych zadań przydzielaj do opowiednich procesorów według wartosci t2j(od największej)
Złożoność wynosi O(nlogn)Dla m>2 NP-zupełny. |
|
|
Algorytm Gareya Johnsona-czego dotyczy-schemat działania-złożoność-przykład |
Szeregowanie zadań o jednostkowych czasach wykonywania i niezależnych, na dwóch identycznych procesorach, przy ograniczeniach zasobowych typu res..., w celu minimalizacji Cmax.
1.Utwórz graf G o n wierzchołkach odpowiadajacych zadaniom oraz krawędziach łączących dwa dowolne wierzchołki(zadania) Zi i Zj jeśli rl(Zi)+rl(Zj)<=ml, l=1,2,..,s. 2.Znajdź maksymalne skojarzenie E' w grafi G. 3.Skonstruuj optymalne uszeregowanie o długości Cmax*=n-|E'| wykonując równolegle zadanie odpowiadajace krawędziom wchodzącym w skład maksymalnego skojarzenia E', a pozostałe zadania pojedyńczo.
Złożonosc wynosi O(n^2.5) ponieważ złożonosci poszczególnych kroków wynosi 1-O(n^2), 2-O(n^2.5), 3-O(n). |
|
|
Algorytm Błażewicza-czego dotyczy-schemat działania-złożoność-przykład |
Szeregowanie zadań o jednostkowych czasach wykonywania i niezależnych, na identycznych procesorach, przy ograniczeniach zasobowych typu res1*1, w celu minimalizacji Cmax.
1.Podstaw t=0, k=0. 2.Przydziel w chwili t do pierwszego wolnego procesora dostępne zadanie Zj, dla którego r1(Zj)=1. Podstaw k+=1. 3.Jeśli k<=m1 i istnieją zadania o powyższych właściwościach idz do 2. 4.Przydziel do pozostałych wolnych procesów w chwili t, dostepne zadania, dla których r1(Zj)=0. Podstaw t+=1 i k=0. 5.Jesli są jeszcze zadania nie przydzielone idz do 2.
złożonosc wynosi O(n) ponieważ ropatczamy każde zadanie raz. |
|
|
Zdefiniowac algorytmy suboptymalne szeregowania listowego: HLFET, HLFNET, SCFET, SCLNET. Który z tych algorytmów jest najlepszy i jakie daje wyniki(średnio) w stosunku do optimum. |
HLFET(ang. Higest Levels First with Estimated Times) - przybliżony algorytm szeregwana zadań przydzielający priorytety.Priorytety według poziomów zadania. |
|
|
nieprzywłaszczalność |
zwolnienie zasobu może być zainicjowane jedynie przez proces dysponujący w danej chwili tym zasobem, |
|
|
przywłaszczalność |
zwolnienie zasobu może być zainicjowane przez czynnik zewnętrzny, nie tylko przez proces dysponujący w danej chwili tym zasobem. |
|
|
Semafor |
wprowadzony przez E. Dijkstra jest mechanizmem, dzięki któremu można realizować wzajemne wykluczenie. Semafor S jest zmienna, na której można wykonać tylko dwie operacje P(S) i V(S) oraz instrukcję inicjalizacji tej zmiennej. Operacje te, są niepodzielne, a inicjalizacja wykonywana jest poza instrukcjami współbieżnymi. Między P(S) i V(S) następuje wzajemne wykluczenie. Jeśli kilka zadań próbuje wykonać P(S) uda się to tylko jednemu. Pozostałe muszą czekać na swoja kolej. |
|
|
Round Robin |
(algorytm karuzelowy) to najprostszy algorytm szeregowania dla procesów w systemie operacyjnym, który nadaje każdemu procesowi odpowiednie przedziały czasowe, nie uwzględniając żadnych priorytetów. W związku z tym wszystkie procesy mają ten sam priorytet. W mechanizmach szeregowania używających priorytetów, często mechanizmu round robin używa się w stosunku do procesów o tym samym priorytecie. |
|
|
Zapisać program Dekkera za pomocą semaforów |
flag1 := false; |
|
|
Migotanie stron(szamotanie) |
jeśli wykorzystanie jednostki centralnej jest za małe to zwiększa się stopień wieloprogramowości wprowadzając do systemu nowy proces. Strony są zastępowane według globalnego algorytmu zastępowania stron, bez brania pod uwagę do jakich procesów należą. Jeśli proces wchodzi w nowa fazę działania i potrzebuje więcej stron, zaczyna wykazywać braki stron i powoduje utratę stron przez inne procesy. Te z kolei potrzebują tych stron i też wykazują braki, i znowu przyczynia się do odbierania stron innym procesom. Tak zachowujące się procesy muszą używać zewnętrznego urządzenia stronicującego, a jednocześnie opóźnia się kolejka procesów gotowych do wykonania. Wskutek oczekiwania procesów na urządzenie stronicujące zmniejsza się wykorzystanie procesora. Planista przydziału procesora dostrzega spadek wykorzystania procesora, więc zwiększa stopień wieloprogramowości. Nowy proces próbując wystartować zabiera ramki wykonywanym procesom, czym powoduje jeszcze więcej braków stron i jeszcze większą kolejkę do urządzenia stronicującego. Wskutek tego gwałtownie wzrasta czas efektywnego dostępu do pamięci. Nie można zakończyć żadnej pracy ponieważ procesy spędzają cały czas na stronicowaniu. |
|
|
Problem NP-zupełny (NPC) |
czyli problem zupełny w klasie NP ze względu na redukcje wielomianowe, to problem, który należy do klasy NP oraz dowolny problem należący do NP może być do niego zredukowany w czasie wielomianowym. Przykłady problemów NP-zupełnych: |
|
|
alfa(notacja trójpolowa) może mieć postać |
• P - procesory identyczne |
|
|
beat(notacja trójpolowa) może mieć postać |
• pmtn – zadania podzielne (preemption) |
|
|
gama(notacja trójpolowa) może mieć postać |
Cmax "czas zakończenia wszystkich zadań długość wykonywania wszystkich zadań" |