![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
83 Cards in this Set
- Front
- Back
|
Validity: GMA |
0.51 Schmidt & Hunter (1998) |
|
|
Validity: Work Sample |
0.54 Schmidt & Hunter (1998) |
|
|
Validity: SJT |
General job perf: .58; Managerial perf: .67 Christian, Edwards, & Bradely (2010) |
|
|
Validity: AC |
0.37 Schmidt & Hunter (1998) |
|
|
Validity: Biodata |
0.37 Hunter & Hunter (1984) |
|
|
Validity: Interview |
Structured: .44; Unstructured: .33 McDaniel, Whetzel, Schmidt, & Mauer (1994) |
|
|
Validity: Personality |
Conscientiousness: .24; Emotional Stability: .17 Barrick, Mount, & Judge (2001) |
|
|
Validity: Integrity |
Overall: .15; Counterproductive behav: -.32 Van Iddekingee, Roth, Raymark, & Odle-Dusseau (2012) |
|
|
Validity: CSE |
Self-eteem: .26; self-efficacy: .45; Locus of control: .32; emotional stability: .19 Judge & Bono (2001) |
|
|
What three pieces of evidence can an organization bring forward to answer a disparate impact charge? |
a. Business necessity |
|
|
Stock and flow statistics: What are they and what are they used for? Can you pick out the warning signs for adverse impact by seeing these metrics? |
Stock statistics: compare the percentages of specific internal and external demographic groups of workers at one point in time. (uses relevant labor market (RLM) data.
Flow statistics: determine how minority members fared in the selection process in comparison to nonminority members. (use for AI) |
|
|
Burden of proof—how does it work? |
Disperate Tx: Plaintiff must provide the following:
Adverse Impact: Employers
|
|
|
Disability—how is it defined? |
Someone who has (a) physical or mental impairment that substantially limits one or more major life activities, (b) has a record of such impairment, or is regarded as having such an impairment. |
|
|
What is the evidence that must be brought forward to show prima facie for disparate treatment? |
|
|
|
Where do inference leaps in HR occur? |
|
|
|
Contrast CTT and GT and how they apply to JA and AC |
|
|
|
|
Domain sampling model: a measurement tool is created by representative sampling from an infinite number of items that together fully represent the construct domain. Criterion domain: DV Construct domain: IV Construct irrelevant variance: error |
|
|
Shrout and Fliess--what is the big picture, conceptually? In what situations would be want to generalize from one or two raters to a pool of similar raters? |
ICC: Ratio of true score variance among individuals to the sum of true variance plus random error variance
ICC tells us the extent the judgements measured are representative of across other judges. We want to generalized when the facets are random. For example, if only two of your rater are available. |
|
|
How do you construct a CI around someone's test score? |
CI = predicted score +/- 1.96(SEE) OR CI = observed score +/- 1.96(SEM) |
|
|
Clinical versus mechanical judgment (Highhouse; Meehl):
|
1) Intuition is not good usually; overestimate accuracy, use irrelevant info, but, can be useful when looking for unique composites or 'broken-leg" 2) ? NEED TO ANSWER |
|
|
Systematic variance |
Systematic differences; effect of the manipulation of the IV |
|
|
Unsystematic variance |
Variance that is not systematic (can result from the "expert" judges rather than stats) |
|
|
Error variance |
Error in scores due to extraneous variables. |
|
|
Common factor variance |
BLANK; NEEDS TO BE ANSWERED |
|
|
specific variance |
BLANK; NEEDS TO BE ANSWERED |
|
|
What combinations of variance would equate to reliability? |
perfect reliability = 1-proportion of error variance/total variance |
|
|
What are differences between the following and when would you need to use them? a) standard deviation b) standard error of the mean c) standard error of measurement d) standard error of the estimate |
a) standard deviation: measure of variance of the scores. Average deviation from mean in sample. b) standard error of the mean: SD of the means of all samples that were randomly extracted from a population of units. Give measure of sampling error. c) standard error of measurement: SD of the distribution of an individual's scores around his/her true score. d) standard error of the estimate: SD of the distribution of residuals that result from a simple or multiple regression analysis. |
|
|
Reliability's relationship with validity (attenuation formula) |
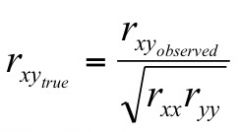
|
|
|
What is reliability conceptually? What are the four types? |
|
|
|
Inferential leaps in validity and JA: where and why do they occur? |
1) Work info -> human attributes 2) Human attributes -> selection procedure 3) work related info -> performance measures 4) selection procedures -> performance measures (validity) |
|
|
MTMM--how and why is it used? What is the primary critique of the method and how is it resolved? |
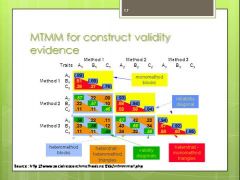
Use: convergent validity = mono-trait, hetero-method divergent/discriminant validity = heterotrait, monomethod Critique: |
|
|
When should you conduct a content validity study? Critierion? Concurrent versus predictive? |
Content validity: does selection test adequately represents domain sample Criterion validity: does DV accurately measure domain of outcome? Concurrent vs. predictive: |
|
|
Validity generalization, synthetic validity, validity specificity. What is the difference and when would you use each one? |
Validity generalization: is test validity generalizable from one context to another similar? Synthetic validity: (job component) infer validity for a job by IDing major functions then choosing tests or other predictors based on research. Validity specificity: validity is specific to the job or org in which the measure was validated |
|
|
Utility analysis--why is it used? SDy rule of thumb (approximately 40% of mean salary for the job) |
Shows the degree to which use of a selection measure improves the quality of individuals selected versus the quality of invididuals selected if the measure had not been used. (Cascio; Schmidt). Expected $ payoff due to increased productivity annually. |
|
|
Job evaluation: a) why is it done? b) what are some ways it's typically done right now in corporations? c) does it serve its purposes? |
Purpose: to demonstrate relative worht of jobs in an org. Results in job structure. How it's done:
+ most common and most rigorous - can become beureaucratic and rule-bound
+ fast, easy, initially least expensive, easy to explain - can be subjective and/or misleading (bias not called out)
+ can group a wide range of work together in one system - descriptions may leave too much room for manipulation |
|
|
What pay/reward structures are typically used in orgs. What are strengths and weaknesses of each? (Lawler & Jenkins, 1992) |
Skill-based Systems:
Pay for individual performance:
Pay for org performance:
|
|
|
Reconciling the evidence on the effectiveness or gut instincts. When does it serve us well? When does it not? WHy? |
Generally, intuition and experts are not as good as stats. Experts overstimate, rely on too few pieces of info. Experts can:
(Highhouse; Meehl) |
|
|
CM vs TJA: similarities, differences, and pros and cons of each. |

CM: development focused;can be org specific TJA: task focused; selection; standardized |
|
|
How do you test for AI? (Bobko & Roth, AI book Ch 2) |
4/5ths rule (practical significance) Statistical significance
|
|
|
Comprehensive HR strategies to avoid AI |
Note: these recs are from multiple sources in AI book a) remove performance irrelevant variance b) recruit quality minority applicants c) provide extensive employee development programs d) define critieria broadly (Murphy) e) Aguinis software tool for cut scores f) Tippins recs |
|
|
Describe the Brunswick Lens Model and apply to personnel/performance appraisal processes. |
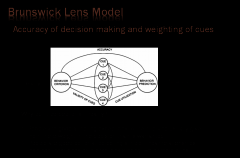
Relaity vs perception cues and cue utlization impact connection between the two and accuracy. 1) people are good at noting exceptions to the rule and usually give them more weight in the decision than is warranted. 2) People are better at detecting simple, linear relationships, than nonlinear ones or interactions among two or more cues. |
|
|
Strategies for decision making and pros and cons of each |
1) Top down Pro: valid if there is a linear correlation between predictor and job performance Con: susceptible to AI 2) Cut scores Pro: minimize/narrow applicant pool to subset of minimally selective group; easy to explain Con: can be expensive/resource intensive; all applicants must go through all procedures. No clearcut way to order applicants because they either pass or fail. 3) Multiple hurdles Pro: same benefits of cutoff but with reduced cost Con: establishing validity for each predictor because of range restriction resulting; increased time needed for implementation 4) Fixed banding 5) Sliding banding Pros for banding: employer has more flexibility in making decisions; select within band; allows employers to take into account factors that are not taking into account in traditional selection systems. Cons for banding: legal debate; may not reduce AI by a lot; may lead to loss of economic utility. Expert judgement + stats is problematic. SEM if high makes bands too wide.
|
|
|
How do you check for test bias? a) differing intercepts? reasons why? does it always mean test bias? b) differing slopes: why does this happen? c) statisically, how can we test for differing intercepts and slopes? |
|
|
|
Conceptually, what does unfair discrimination mean? (Guion) |
Those who have an equal probability of meeting the job performance standard have an unequal probability of being hired. |
|
|
At which points could Type II errors be committed in various HR activities (e.g., range restriction, unreliability, unequal subgropu sizes with MMR for testing for test bias, etc.) How does shared contaminiation create conditions for Type I errors? |
BLANK; NEEDS TO BE ANSWERED |
|
|
Banding:
|
BLANK; NEEDS TO BE ANSWERED |
|
|
What is the efficacy for cognitive ability predicting performance? (Schmidt & Hunter, Hunter & Hunter; Murphy) |
.51 (Schmidt & Hunter) |
|
|
What is the systemic, historical picture of g and subgroup differnces? |
First v. second generation models:
Psychometric perspective v. debates
|
|
|
Why do we see subgroup differences in g? (3-4) |
|
|
|
What are the construct vlaidity issues around g? |
Spearman/Jensen and psychometric perspective suggest variability in race on intelligence is due to actual differences between groups in intelligence. An alternate explanation (Goldstein et al) suggests that construct validity may be the true culprit. |
|
|
How has g been conceptualized? |
|
|
|
Theory of AI (Outtz & Newman). Why does it occur? |
BLANK; NEEDS TO BE ANSWERED |
|
|
What is the Spearman Hypothesis? |
Variance in race groups is not error, but corersponds to actual differences. |
|
|
What is the positive manifold? |
Suggests that g exists as is evident by the correlation of all tests measuring intelligence.
*Understand the idea that simply observing a Positive Manifold in absence of theoretical justification is insufficient for inferring with a degree of certainty that a latent variable (g) exists |
|
|
According to Campion et al., (1997), what makes an interview structured? |
Structured = extent to which it meets below criteria
|
|
|
What is the distinction between construct and method and why is this important? |
BLANK; NEEDS TO BE ANSWERED |
|
|
Does personality predict performance? |
Depends on what element of personality and how performance is defined.
|
|
|
What are some issues and challenges with personality testing? |
|
|
|
What are some critiques of personality testing? |
BLANK; NEEDS TO BE ANSWERED |
|
|
What's Hough & Barrett's perspective on personality testing? |
Hough & Oswald
|
|
|
How do AC's work? |
BLANK; NEEDS TO BE ANSWERED |
|
|
Do AC's predict job performance? |
validity = .37 (Schmidt & Hunter, 1998) |
|
|
What is the argument between Lance and Arthur re: AC's? |
|
|
|
AC's: transparency of dimensions--pros and cons. |
ransparency of dimensions: pros and cons
|
|
|
Job performance/criterion problem
|
|
|
|
Alignment between business strategy and performance management. |
lignment between business strategy and performance management (Schiemann)
|
|
|
What are some cultural considerations in performance management. (hint: know Hofstede dimensions) |
|
|
|
What's Hattrup & Roberts' argument about the AI validity tradeoff? |
Hatrup and Roberts would suggest that AI and validity are actually outcomes that exist at different levels of analysis. AI and diversity-related factors are group level measures whereas the discussion of validity as it relates to selection is related to individual-level performance, and not group. Therefore, to consider both as outcomes at a similar level is flawed logic. It is a (some would argue unrealistic) leap to claim that the aggregate of individual task perf. completely maps onto performance at the org level. |
|
|
What are some ways to encourage contextual performance in an organization? (Reilly 7 Aronson) |
|
|
|
What are some ways to encourage employees ot accept performance feedback in healthy ways? ( Diamante, Sessa, et al) |
|
|
|
What are some of the disadvantages to a univariate model of job performance? (Murphy) |
Multivariate allows for more variance to accounted for and more predictors to included (can also include AI as a social outcome) |
|
|
What are some practical suggestions for reducing AI in a selection test? (Schmidtt and Quinn) |
|
|
|
Typical (will do) versus maximum (can do) performance. What's the difference? |
Typical = will do Maximum = can do Increased variability is negatively related to compensation (Barnes & _____) |
|
|
What are the issues with MA corrections and how do they apply to practice? |
Overestimation of effect sizes provides more optimistic picture |
|
|
What are sources of bias in performance ratings? (Landy; McKay) |
|
|
|
What are some ways to predict and manage counterproductive performance behaviors? (Atwater & Elkins) |
|
|
|
What are some artifactual factors that influence performance ratings? |
BLANK; NEEDS TO BE ANSWERED |
|
|
What are some performance appraisal methods? (Aguinis)
|
BLANK; NEEDS TO BE ANSWERED |
|
|
What are some pros and cons associated with various sources of ratings: |
Supervisors Peers Subordinates Self |
|
|
What are some rater motivations that are linked to rating inaccuraties, and how can they be mitigated? |
BLANK; NEEDS TO BE ANSWERED |
|
|
BLANKS; NEEDS TO BE ANSWERED |
|
|
Criticisms of JE (Lawler & Jenkins) |
1) psychometric properties 2) unintended consequences ("that's not my job") 3) System congruence
|
|
|
What factors affect statistical conclusion validity when conducting stat anslyses in the context of selection? |
1) reliability of criterion and predictor 2) Violation of statistical assumptions 3) Range restriction 4) Criterion contamination
|