![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
54 Cards in this Set
- Front
- Back
|
SISD |
single instruction, single data |
|
|
MISD |
multiple instruction, single data |
|
|
SIMD |
single instruction multiple data GPGPU processing (general purpose GPU) |
|
|
MIMD |
multiple instruction, multiple data |
|
|
FIDFOE |
fetch instruction decode fetch operation execute |
|
|
SPMD |
single program multiple data |
|
|
things to keep in mind about PP |
logical organization of program physical organization of hardware how tasks are defined how interactions occur between tasks |
|
|
UMA |
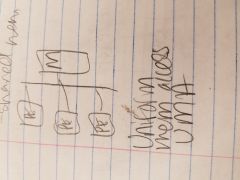
uniform memory |
|
|
NUMA |
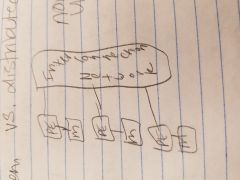
non-uniform memory (it says interconnection network) |
|
|
is distributed memory non-uniform or uniform or can be shared memory too |
NUMA |
|
|
diameter |
max distance between any 2 nodes |
|
|
connectivity |
how many cuts to split graph in 2 |
|
|
bisection width |
min cuts to divide graph in half |
|
|
4 problems with cache |
cache coherence (invalid protocols, update, snoopy, directory based) cache thrashing (FORTRAN) algorithms are embarrassingly parallel false sharing |
|
|
theta |
argonne national labs dragonfly topology bridge between mira and aurora 18 in top 500 8.6 petaflops |
|
|
sequoia |
lawrence livermore national labs 14 months to test, cards kept failing during thermal test #1 when released now #4 20 petaflops |
|
|
tianhe2 (milky way 2) |
china #2 54 petaflops |
|
|
piz daint |
sweden water-cooled by lake runs weather forecast simulations #8 15.9 petaflops |
|
|
titan |
located in oakridge tn #1 in america #3 on top 500 27 petaflops |
|
|
pleiades |
nasa owned runs kelper's quest to identify expoplanets #13 7 petaflops |
|
|
lomonosov |
moscow, russia most powerful in russia and eastern europe research for 600 groups #132 1.7 petaflops |
|
|
Oak forest PACS |
japans most powerful supercomputer #6 24 petaflops |
|
|
HazelHen |
stuttgart, Germany dragonfly topology #14 7.4petaflops |
|
|
mira |
argonne national lab illinois 5d torus #9 10 petaflops |
|
|
DGX Saturn V |
worlds most efficient SC made by NVidia deep learning #28 4.9 petaflops |
|
|
trinity |
los alamos national labs new mexico nuclear weapon simulations #10 11 petaflops |
|
|
bus |
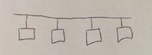
d = 1 c = 1 |
|
|
complete graph |
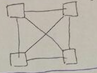
d = 1 c = n - 1 |
|
|
star |
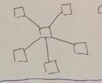
d = 2 c = 1 |
|
|
linear array |
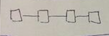
d = n - 1 c = 1 bw = 1 |
|
|
ring |
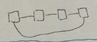
d = n/2 c = 2 bw = 2 |
|
|
2D mesh |
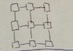
d = 2 (sqrt(n) - 1) c = 2 bw = sqrt(n) |
|
|
2d torus |
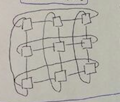
d = sqrt(n -1) c = 4 bw = 2 * sqrt(n) |
|
|
hypercube |
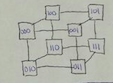
d = log2 (n) c = log2 (n) bw = n / 2 |
|
|
tree |
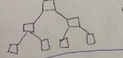
d = 2log2 (n) c = log2 (N) |
|
|
fat tree |
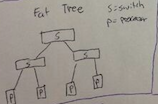
|
|
|
cross bar |
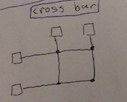
|
|
|
omega |
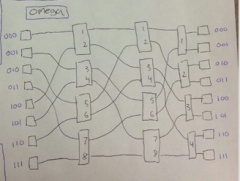
|
|
|
atomic in openmp |
has to happen at 1 time and can't be interrupted
|
|
|
default (none) |
means nothing is shared |
|
|
openmp how to wait for all threads to finish |
#pragma omg barrier |
|
|
how to create threads in openmp |
#pragma omp parallel num_threads(#) |
|
|
things to know about communicating |
communicate in bulk (minimize start up time) minimize volume of data minimize distance that you send things |
|
|
what does single mean in openmp |
it means it has one thread do the code. whichever thread gets their first, then after finishing it continues |
|
|
wait statement in pthreads |
pthread_cond_wait(&cv, &mutex); |
|
|
creating a mutex in pthreads |
pthread_mutex_t nameofmutex = PTHREAD_MUTEX_INITIALIZER; |
|
|
creating a condition variable in pthreads |
pthread_cond_t cv = PTHREAD_COND_INITIALIZER; |
|
|
create threads in pthreads |
pthread_create(&threads[#], NULL, fund, #) |
|
|
destroy a mutex or condition in pthreads |
pthread_cond_destroy(&name); pthread_mutex_destroy(&name); |
|
|
how to lock in pthreads and unlock |
pthread_mutex_lock(&nameOfMutex); pthread_mutex_unlock(&nameOfMutex); |
|
|
how to broadcast in pthreads |
pthread_cond_broadcast(&cv); |
|
|
store and forward |
data network in which messages are routed to one or more intermediate stations where they may be stored before being forwarded to their destinations |
|
|
packet routing |
Packet forwarding is the transit of logically addressed network packets from one network interface to another. Intermediate nodes are typically network hardware devices such as routers, bridges, gateways, firewalls, or switches |
|
|
cut through routing |
cut-through switching is a method for packet switching systems, wherein the switch starts forwarding a frame (or packet) before the whole frame has been received, normally as soon as the destination address is processed. |