Reading...
![]()
Play button
![]()
Play button
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
134 Cards in this Set
- Front
- Back
|
Why is random assignment considered to be the gold standard for researchers to infer causality?
|
because of its ability to rule out alternative explanations
|
|
|
What is considered to be the gold standard for researchers to infer causality?
|
random assignment
|
|
|
What is an experimental design?
|
participants are randomly assigned to either treatment or control conditions
|
|
|
What are some other terms for an experimental design?
|
Randomized experiments, randomized control trials (RCT), or randomized clinical trials (RCT)
|
|
|
What questions do the counterfactual model ask?
|
1) If the individuals who received the treatment had in
fact not received it, what would we observe on Y for those individuals? or 2) If the individuals who did not receive the treatment had in fact received it, what would we have observed on Y? |
|
|
Describe the counterfacutal argument.
|
-in random assignment control and treatment are equivalent at start of experiment (theoretically interchangeable)
-they represent each other’s counterfactual -RA: effect of manipulation is difference between two groups on DV (no other cause = causality) |
|
|
What are quasi-experimental designs:?
|
participants are assigned to groups by a method other than random assignment
|
|
|
What are the two types of quasi-experimental designs?
|
–Non-equivalent-group design
–Regression-discontinuity designs |
|
|
What is a non-equivalent-group design?
|
-treatment and control groups are already formed
-existing groups -experimenter has no control over group assignment |
|
|
What are examples of existing groups? (non-equiv group design)
|
-presence/absence of illness/conditions
-behaviours (smoking, drug use, overweight) -male, female -age |
|
|
What is the key difference between non-equivalent group design and regression-discontinuity?
|
assignment variable
|
|
|
What are some ideals with non-equivalent group design?
|
-groups should be as similar as possible
-be able to randomly choose what group receives the treatment |
|
|
What is a regression-discontinuity design?
|
participants are assigned to conditions based on a cut-off score on an assignment variable
|
|
|
What is the meaning behind the name of the regression-discontinuity design?
|
looking for a discontinuity (break) in the regression line
|
|
|
In regression-discontinuity designs, does the assignment
variable have to predict the outcome? |
no!
|
|
|
How are regression-discontinuity designs SIMILAR to non-equivalent group designs? but...
|
in RDD, the method implies that groups are non-equivalent BUT researcher knows how participants were assigned to conditions
|
|
|
Draw a regression-discontinuity designs (with letters).
|
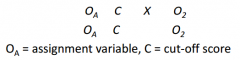
|
|
|
Draw the results from a RDD when there is a relation between assignment variable and outcome (Y).
|
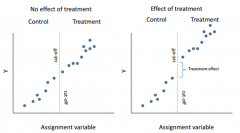
|
|
|
Draw the results from a RDD when there is no relation between assignment variable and outcome (Y).
|
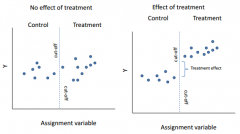
|
|
|
How are regression-discontinuity designs analyzed?
|
-using multiple regression
|
|
|
Draw a "one time observation" design.
|
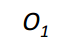
|
|
|
Draw a "one group pretest-posttest design".
|
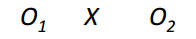
|
|
|
How could a "one group pretest-posttest design" be strengthened? Draw.
|
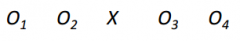
-add more pretests and posttests
|
|
|
What is a "repeated-treatment design"? Draw.
|
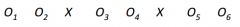
introduce and remove treatment within the same participants over time
|
|
|
Draw a posttest-only design.
|
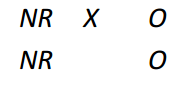
|
|
|
What is the weakness of posttest-only designs?
|
because there is no pretest, it is susceptible to all forms of selection threats
|
|
|
Draw a "pretest-posttest design".
|
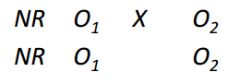
|
|
|
Why is a "pretest-posttest design" an improvement on posttest only?
|
can test for group equivalence before treatment
|
|
|
Draw a double-pretest design.
|
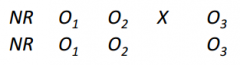
|
|
|
What threats does a double-pretest design help overcome (compared to one pretest only)?
|
-tests for the stability of equivalence
-might identify a change that was going to happen anyway ---selection-regression: one/both groups might regress to average ---selection maturation: underlying change that was going to happen anyway |
|
|
Draw how a double-pretest might detect a selection maturation/regression threat.
|
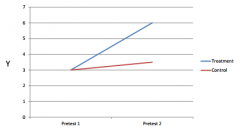
|
|
|
Draw a "switching of treatments" design.
|

|
|
|
What are some advantages to a "switching of treatments" design?
|
-eliminates many threats to internal validity
-allows researchers to test if effects of treatment are maintained -Ethical advantage of giving everyone the treatment -more observations, more information! |
|
|
What three conditions must exist to measure causality?
|
1. X must precede Y temporally (cause --> effect)
2. X must be reliably correlated with Y (beyond chance) 3. The relation between X and Y must not be explained by other causes |
|
|
What is internal validity?
|
the degree to which we can draw conclusions about causal relationship in our data
|
|
|
What do we mean by "degrees of causality"?
|
meeting the three criteria to various degrees
|
|
|
How can we answer threats to internal validity?
|
-manipulation
-random assignment -eliminate/include extraneous variables -statistical control -rational argument -analyze reliable scores |
|
|
How is internal validity established?
|
by controlling for extraneous variables
|
|
|
What do all threats to internal validity have in common?
|
-they are ALL different types of third variables (3rd requirement for causality)
|
|
|
List the general threats to internal validity.
|
-history
-maturation -testing -instrumentation -attrition -regression -ambiguous temporal precedence |
|
|
List threats to internal validity with multiple groups.
|
-selection
-resentful demoralization -compensatory rivalry -treatment diffusion or imitation -compensatory equalization of treatment -novelty and disruption effects |
|
|
How does "direct manipulation" establish internal validity?
|
-controls when and how “the cause” occurs
-also controls magnitude of effect |
|
|
How does "random assignment" establish internal validity?
|
-minimizes differences between groups by equally distributing characteristics across groups.
-equates groups on all variables (those measured and not measured) before study |
|
|
How does "Elimination or inclusion of extraneous variables" establish internal validity?
|
elimination = making sure other factors are constant
inclusion = direct measurement of a factor and its inclusion as a variable |
|
|
How does "statistical control" establish internal validity?
|
-measure extraneous variables (but don't explicitly represent as variables)
-remove their influence on outcome statistically (covariates) |
|
|
How does "rational argument" establish internal validity?
|
offer arguments for why a potentially extraneous variable is not substantial
|
|
|
How does "analyzing reliable scores" establish internal validity?
|
makes sure effects are due to content of measures not random or systematic error
|
|
|
What are the two most important methods of establishing internal validity?
|
manipulation and random assignment!
|
|
|
What are threats to internal validity (in general)?
|
-something that jeopardizes our ability to conclude that X causes Y
-“Third variables” |
|
|
How is "history" a threat to internal validity?
|
Specific event that take place concurrently with treatment. Could be anything (e.g., weather change, big event in news, local initiative, etc.).
|
|
|
How is "Maturation" a threat to internal validity?
|
Naturally occurring changes are confounded in the treatment. People change over time. Get older, more mature, hungrier, make more money, etc.
|
|
|
How is "Testing" a threat to internal validity?
|
Practice or reactivity. Simple measuring something may change outcome (i.e., information provided, introspection occurs)
*Relevant for longitudinal or lagged designs where participants are tested more than once |
|
|
How is "Instrumentation" a threat to internal validity?
|
The meaning and interpretation of observations change over time.
*Particularly pertinent for observers or coders (e.g., get tired, change their standards, etc.) |
|
|
How is "Attrition" a threat to internal validity?
|
Loss of cases from study. Problem when it is systematic (e.g., certain people are more or less likely to drop out than others).
*mortality!* |
|
|
How is "Regression" a threat to internal validity?
|
-Statistical regression to the mean.
-Tendency for extreme cases to be less extreme on subsequent measures. *Problematic when selecting participants based on extreme scores. |
|
|
How is "ambiguous temporal precedence" a threat to internal validity?
|
Lack of understanding about what variable occurred first (which is the cause and which is the effect). Measuring variables at same time.
e.g. job satisfaction and performance |
|
|
How is "selection" a threat to internal validity?
|
-multiple groups
-respondents in conditions differ at the outset. |
|
|
What is resentful demoralization?
|
: Control cases learn about treatment become resentful and stop trying or withdraw from study.
|
|
|
What is compensatory rivalry?
|
Control cases learn about treatment and become competitive with treated cases.
|
|
|
What is "treatment diffusion or imitation"?
|
Control cases learn about treatment or try to imitate experiences of treated cases.
|
|
|
What is compensatory equalization of treatment?
|
Cases in one condition demand to be assigned to the other condition or be compensated.
|
|
|
What are novelty and disruption effects?
|
Cases respond well to a novel treatment or poorly to one that interrupts their routines.
e.g. Hawthorne effect |
|
|
What is the "Hawthorne Effect"?
|
participants alter their behavior as a result of being part of an experiment or study
-attention/being observed |
|
|
How can threats combine to produce new threats to internal validity?
|
selection-attrition
selection-regression selection-maturation *selection + ARM |
|
|
What is selection-maturation?
|
Different rates of change (or growth) between groups.
|
|
|
What is selection-attrition?
|
Rate of missing data is higher in one group than another.
|
|
|
What is selection-regression?
|
There are different rates of regression to the mean across groups.
-likely to happen when only one group is selected based on extreme scores |
|
|
What threatens external validity (general)?
|
Any characteristic of a sample, treatment, setting, or measure that leads the results to be specific to a particular study and not generalizable.
|
|
|
What is external validity?
|
Inferences about whether the results of a study will hold over variations in participants, treatments, settings, and measures.
|
|
|
What are two subcategories to external validity?
|
population validity
ecological validity |
|
|
What is population validity concerned with?
|
Can you generalize from your sample to the population or to another defined population?
|
|
|
What is ecological validity concerned with?
|
Concerns whether the combination of manipulation, settings, or outcomes approximate those in real life situation under investigation.
|
|
|
How can we establish external validity before and after our experiment?
|
before: probability sampling techniques
after: establish external validity through replication (empirical approach) |
|
|
What are probability sampling techniques?
|
-simple random sampling
-stratified sampling -cluster sampling |
|
|
What is simple random sampling?
|
Researchers try and select participants at random from the population.
*All observations have equal opportunity to be selected. |
|
|
What is cluster sampling?
|
Population is divided into clusters (groups) and entire clusters are randomly selected.
randomly select clusters |
|
|
What is stratified sampling
|
Population is divided into homogeneous, mutually exclusive groups (strata; e.g., neighbourhoods).
observations are randomly selected from within each stratum. |
|
|
What are two forms of non-probability sampling?
|
-accidental/ad hoc/convenience/locally available
-purposive sampling |
|
|
What is accidental sampling?
|
AKA convenience sampling
-Cases are selected because they are available. -Very practical approach. -Samples are not representative (i.e., there may be systematic differences between those in the study and those not in the study). |
|
|
What is purposive sampling?
|
Researcher intentionally selects cases from defined groups (e.g., sick/not sick, managers, employed people, single parents).
-Groups are typically linked to hypotheses in a meaningful way. -Non-equivalent design -Regression discontinuity design |
|
|
What is a common criticism of non-probability sampling?
|
•The sample used is not “representative.”
•Criticism is about “sample generalizability.” – Results will not generalize – No external validity – Results are sample specific |
|
|
What is the evidence that "samples matter"?
|
There is none!
|
|
|
Why do people think sample characteristics matter?
|
-People confuse random sampling with random assignment.
-People confuse statistical and theoretical generalizability. -People rely on superficial similarities (“like Goes with like”) |
|
|
What questions should you ask when evaluating the appropriateness of a sample?
|
• Did the research question contain a specific and well‐defined population of interest?
• Is there a characteristic of the convenience sample that may interact with the variables of interest in the study? (threat to external validity) • If you are testing a theory, does the theory apply to the sample being used? |
|
|
What does significance at p < .05 mean?
|
8. The probability of the data given the null hypothesis is < .05.
|
|
|
What is the general sequence of events in significance testing?
|
• Compute a sample statistic (e.g., mean).
• Estimate sampling error (standard error). • Compare our sample statistic with null (e.g., mean = 0) accounting for sampling error: ratio (e.g., t-value, z-value). • Converte ratio to an exact probability (p-value) using tables, computers. • compare p value against alpha (established critical value ahead of time). |
|
|
On a t-distribution, what is the t-value of a 5% cutoff?
|
1.67
|
|
|
What does significance testing actually tell us?
|
Given that the null is true, what is the probability of these (or more extreme) data occurring.
*Important: p always refers to the probability of the data. The null is always assumed to be true. |
|
|
What is the biggest problem with significance testing?
|
misinterpretation!
|
|
|
p values are a reflection of what?
|
sample size and effect size
|
|
|
What is a Type I Error?
|
rejecting the null hypothesis when the null is true
|
|
|
What is a Type II Error?
|
failing to reject null hypothesis when the null is false.
|
|
|
What is the most common thing that leads to Type I and II errors?
|
sample size
|
|
|
What are the implications of p values being a reflection of both sample size and effect size?
|
(1) a small effect can be statistically significant in a large sample and
(2) a large effect can fail to be statistically significant in a small sample. |
|
|
What is power?
|
the probability of getting a statistically significant result when there is a real effect in the population
|
|
|
What are factors that affect power?
|
– study design (stronger manipulations have more of an effect)
– level of statistical significance (this can be set to levels other than .05 ahead of time) – type of statistical analysis used – measurement error – sample size – effect size |
|
|
What is the "crud factor"?
|
Almost all of the variables that we measure are correlated to some extent.
|
|
|
With regard to "crud factor," what is the implication for Type I errors under the nil hypothesis?
|
they would not exist!
things are always going to be non-zero to start with |
|
|
What is the "Inverse probability error"?
|
thinking that p is the probability that the null hypothesis is true
|
|
|
What is the "Odds against chance fallacy"?
|
thinking that p is the probability that the results happened due to chance
|
|
|
What is the "Local Type I error fallacy"?
|
If p < .05 then the probability that you are wrong in rejecting the null is less than 5%.
|
|
|
What is the "Replication fallacy"?
|
p is the probability of finding the same result in another study.
|
|
|
What is the "Magnitude Fallacy"?
|
p = effect size
|
|
|
What is the "Meaningfulness (causality fallacy) fallacy"?
|
Rejection of null hypothesis confirms the research hypothesis behind it
|
|
|
What is the "Success/Failures fallacy"?
|
rejection = success
failure to reject = failure |
|
|
What is the "Zero (equivalence) fallacy"?
|
Failure to reject the null means that the effect is zero.
|
|
|
What is the "Sanctification fallacy"?
|
Thinking that there is a big difference between .049 .06, .056, .05 (etc)
|
|
|
What is the "Reification fallacy"?
|
Replication success is determined by examining p values.
|
|
|
p refers to
|
PROBABILITY OF THE DATA!
|
|
|
Name the three requirements to measure causality.
|
-temporal precedence
-no other variables to explain the effect -actual relationship |
|
|
Describe external validity with one word.
|
Generalizability!
|
|
|
What does "meta-analytic thinking" include?
|
-report results so that they can be included in a future meta-analysis (stats to calculate effect size)
-view your study as making at BEST a modest contribution to lit -appreciate previous study results (especially effect size) -compare new results to previous effect sizes |
|
|
What is "impact factor"?
|
descriptive quantitative measure of overall journal quality
-number of times a typical article in the journal has been cited in other work |
|
|
What is "information fatigue/burnout"?
|
problem of managing an exponentially growing amount of information
|
|
|
what is short citation half-life?
|
few works are cite more than a couple of years after they are published
|
|
|
What is the "Trinity of Research"?
|
-design
-measurement -analysis |
|
|
What are the five structural elements of an empirical study?
|
1. Samples (groups)
2. Conditions (eg. Treatment/control) 3. Method od assignment to groups or conditions 4. Observations 5. Time, or the schedule for measurement or when treatment begins or ends. |
|
|
What are the two kinds of extraneous variables?
|
-nuisance (noise) variables that introduce irrelevant or error variance that reduces measurement precision
-cofounding/lurking variables cannot be distinguished from the dependent variable |
|
|
What are the three essential purposes of measurement?
|
-identify and define variable of interest
-operational definition -scores |
|
|
What are the three main goals of analysis?
|
-estimate covariances between variables of interest
-estimate the degree of sampling error associated with this covariance -test the hypotheses in light of the results |
|
|
What is a confidence interval?
|
a range of values that may include that of the population covariance within a specified level of uncertainty
|
|
|
What is a point estimate?
|
covariance determined between the IV and DV
|
|
|
What is interval estimation?
|
Estimation of the degree of sampling error associate with the covariance.
|
|
|
How are confidence intervals often represented?
|
error bars
|
|
|
What is conclusion validity?
|
correct implementation of the design
(1) whether the correct method of analysis was used (2) whether the value of the estimated (sample) covariance approximates that of the corresponding population value. |
|
|
What is "rater drift"?
|
tendency for raters to unintentionally redefine standards across a series of observations
|
|
|
What are threats to construct validity?
|
-unreliable scores (unprecise or inconsistant)
-poor construct definition -monomethod bias (different variables rely on same method or informant) -evaluation apprehension (anxiety) -reactive self report changes (want to be in treatment condition) -researcher expectancies |
|
|
What are some threats to conclusion validity?
|
•Unreliable scores
•Unreliability of treatment implementation •Random irrelevancies in study setting •Random within-group heterogeneity •Range restriction •Inaccurate effect size estimation •Overreliance on stat tests (e.g. ignore effect size) •Violated assumptions of stat tests •Low power •Fishing and inflation of Type I error (e.g. don't correct for familywise error etc) |
|
|
What is the principle of proximal similarity ?
|
the evaluation of generalizability of results across samples, settings, situations, treatments, or measures that are more or less similar to those in the original study
-both pop and eco validity fall under this |
|
|
What does quantitative research emphasize?
|
-Classification and counting behaviour
-Analysis of numerical scores with formal statistical methods -Role of the researcher as an impassive, objective observer |
|
|
What are comparative studies?
|
at least two different groups or conditions are compared on an outcome (dependent) variable
|
|
|
What are the three basic types of research questions?
|
-descriptive
-relational -causal |
|
|
What is a time series?
|
a large number of observations made on a single variable over time
|
|
|
What is an Interrupted time series design?
|
goal is to determine whether some discrete event – an interruption – affected subsequent observations in the series
|