![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
25 Cards in this Set
- Front
- Back
|
What are the two visual streams? |
Ventral (occipitotemporal)"what" stream - identification of objects Dorsal (occipitoparietal) "where" stream - spatial releationships including motion, and for guidance of movements First identified through lesion studies e.g. Mishkin et al 1983 Although not just serial from V1→ end of stream, but lots of jumping, backwards, recurrent connections, between paths. |
|
|
What's the difference between P cells and M cells |
Parvocellular and Magnocellular cells in LGN Parvocellular = small → responsible for form/colour→ feeds into what? Magnocellular = big → responsible for form/motion→ feeds into where? |
|
|
What is Marr's theory of object recognition in the ventral stream? (1982) |
Presumes a hierarchy of visual processing → increasingly complex representations i.e.
|
|
|
What's the progression in the ventral stream? |
RFs get larger as you go furher back → more representation of both visual fields in both hemispheres∴ trigger features actually get much less location specific, more about complex/specific triggers. Also cares less about variability in light, angle, occlusions→ very good at this compared to machines
|
|
|
What else might be special about IT cell responses? |
|
|
|
What are the two types of visual agnostic patients (unable to recognise objects) - how can they help us understand how object processing works |
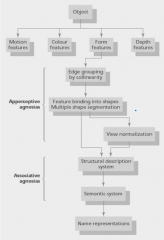
Identified by Lissaier (1980) Apperceptive = Early stages of object recognition - either to do with inability to group edges, bind features or normalise views Associative = can do perceptual tasks, but can't recognise stuff.... |
|
|
What are the specific problems in Apperceptive Agnosia patients? |
|
|
|
What are the specific problems in Associative Agnosia patients? |
|
|
|
What is the Grandmother Cell Hypothesis (Quiroga et al 2005) |
Found a cell that responds to different pictures of Jennifer Anniston, but not when with Brad Pitt → One cell per object/person?! Unlikely∵ cells die regularly BUT could just be very specific object recognition i.e. diff features recognised and they together fire one cell - kinda like one cell/person, but more flexible... |
|
|
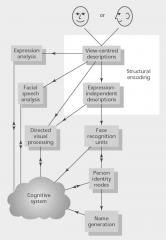
What does the Bruce and Young Model of face recognition state |
|
|
|
Are faces special? |
Is the IT an innate face module, or are we just v specialised for recognising faces Pro
Anti
|
|
|
What are the various inputs for the parts of the dorsal stream? |
MT is first part - gets input from V1, V2, V4, specific for Motion Parietal lobe in general receives lots of inputs e.g. processed/polymodal from association cortices, afferent moto inputs, limbic inputs |
|
|
What are the LIP / VIP neurons? |
both dorsal stream - LIP responses are retinotopic but modulated by eye position, attention, behavioural relevance e.g. can respond to stimulus in the RF that they're about to saccade to even when the stim is removed during saccade i.e. knows planned moves (efference copy?) (Duhamel et al 1992) PLUS eye centred VIP neurons prefer moving stim - selective for speed/orientation, polymodal PLUS head centred This may mean that for small head movements, the LIP knows where stim is and can move eyes to get it back into RF, but if movement of gaze, VIP still has an idea of where stuff was (because head centred) and can direct movement back. Generally both are able to direct attention |
|
|
What are the problems in the way that the dorsal stream has been studied |
Animal lesion studies - homology of the regions between animals and humans isn't wholly clear... especially when you consider humans more complex planned motor actions. e.g. Macaque parietal v different Human lesions aren't much help either because broad fMRI is tentative - may be that TMS will be useful in future/fMRI getting better? |
|
|
What is the Ungerleider Mishkin (1982) theory of the streams? |
Largely came from parietal lesions in animals→ parietal lesions→ contralateral neglect/extinction (if less severe). Neglect can even be in mental imagery e.g. of Duomo in milan (Bisiach & Luzzatti 1978). Fine at ventral stream processing on both sides i.e. objects on neglect side can still prime for word/non-word decision even though not attended (McGinchley-Berroth et al 1993) Similarly Balints syndrome can be caused by bilateral parietal lesions = simultagnosia, so can't perceive more than one object∴ no spatial relationships, although if it can be framed as a single item e.g. a face, not two circles → can perceive it (Shalev & Humphreys 2002) Neuroimaging finds more dorsal activation in spatial comparison space task, more ventral stream for facial recogntion, although V1 in both (Haxby et al 1991). Activation in neglect patient GK is fine for early/ventral stream i.e. identical for bilaterally presented (where it isn't perceived) as it is to unilateral presentation (where it is perceived). |
|
|
What is the Milner & Goodale (1974) Theory of visual streams |
Used mainly data from neuropsychological studies - suggested that it's more about perception/action rather than objects in space. i.e. using the objects in that space. Dissociation between impaired action and impaired recognition:
Ventral lesioned patient (DF) can't match irregular wooden shapes, but can pick them up at the correct grasp points, whereas dorsal lesioned patient (RF) can match the shapes, but can't pick them up. (Goodale et al 1994) Illusions even show the action/perception distinction→ 3D setup of Muller Lyer - two identical lines perceived as diff sizes + estimate length with fingers, but as you grasp that's corrected nad becomes accurate (Hart et al 1999) |
|
|
How cna we resolve the differences between the ungerlieder/mishkin model and Milner/Goodale model |
Creem & Proffitt (2001) suggest ataxia may be more superior lesions, neglect more inferior lesions→ superior about action, inferior about spatial processing. BUT not actually that easy to separate the lesions e.g. neglect also seems to be lateralised i.e. hemisphere specific unlike ataxia + no neuroimaging support Glover (2004) suggested planning-control model where inferior parietal selects targets for action/plan it, superior parietal monitors accuracy/makes adjustments based on spatial info. e.g. in 3D Muller lyer or 3D Ebbinghaus, the fingers close in ∵ adjusting |
|
|
How are features of stimuli bound together - given features are processed kinda separately e.g. colour, shape, motion→ single image |
May be that they all converge on a single grandmother-like cell (probs not because not enough cells/they die) or form a cell assembly i.e. briefly act as a closed system→ then activates other systems (Hebb 1949) |
|
|
What could be used to bind cell assemblies? |
|
|
|
What's the evidence for synchronous firing? |
Cat visual cortex - Single bar moving across both cells receptive fields→ synchronous firing, two bars movingg across RFs so it looks like a single bar→ synchronous firing BUT if diff directions, so clearly diff object → no synchrony (Singer et al 1990, 1993, 1995, Engel et al 2001) Similarly single bars moving over multiple RFs → synchrony between them all, but if 2 bars at diff orientation → splits population so one set prefers bar 1 and syncs amongst selves, same for other bar. (Singer 1995, Engels 1992) |
|
|
How might neurons detect synchrony? |
Temporal summation in postsynapse w/ tight window (few ms) (Softky & Koch 1993) |
|
|
How are populations likely to form stable cell assemblies? |
Synaptic plasticity? May be too slow? May be driven by 40Hz oscillations generated by thalamus and cortex→ permit/aid synchrony. W/o them→ no synchrony. May be initiated by reticular formation→ stim of reticular formation→ stimulation. Reticular formation important in sleep, so it makes sense that synchrony is diff between wake/sleep which it is.... Probably relies on corticocortical connections → if kitten given divergent squint→ disrupts intracortical connections in visual cortex→ no synchrony between groups on different eyes (Konig et al 1993) |
|
|
What does Treisman say about attention and how it influences binding? What's the evidence for this? |
Treisman suggests that not everything is bound and that the spatial attention spotlight binds things. Based on popout i.e. if you have to bind features→ much slower to find something - needs to use spotlight to scan, whereas if just looking for a single feature → very quick popout. Posner et al (1984) looked at valid/invalid cueing followed by a response. Found invalid cue→ longer ∵ has to disengage attention, move, reengage. Can actually separate i.e.
|
|
|
What is Desimone and Duncan's biased competition model? |
Top down attentional bias starts to change the activity, then neurons have their own competition based on inputs and ultimately some stim fire neurons more effectively→ attended to. Evidence for top down control
Evidence for bottom up competition
Interestingly, top down control has same effect on activity of cells as doubling stimulus salience. No effects in V1, just in higher cortex. May be that RFs in V1 small so unlikely to even have two stim in one V1 RF. How does this relate to binding? Hotly debated→ some believe that attention mods the binding (Luck, Fries), others argue that binding gives you the groups that can then be attended to (Singer) |
|
|
How do the biased competition model and spatial spotlight models compare on how they think about attention? |
Both incorporate bottom up and top down attention i.e. voluntary and automatic controls e.g. latPFC and frontal eye circuits for top down and LIP for bottom up (Buschman and Miller 2007) May be that diff freq of synchrony i.e. top down = low freq sync, bottom up = high freq sync |