![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
123 Cards in this Set
- Front
- Back
|
Why are sine waves always used? |
Because sine waves are eigenfunctions of linear, time-invariant systems Time-invariant means that the properties of the system do not change over time. Linear means if x -> y then 2x -> 2y Eigenfunctions are functions that consist of the same components at input and output. |
|
|
Explain what a DFT is, does. |
// |
|
|
What is the total harmonic distortion? |
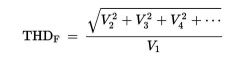
The ratio of the RMS sum of the higher harmonics to the amplitude of the base frequency. |
|
|
Give the basic model of a digital filter |
|
|
|
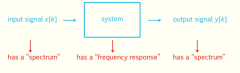
What is the difference between spectrum and frequency response? |
A signal can be described by it’s spectrum that indicates which amplitude (and phase) each frequency component has. A system can be characterized by it’s frequency response that indicates for every frequency component how much it is amplified (or attenuated, this is the gain), and how much it is delayed (this is the phase shift). |
|
|
How to determine the frequency response of a system? |
a system can by characterized by it’s impulse response that corresponds to the output y[k] if the input is an impulse ( x[k] = [1 0 0 0 0 0 0 …]T ). The spectrum of the impulse response (yes, indeed, a “spectrum”, since the impulse response is a signal), is equal to the frequency response |
|
|
Explain the different parts of the human speech production system |
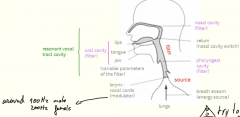
Breath stream is modulated by the vocal cords and filtered by the vocal tract to produce speech Unvoiced phonemes are not modulated by the vocal cords. The filter corresponds to the path between the vocal cords on the one hand and the lips and the end of the nose on the other hand. It comprises the pharyngeal cavity, the oral cavity and the nasal cavity. The pharyngeal cavity is fixed, it is time-invariant. The properties of the oral cavity can be changed by varying the position of the tongue, the jaw and the lips. |
|
|
What is a phoneme? |
A phoneme is the smallest contrastive unit in the sound system of a language. i.e. the smallest phonetic unit in a language that is capable of conveying a distinction in meaning. the word ph o n e me has 5 phonemes |
|
|
Give the different source signals of human speech
|
A vowel is produced by a periodic source signal, a pulse train resulting from the periodic opening and closing of the vocal cords. This pulse train is filtered in the vocal tract cavity. Different filters result in different spectra and in different sounds, i.e. different vowels. A plosive sound is produced by an impulsive source. Just before the sound generation, all paths to free air are closed, pressure is built up and then suddenly released. This results in a noise burst. A fricative sound is produced by a noise source (unvoiced) or a mixture with a periodic source (voiced). The breath stream (modulated or unmodulated) is forced through a narrow gap (small wave lengths), resulting in highfrequency noise. |
|
|
How to calculate the vocal tract filter? |
Use Linear predictive coding to make an estimate of the filter that approximates the frequency response. |
|
|
What are formants? |
The formants correspond to the peaks in the frequency response of the vocal tract filter, so they indicate which frequencies are amplified most by that filter |
|
|
What is pulse code modulation? |
The signal is approximated by a set of weighted pulses, whose amplitude (weight) corresponds to the quantization level. This straightforward combination of sampling and (linear) quantization is often referred to as (linear) Pulse Code Modulation (PCM). |
|
|
What is quantization error?
|
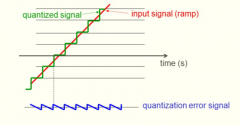
The difference between the quantized signal and the original signal is called the quantization error signal. |
|
|
What is the signal to quantization noise ratio? SQNR |
The Signal-to-Quantization Noise Ratio is defined as the rms value of the signal divided by the rms value of the quantization error, expressed in dB. It can be proven that this value increases with 6 dB for every bit that is added to the word length of the sampled data. 6.02N dB |
|
|
Difference noise and distortion? |
Noise in uncorrelated with the signal, while distortion is correlated with the signal. Quantization error is a form of distortion at low signal levels and noise at higher signal levels. |
|
|
What is dithering? |
In order to reduce the effect of annoying correlated quantization distortion, dithering techniques can be applied. Thereto, prior to quantization, some random noise is added to the signal. It’s amplitude is large enough to reach different quantization levels. |
|
|
What is a better way to modulate signals than Pulse code modulation? |
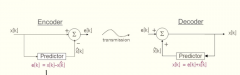
In order to reduce the data rate differential coding techniques can be applied.
The better the prediction, the smaller is the difference, the fewer bits are needed. Predictive coding is commonly used in audio and video compression (sources with high correlation), but is not suitable for the compression of text and executable code. |
|
|
Visualize differential pulse code modulation. DPCM |
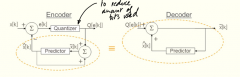
|
|
|
How to lower the quantization distortion level? |
Use oversampling to spread the energy of the quantization noise over a larger frequency range. oversampling with a factor of 4, means that one bit could be saved. Oversampling is typically combined with noise shaping |
|
|
How to implement noise shaping? |
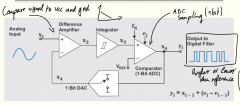
// Double check chapter 3 Use a delta-sigma converter. |
|
|
Why use non-linear quantization? |
more bits can be assigned to weak signal fragments if logarithmic quantization is used. This makes other operations more difficult however. |
|
|
what is µ-law and A-law encoding used for |
This is a non-linear encoding characteristic that can compress the signal to give similar quality with a lower number of bits. e.g. 8-bit A-law has almost the same quality as 12-bit linear. |
|
|
What is pre-emphasis? |
In a lot of applications signals are encountered that mainly contain low frequencies generally showing reduced amplitudes in the higher frequency range. A pre-emphasis filter can then be applied to the signal prior to quantization, transmission or processing. In this way, the effect of added noise can be reduced. |
|
|
How does sound propagate? |
Sound propagates as a longitudinal wave. This means that the direction of the wave propagation is the same as the direction in which the molecules are compressed and expanded. This is not the case for light and other types of electro-magnetic radiation, which are transversal waves. |
|
|
What is the speed of sound and how does it correlate with the wavelength? |
At room temperature and at normal pressure (1025 mbar) c = 340 m/s. c = wavelength*frequency |
|
|
What is the unit of sound intensity? why? What is the effect of its propagation |
The unit of Sound Intensity is W/m2. I = P*v watt/meter2 = force/area * distance/time -- Intensity drops with distance squared. |
|
|
What does dB SPL refer to? |
Decibel sound pressure level. For the denominator, a reference value is chosen. In the case of dB SPL, this reference value corresponds to the intensity that an average healthy listener needs to detect a 1kHz tone. |
|
|
When does a sound source behave as a point source? |
By computing the product of the wave numberk= (2*pi / wavelength) and a numberathat characterizes the length or the size of the sound source ka = (2*pi*a / wavelength), one can make predictions about the type of wave behavior. Rule of thumb: if ka is considerably smaller than 1, the source is likely to behave like a point source. |
|
|
What is beaming and when does it happen? |
When the sound source is large compared to the wave length, e.g. a musical instrument playing a high note, the wave propagates mainly in one direction. Rule of thumb: If kais considerably larger than 1, beaming is likely to occur. |
|
|
What is a shadow region and when does it occur? |
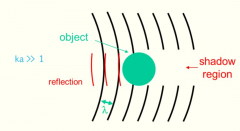
kais considerably larger than 1 : In case the object is large compared to the wave length, a "shadow" is created behind the object, i.e. there is no sound wave behind the object. Incident sounds are reflected. |
|
|
What is the acoustic impulse response of a room? |
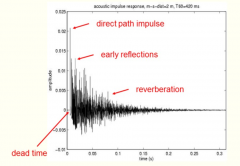
The sound propagation between source and listener can be characterized by the so-called acoustic impulse response of the room, which contains all information about the direct path propagation, the reflections and the absorption. The figure shows an acoustic impulse response. It consists of: 1. a dead time: the time needed by the direct sound to propagate from source to listener 2. the direct path impulse 3. the early reflections (1st, 2nd, …), which depend on the geometry of the room and the position of source and listener. 4. an exponentially decaying tail called reverberation, characterizing the contribution of the multiple reflections that reach the listener’s ear after some time. In practice, one measures the acoustic impulse response by making a sound recording of a gun shot (=impulse-like sound) in the room. When the gun is at the source position, a microphone located at the listener’s position will record the ‘acoustic response ’to this ‘impulse’. |
|
|
What is the reverberation time? |
The reverberation timeRTof a room is the time needed for the sound energy to decrease by 60 dB. |
|
|
How to convert mechanical vibration to a current for microphones? |
Use an electrodynamic microphone with moving coil: Vout = B*L*dx/dt L = length of the coil in the air gap. |
|
|
How to connect a condensor microphone to a PA system? |
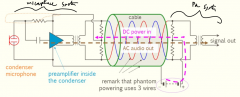
The most common way to connect to a condenser microphone is through a phantom power supply. As the supply voltage (DC) and the audio (AC) have a different frequency contents, they can be multiplexed on the same wires, without influencing each other. |
|
|
What is the disadvantage of a condensor microphone? how to solve this? |
A disadvantage of the condenser microphone is that relatively high voltages (up to 200 V) are required to polarize the capacitor plates This can be solved by covering one of the plates with a permanently polarized dielectric material (e.g. polytetrafluoroethylene = teflon), which provides a permanent electrostatic charge. Hence, there is no polarization voltage required anymore. This popular variant of the condenser is sometimes called an electret microphone. |
|
|
What are the two classes of microphone? |
Pressure and pressure gradient microphones |
|
|
What are the properties of a pressure microphone? |
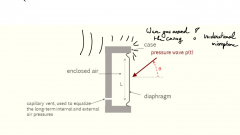
Unidirectional: the output level of a pressure microphone is independent of the angle of incidence phi (direction) For higher frequencies, the diaphragm and its encapsulation might act as an obstruction that reflects the sound waves. |
|
|
What are the properties of a pressure gradient microphone? |
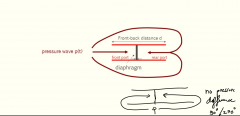
Also called velocity microphone. Not unidirectional: Bipole behavior The directivity of a pressure-gradient microphone is proportional to cos q, where q is the angle of incidence of the sound wave The output is Polarized. |
|
|
Explain the frequency response of a pressure gradient microphone. |
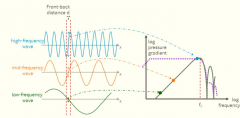
Observe that a pressure-gradient microphone inherently acts as a highpass filter : the output rises with frequency up to a critical frequency fc, for which the wave-length corresponds to twice the front-back distance d, i.e. fc= c/lambda*c = c/(2d). The highpass behavior can be compensated for by adding a (mechanical or electrical) 1st-order lowpass filter. In this way, an almost flat curve can be obtained. |
|
|
How to get a microphone with a cardiod response? |
Put a pressure and a pressure gradient microphone in one casing. Combining in equal amounts the omnidirectional response with that of a dipole produces a cardioid response : 0.5 + 0.5 cos delta Also known as a directional microphone. |
|
|
What types of responses exist next to a dipole, cardiod and omnidirectional response? |
Subcardiod response -> more ambience Supercardiod response -> more directional Hypercardiod response -> even more directional |
|
|
What is a cheaper way to get a cardiod response instead of using 2 microphones in one casing? |
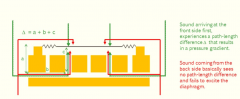
A fixed cardioid response can be obtained by creating a labyrinth that delays sound waves reaching the bottom part of the diaphragm. More advanced labyrinths can realize other responses. If the labyrinth is made user-controllable a multi-response microphone is created. |
|
|
What is a parabolic microphone? |
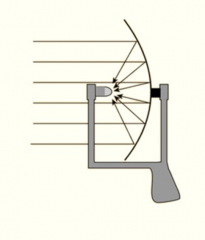
Very high directivety, but only works good for mid and high frequencies as low frequencies are not reflected as well. |
|
|
What is a shotgun microphone? rifle microphone, line microphone |

Long slotted tube for high directivity. Longer tube -> more directional |
|
|
Explain the following microphone characteristics: Polar pattern: cardiod Frequency range: 20Hz - 20kHz Sensitivity: 25mV/Pa (-32dBV) Max SPL: 145/155 dB (0.5% THD) Equivalent noise level: 19dB Signal/Noise ratio: 86dB Impedance: 200ohm |
The sensitivity of a microphone is the output voltage divided by the input sound pressure level. typically measured at 1kHz 94dB SPL 0dBV = 1V/Pa The output impedance of a microphone should be low, since a microphone is essentially a voltage source. Typical values are around 200 ohm (600 ohm is not professional !) The equivalent self-noise level of a microphone is defined as the sound intensity level of a noise field that would produce an equally strong microphone output as the internal noise. |
|
|
Describe the ideal frequency response of a microphone. What problems do we face in reality? |
The frequency response of a microphone should be as flat as possible, preferably for all angles of incidence (but certainly in the direction of maximum gain), and cover the range of human hearing (20 Hz – 20 kHz).
Why is the frequency response less flat at 90degrees? Higher frequency -> shorter wavelength -> microphone size becomes relevant. And the off axis response generates destructive interference
|
|
|
What causes the frequency dependency of the polar response of a microphone? |
For high frequency waves we get a shadow region due to refraction. For other frequencies the main effect is caused by destructive interference. Some parts of the diaphragm observe a decompression (delta p<0 Pa), other parts a compression (delta p<0 Pa). Since the diaphragm integrates pressure across its area, some cancellation takes place, leading to a loss of sensitivity. This effect decreases for waves with a very low frequency. |
|
|
Explain the proximity effect |
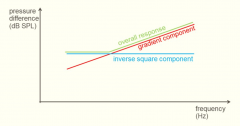
when a directional microphone is close to the source, an extra boost at low frequencies is observed. |
|
|
Explain the working principle of a loudspeaker. |
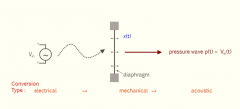
A loudspeaker is a compound transducer that converts an electrical signal into a sound wave: 1. The electrical signal Vin(t) provokes a mechanical vibration x(t) of a diaphragm. 2. The mechanical vibration creates a sound pressure wave p(t). Ideally, p(t) is proportional to the input signal Vin(t). |
|
|
What are the design implications of a loudspeaker? |
Vm = omega * Dm Velocity and Displacement In order to obtain the same particle velocity (same pressure) the particle displacement needs to be bigger at lower frequencies However, large displacements can damage the diaphragms. So large diaphragms are required. Big diaphragms cause more beaming for higher frequencies. Also big diaphragms have a worse high frequency response because of their slower motion. Solution -> use multiple diaphragms (tweeter, woofer) |
|
|
Why do we need crossover circuits? |
Crossover circuits are employed to filter the input signal and send specific frequency components to a dedicated speaker. Otherwise you would have interference from multiple speakers playing the same frequencies. |
|
|
Why do speakers require enclosures? |
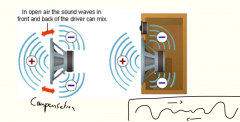
The major role of the enclosure is to prevent that the negative phase sound waves from the rear of the speaker would combine with the positive phase sound waves from the front of the speaker. This would result in cancellation and interference patterns, causing the efficiency of the speaker to be compromised. With a closed-baffle enclosure for instance, cancellation of the sound can be avoided. A side-effect, however, is that the low-frequency response of the loudspeaker typically becomes worse. More advanced enclosures (e.g. bass reflex) are then called for |
|
|
What is thermal compression of speakers? |
Due to non-zero resistivity the coil warms up at high power levels. This increases the resistivity further and hence reduces the acoustic sound output. |
|
|
Explain common speaker characteristics: Description: 2-way system Frequency response: 46Hz - 25kHz +-3dB on reference axis Frequency range: -6dB at 43Hz and 50kHz Sensitivity: 89dB SPL (2.83V, 1m) Efficiency: 1.5% Harmonic distortion: <1% 90Hz - 20kHz <0.5% 150Hz - 18kHz Power handling: 50W - 120W into 8 ohm Directivity: explained elsewere |
2-way refers to 2 diaphragms Frequency response on reference axis refers to someone standing right in front of the speaker. The Sensitivity corresponds to the sound intensity for a given voltage at the input. In order to measure the sensitivity, typically, a pink noise signal of 1 Watt (i.e. a voltage of e.g. 2.83 Vrms applied to a nominal impedance of 8 ohm) is put into the loudspeaker. Then the sound pressure level (dB SPL) is determined at 1 meter in front of the speaker. Pink noise provides equal sound energy in each octave or decade. Another performance parameter is the efficiency, which is the ratio of the acoustic power (out) to the electric power (in). Note that loudspeakers are very inefficient devices. The efficiency is typically between 1 and 3%. The remaining 97 to 99% is transformed to heat. Most distortion occurs at low frequencies as a consequence of large diaphragm excursions (this explains the better performance above 150 Hz). Obviously, the distortion will increase with sound intensity, so it is important that the conditions (here: 90 dB SPL) are mentioned. Power handling is the maximum power a loudspeaker can handle before unacceptable distortion or overheating occurs. It appears to be an illdefined rating. |
|
|
Explain the dispersion parameter of a speaker e.g. within 2dB of reference response Horizontal: over 40 degrees arc Vertical: over 10 degrees arc |
Directivity (also called dispersion) describes the angle of coverage of the loudspeaker output. This means that there is no more than 2 dB variation within the given angles. Vertical dispersion is lower because the listener is typically not far off from the vertical level of the speaker. |
|
|
Why should a speaker have a low input impedance? |
The amplifier’s output impedance should match the load impedance for optimal power transfer The loudspeaker is not purely resistive, impedance ZL is complex-valued and strongly varies with frequency In practice, one does not take the frequency dependence of |ZL| into account and simply works with the average value, the so-called nominal impedance RN. |
|
|
How does a stereo speaker setup work? |
By using two loudspeakers the customer can be given a more natural listening experience by appropriately setting the relative gain of the left and the right channel a virtual source can be created. The listener has the impression that the sound comes from the virtual source location. At low frequencies, the sound from the loudspeakers reach the ears nearly unaltered. A delay exists, however, between the left and right speaker contribution due to the difference in path length. -> interaural phase difference At high frequencies, head-shadow effects play an important role. Sound waves from a speaker hardly reach the contralateral ear. In the example, the right speaker emits a weaker sound, resulting in an interaural intensity difference. |
|
|
How do people localize sound? |
The two primary cues that are used by humans to localize sounds are the interaural time and interaural intensity difference. We can also detect an interaural phase difference. at low frequencies we use phase differences at high frequencies we use amplitude differences because the phase is ambiguous |
|
|
Explain the differences between physical and psychophysical |
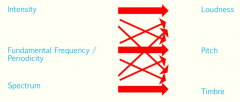
|
|
|
what is loudness? |
An attribute of auditory sensation which can order sounds on a scale from quiet to loud perceived loudness is not only intensity but also frequency dependent. |
|
|
To what frequencies is the human ear most sensitive? |
the human ear is most sensitive to frequencies around 3000 - 4000 Hz. |
|
|
What does the 30 phon curve express? |
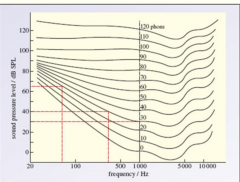
it was determined which intensity level (dB SPL) was needed to produce a sound that sounds equally loud as the 30 dB SPL 1 kHz wave. The loudness level of a sinusoidal wave is expressed in phon : a sinusoidal wave of x phon sounds equally loud to an average young adult listener as a 1 kHz sinusoid with an intensity of x dB SPL. |
|
|
What is needed to measure loudness with sound level meters? |
A weighting filter is required. Typically this is the 'A' weighting filter which is modelled after the inverse 40 phon curve. |
|
|
What does dBA express? why does dBB and dBC exist? |
Loudness weighted with an 'a' filter is expressed in dBA, but also 'b' and 'c' filters exist. |
|
|
Define pitch |
the attribute of a sound used to rank it from low to high. |
|
|
explain the missing fundamental effect |
it is not the frequency component at the fundamental frequency that matters, but the distance (in Hz) between the harmonics! melody and thus pitch can sound the same even with a missing fundamental. |
|
|
Why does helium affect pitch? |
The fundamental frequency is still the same! Indeed, the vocal chords do vibrate at exactly the same frequency as with normal air. because those lighter-than-air helium molecules allow sound to travel faster and change the resonances of your vocal tract by making it more responsive to high-frequency sounds and less responsive to lower ones. -> The spectral composition changes but not the fundamental frequency |
|
|
Define timbre of sound. |
different sounds with the same pitch and loudness have a different timbre timbre is highly related to the envelope and partly related to the spectrum of a sound |
|
|
What are the localization cues for sound? |
Interaural Time Difference is mainly used at low frequencies. Interaural Intensity Differences are mainly used at high frequencies. The third cue is the head-related transfer function (HRTF) The pinna and head affect the intensities of frequencies. Measurements have been performed by placing small microphones in ears and comparing the intensities of frequencies with those at the sound source. spectral cue Direct/reflection ratio: The ratio between direct sound and reflected sound can give an indication about the distance of the sound source. Loudness: Distant sound sources have a lower loudness than close ones. Sound spectrum : High frequencies are more quickly damped by the air than low frequencies. Therefore a distant sound source sounds more muffled than a close one, because the high frequencies are attenuated. The Initial Time Delay Gap describes the time difference between arrival of the direct wave and first strong reflection at the listener. Nearby sources create a relatively large ITDG, with the first reflections having a longer path to take, possibly many times longer. When the source is far away, the direct and the reflected sound waves have similar path lengths. Movement: Similar to the visual system there is also the phenomenon of motion parallax in acoustical perception. For a moving listener nearby sound sources are passing faster than distant sound sources. Level Difference: Very closely sound sources cause a different level between the ears. |
|
|
Explain the precedence effect or the haas effect |
Humans hear the directionality of a sound by processing the time delays between audio arrivals at each ear, as opposed to hearing two separate sound In fact, a sound from another direction arriving within 5 to 30 milliseconds can be up to 10 dB louder than the original (over twice as loud), without the listener perceiving this as a second sound event. Dr. Haas determined that if the arriving sounds are farther apart than 40 milliseconds, humans will perceive an echo, since the brain will have had time to process the two signals separately. |
|
|
How does frequency masking work? |
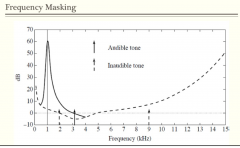
Sound perception alters if other sounds are present. It is well known from psychophysics that sounds can make other sounds inaudible. This phenomenon is called masking. Frequency masking If they are combined the overall masking threshold in presence of all maskers is obtained. Combination with the threshold of hearing in silence (also called absolute hearing threshold ) gives the globalmasking-threshold (= masking + absolute-hearing-threshold) curve. |
|
|
What is perceptual coding? |
If the quantization noise is inaudible, then the original signal sounds the same as the quantized signal! perceptual coding techniques : use as few bits as possible to represent the signal while keeping the quantization noise inaudible. the first step is splitting up the (music) signal in different non-overlapping frequency bands or subbands. After subband filtering, the samples are grouped. Further processing is done in groups of 12 samples (for transient sounds) or 36 samples (for stationary sounds). For each group of samples in each subband the mask level is computed. It is the highest signal level that can be tolerated before the signal in that subband becomes audible. Then, for each subband the mask level is computed. If the signal level is below the mask level (SMR < 0 dB), this means that the signal is inaudible |
|
|
how is mp3 achieved? |
// |
|
|
Explain gamma correction |

gamma correction is used to correct the gamma distortion of a monitor |
|
|
What is logarithmic compression? |
This image transform is similar to gamma < 1 and will compress the dynamic range of the image. |
|
|
How to do a contrast-stretching transformation? |
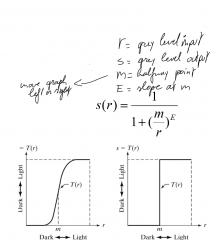
The contrast-stretching transformation will stretch a specific intensity range to the complete (or just a bigger) range of the image. sometimes a very small epsilon is added to r to prevent division by 0 |
|
|
How does histogram equalization work? |
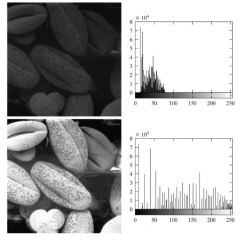
First calculate the cumulative distribution of intensities. Multiply this cumulative distribution with the number of grey levels - 1 Histogram equalization does not allow interactive image enhancement and generates only one result: an approximation to a uniform histogram. map these new values on the original distribution of intensities. The new image will have enhanced contrast |
|
|
What are the steps of histogram matching? |
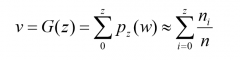
Step 1: Equalize the levels of the original image Step 2: Specify the desired density function and obtain the transformation function G(z): Step 3: Apply the inverse transformation function z=G-1(s) to the levels obtained in step 1. |
|
|
Explain smoothing spatial filters |

– Used for blurring (removal of small details prior to large object extraction, bridging small gaps in lines) and noise reduction. – Low-pass (smoothing) spatial filtering – Neighborhood averaging |
|
|
Explain sharpening spatial filters |

Sharpening filters determine the 2nd order derivative of the image to find the edges of the image. we can substract these edges from the original image to sharpen it. |
|
|
explain median filtering |
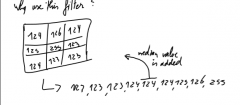
median filtering is similar to other smoothing filters, but we use the median value instead of the mean of the matrix. This works much better for images that are contaminated with so called salt and pepper noise |
|
|
Properties of the 2d fourier transform |
// |
|
|
How does filtering in the frequency domain work? |
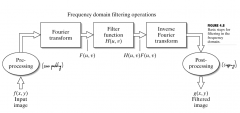
|
|
|
How to obtain frequency domain filters from spatial filters? |
// sobel kernel for vertical edge detection [ -2 +0 +2 ] [ -1 +0 +1 ] [ -2 +0 +2 ] |
|
|
How to make filters directly in the frequency domain? |

Create Meshgrid Arrays for use in implementing filters in the frequency domain |
|
|
What are the problems with lowpass frequency domain filtering of images? |
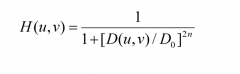
We get ringing artifacts due to the sidelobes of an ideal filter -> better use filter with butterworth profile. (see image) higher order -> more ringing. another possible filter is the gaussian filter. which uses a distribution similar to a normal distribution and has no ringing |
|
|
how to implement highpass frequency domain filtering of images? |
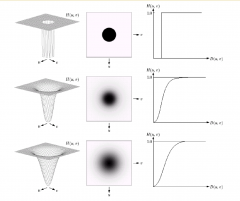
Zero-phase-shift filters: radially symmetric and completely specified by a cross section. Hhp(u,v)=1=Hlp(u,v) filters are the inverse of the corresponding low pass filters and attenuate the low frequencies while keeping the edges intact. |
|
|
What is a high frequency emphasis filter? |
// ch4 p59 |
|
|
list the different geometric transformations or rubber-sheet transformations. and give their affine matrix |
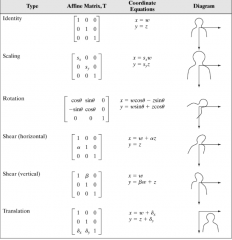
Identity Scaling Rotation HShear VShear Translation |
|
|
Explain how a shearing transformation works. |
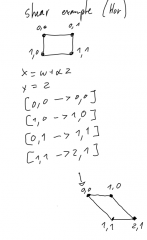
|
|
|
What is image registration? |
Image registration methods align two images of the same scene • Same time different modalities (PET and MRI) • Different times same scene (satellite images) |
|
|
How are RGB images represented? |
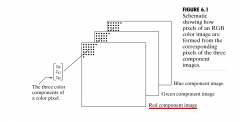
RGB images are images with 3 color components. This gives a M x N array x 3 components If we have 8-bit color -> 8-bit per component is (2^8)^3 is around 16 million colors |
|
|
How can color images be represented with an index? |
–datamatrix (M x N) of integers –colormapmatrix (m x 3) with m: # colors get integer from data matrix -> check the index of this integer in the colormap matrix to get its rgb values. |
|
|
Why do we need CMYK in addition to RGB. Why is K needed |
Printers require CMY, because they work substractive. Black = C=M=Y=1 but this is muddy black -> K is added as true black RGB can be converted to CMY by substraction from 1. |
|
|
What does the HSI color space express? |
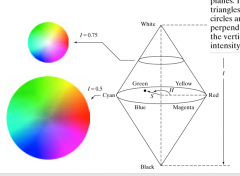
•Hue,Saturation, Intensity (HSI) color space – Naturaland intuitive to human interpretation – Hue:pure color – Saturation:degree of dilution by white light – Intensity:achromatic notion of intensity% |
|
|
Strange effect of HSI with red pictures |
Because the middle of red is at 0 degrees. high intensity differences for slight variaties of red. |
|
|
How to do color balancing or color correction? |
–Mapcolor components individually => with RGB color space –Photoenhancement •Lookat background color •Lookat skin –Increase the amount of a color => in CMY•Decrease the amount of complement color•Increase the two immediately adjacent colors |
|
|
How does image segmentation in RGB Vector space work? |

Twopixels are similar if the Euclidean distance D is smaller than a threshold T •Imagesegmentation in RGB 1.Extractinga region of interest (ROI) 2.Extractingthe mean and the standard deviation from the pixels of the ROI 3.Establishinga Threshold, say 5 times the maximum standard deviation. 4.Identifyall pixels within the that sphere |
|
|
How does a 1D discrete wavelet transform work? |
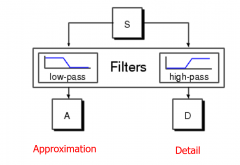
|
|
|
How does a 2D discrete wavelet transform work? |
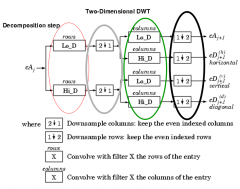
picture gets divided into approximation, horizontals, verticals and diagonals |
|
|
Give some 2D wavelet applications. |
–De-noisingwith wavemenu –Filteringby setting all values of a level to zero –Progressivereconstruction –compression Highpass filter: set approximation to zero -> edge filtering Lowpass filter: set 3 detail levels to zero -> smoothing |
|
|
Explain huffman coding. |
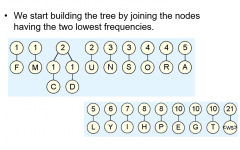
Lossless encoding Try to find the least amount of bits required to represent the information. |
|
|
What is interpixel redundancy and how does it work? |
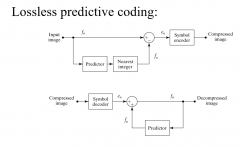
Form of lossless predictive coding. only store the difference in pixel value of neighbouring pixels instead of the absolute value. This reduces the necessary amount of pixels |
|
|
How does JPEG compression work? |
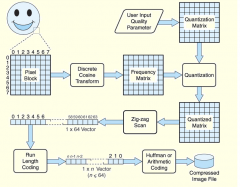
•Preprocessing –Shift values •e.g. if (P=8), shift [0, 255] to [-127,127] - DCT requires range be centered around 0 –Segment each component into 8x8 block •Convert from spatial to frequencydomain –convert intensity function into weightedsum of periodic basis (cosine) functions –identify bands of spectral informationthat can be thrown away without loss of quality • Discrete cosine transform •Divideeach coefficient by integer [1, 255] –comesin the form of a compression table, same size as a block –dividethe block of coefficients by the table, round result to nearest integer •EntropyEncoding –lossless Compresssequence of quantized DC and AC coefficients from quantization step –SeparateDC from AC components •DCcomponents change slowly, thus will be encoded using difference encoding •DCEncoding –DCrepresents average intensity of a block•encodeusing difference encoding scheme–Becausedifference tends to be near zero, can use less bits in the encoding •ACencoding –Usezig-zag ordering of coefficients •ordersfrequency components from low->high •producemaximal series of 0s at the end –Applyrun-length encoding (RLE) to ordering or apply end-of-block symbol •Huffmancoding –Sequenceof DC difference values along with RLE of AC coefficients –ApplyHuffman encoding to sequence – Exploits sequence’s statistics by assigningfrequently used symbols fewer bits than rare symbols •Attachappropriate headers •Finallyhave the JPEG image! |
|
|
Explain dilation |
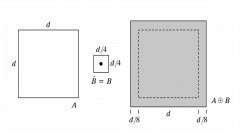
1.Applyreflection to the structuring element B 2.Placea copy of the flipped B sothat some parts of Btouches A 3.Theorigin of the flipped B isin the dilation of A by B Expands the boundary of A |
|
|
Explain erosion |
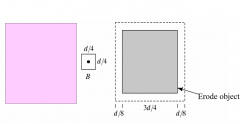
1.Placea copy of the structuring element Bso that it entirely fits inside A 2.Thepixel marked by the origin of Bis in the erosion of A by B Contracts the boundary of A |
|
|
What does an opening operation do? |
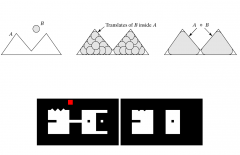
Erosion followed by dilation. Smoothes contour. Removes small islands and sharp peaks. |
|
|
What does a closing operation do? |
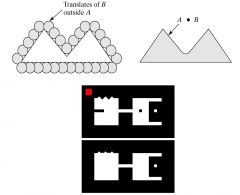
Dilation followed by Erosion. Smoothes contour. Eliminates small holes Fuses narrow breaks and thin gulfs |
|
|
How does boundary extraction work? |
If we erode an image and then substract this eroded version of the original image we are left with the boundary of the original image. |
|
|
What does morphological reconstruction achieve? |

•initializeh1 to be f •createstructure element B: ones (3) •repeat until hk+1= hk••markerfmustbe subset of g |
|
|
How to fill holes using morphological reconstruction? |
marker: 1'sin the border(startgrowing from thebackground) grow on the inverse of the image gets all the background pixels connected. leaving out-foreground & holes |
|
|
How to remove border object using morphological reconstruction? |
Mark border of entire image Grow on image to obtain all objects at border. Substract this image from original to remove border objects. |
|
|
How does dilation and erosion work for grayscale images? |
Dilation-> local maximum over domain Gives higher intensity image that is slightly blurred. Erosion-> local minimum over domain Gives lower intensity image. |
|
|
What does the morphological gradient give? |
Dilation - Erosion = max - min |
|
|
How to do the opening and closing operator on grayscale images? |
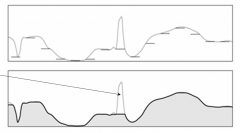
Look at the intensity graph of one slice of the image and apply the operator on that slice. |
|
|
How to transform image to black and white with nonuniform background? |

apply Opening to the image and substract this from the original |
|
|
How to measure size distribution of objects in an image? |
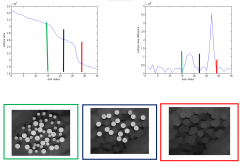
•Applyopening with different b size •computesum of pixel values sometimes called surface area •evaluatethe reduction in surface area –whenstrong reduction occurs means large number of objects have that radius |
|
|
How to do point detection in images? |
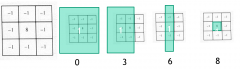
|
|
|
How to do line detection in images? |
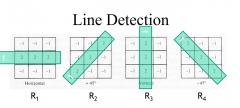
|
|
|
How does edge detection work? |
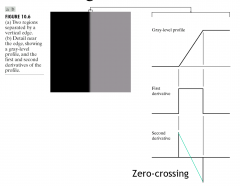
We can calculate the partial derivatives to x and y for z for any intensity map of an image. The combined vector is called the gradient and points in the direction of the highest change We can draw a line perpendicular to this vector to indicate the edges of an image. |
|
|
What are the different thresholding methods? |
global thresholding •To partition the image histogram by usinga single threshold T.» •Then the image is scanned and labels areassigned.» •This technique is successful in highlycontrolled environments. Otsu's method is better when the boundary between objects is less pronounced. |
|
|
Explain global thresholding. |
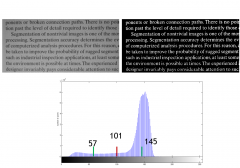
1.select the initial estimate for T (midvalue) 2.segment using Tproducing G1(>=T) andG2. 3.compute average µ1 and µ2 4.T =1/2 (µ1+ µ2)repeatuntil the difference in T is small |
|
|
Explain otsu's method for thresholding |

|