Reading...
![]()
Play button
![]()
Play button
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
30 Cards in this Set
- Front
- Back
- 3rd side (hint)
|
How big is the human genome?
How many nucleotides need to be copied for each cell division? How many cells are in a human? How many times does each cell divide in our lifetime? __ Can this create any problems with replication? |
Immense Size (2.9 billion bp/haploid)
-That means that for each pair of chromosomes there are about 6 billion base pairs -When we replicate DNA we have to replicate both strands -That’s 12 billion nucleotides that have to be copied for EACH cell division!! -A human is somewhere on the order of 10^13->10^14 total number of cells -In our lifetime our cells undergo a total of 10^15->10^16 cell divisions -What that means is that if you make any small number of errors, for example, let’s say something like 1/10,000,000x you make an error in copying the DNA, that results in a tremendous number of errors accumulating by the time you get to an embryo that an embryo will most likely be nonfunctional if you make a mistake at that rate |
|
|
|
When the full genome is replicated probably it’s not going to do it to complete perfection, perhaps a few errors arise but not a tremendous number like 1/10,000,000.
How do we keep that to a minimum? |
-The maintenance of DNA means constant changes without which the organism cannot survive
-In any particular species including the human species we have a gene pool and something like the sickle cell anemia gene, even though it may be detrimental in the homozygous form its existence in the gene pool can for example promote resistance to malaria and enhance survival. -->That’s why you have the sickle cell gene there -By the same kinds of selective conditions particular alleles in the gene pool can come to predominance and serve a purpose in a particular species |
|
|
|
What are the accidents that can happen because of the way that maintenance of DNA takes place?
|
-See a wide spectrum in the diseases because, for example, when replication collides with a DNA lesion, it’s going to have to lead to repair.
-There has to be a signal transduction pathway that originates there and results in a wide range of physiological responses -One option can be recruit/repair enzymes and resume DNA replication -Bypass DNA lesion somehow -If you have a trainwreck in replication, you might want to abort the cell --> cause apoptosis rather than accumulate mutations -When we have cancer we can have a defect in those types of signal transduction pathways -Remember that, for the most part, your somatic cells are identical in sequence to your germ cells -The reason why you want to avoid mutations for the organism as a whole is that you want all of the cells to work in a concerted fashion. You want it to respond to cellular signals in a coordinated fashion. You want the biological organism to reproduce and allow the germline cells to continue on -If you have a somatic cell that accumulates too many mutations you want to kill that cell off rather than allow it to continue -This is a classic example of group selection where what you want to do is convey that genome |
|
|
|
Review the General Properties of DNA Replication
|
A. The basic reaction.
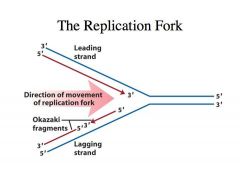
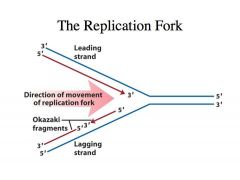
-The substrate for DNA synthesis is the deoxynucleoside 5'-triphosphate (dNTP). -The 3' hydroxyl group of the growing polynucleotide chain makes a nucleophilic attack on the α-phosphate of the incoming dNTP, incorporating the nucleotide and releasing inorganic pyrophosphate. B. DNA replication is semi-conservative. Each strand of the DNA helix serves as template for the synthesis of a new strand. After one complete round of chromosomal replication, each daughter chromosome has one parental strand and one newly synthesized strand. C. DNA replication begins at an origin and proceeds bidirectionally from that site. D. The replication fork. DNA synthesis proceeds by the propagation of the replication fork, at which the parental strands are unwound and replicated. E. Even though the polymerization of nucleotides occurs only in the 5' to 3' direction, both strands are being simultaneously synthesized as the replication fork progresses. F. DNA synthesis at the replication fork is semi-discontinuous as it progresses through anti-parallel DNA. 1. Leading strand synthesis. -->Continuous DNA synthesis on one strand in a 5' to 3' direction. 2. Lagging strand synthesis. -->DNA synthesis on the other strand is catalyzed discontinuously in small fragments, typically 200 to 2000 bases in length. -->These fragments have short RNA segments at the 5' ends. -->Synthesis of these fragments begins with the synthesis of a short RNA primer. -->There is then a transition to DNA synthesis to complete the synthesis of the fragment, which is called the Okazaki fragment. -->The RNA primers are subsequently removed, the gaps filled in by DNA synthesis, and adjacent Okazaki fragments are joined together to form a continuous strand. |
|
|
|
Describe elongation of a DNA chain
|
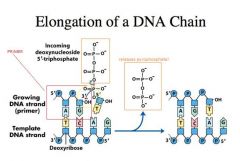
-DNA polymerase polymerizes nucleotides using a DNA template
-DNA polymerase is like glycogen synthase -It cannot start a DNA chain de novo **RNA polymerase CAN start a chain de novo -If we have a pre-exiting polynucleotide chain or what we call a PRIMER, then what DNA polymerase can do is bind to the primer template and it can choose a deoxynucloeside triphosphate based on base pairing with the DNA template -The DNA template must be exposed and single stranded for it to be able to do so -If we have a TTP residue coming into this particular site, the active site of polymerase (circled) bound to the primer template, if the TTP fits into the active site neatly then what happens is that the OH group of the pre-existing polynucleotide chain or the primer is activated as a nucleophile and the alpha phosphate becomes perfectly aligned with this OH so that now we do a typical SN2 nucleophilic substitution that we were talking about. -We form a new linkage between the OH and the phosphate at the expense of the energy that comes from the alpha-beta phosphoryl anhydride linkage and then a pyrophosphate is released to do DNA synthesis |
|
|
|
How do DNA synthesis reactions compare in vivo and in vitro?
|
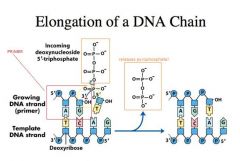
-We can do DNA synthesis reactions in vitro, and in vitro this reaction is REVERSIBLE.
-Once you accumulate enough pyrophosphate and DNA template you can do the reaction in reverse. -If you do PCR reactions there is a particular point where you accumulate so much pyrophosphate and DNA template that polymerase tends to do the reverse reaction instead of the forward reaction __ -In vivo, this is irreversible because pyrophosphate will immediately cleave into two inorganic phosphates -Various polymerases have different fidelity of choosing the right nucleotide. -The Km for the right nucleotide is very low and the Vmax is very high, but the wrong nucleotide can still come in and be incorporated at a low frequency with a Km that is very high and a Vmax that is very low |
|
|
|
What does it mean when we refer to DNA synthesis as “semi-conservative"?
What would it look like if DNA synthesis were conservative? |

-When we do DNA synthesis it’s called “semi-conservative”
-The DNA template, eg. in a bacterial chromosome like e.coli is typically circular. -There is usually one origin of replication -As we initiate replication and do new replications, we get bidirectional DNA replication emanating from the origin -->Blue is the parental DNA -->Red is the newly synthesized DNA -When we complete replication we have two daughter chromosomes **It is semi-conservative because each daughter chromosome is half red and half blue** -The newly synthesized DNA remains hydrogen bonded to the parental DNA -In transcription if you make an error the RNA just peels off and if you make a mistake there is nothing to go back and proofread to see if an error has been made. -In this case where we have semiconservative replication, if there were and error there would be a bulge where a mismatch has taken place or where the error has been made -This gives the repair apparatus a chance to bind to that particular site and correct the mismatch -This has tremendous ramifications in allowing for fidelity of DNA replication __ Conservative replication -->You would have one totally blue chromosome and one totally red chromosome -->The newly synthesized progeny DNA would be completely newly synthesized, there would be no parental DNA attached to it |
|
|
|
Where does DNA replication begin?
How does this compare in bacteria and eukaryotes? |
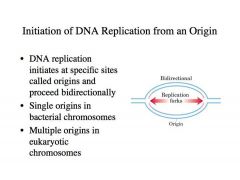
-Initiation of DNA replication from an Origin
-Usually create two replication forks at an origin -DNA replication initiates at specific sites called origins and proceeds bidirectionally -As we pull the parental strands apart, each parental strand that is exposed and made single stranded at the replication fork gets simultaneously replicated BACTERIA: -Single origins in bacterial chromosomes -In the circular bacteria chromosomes, we generally have single origins or very few -Typically a bacteria will have one chromosome, although there are examples of bacteria with multiple chromosomes EUKARYOTES: -Multiple origins in eukaryotic chromosomes -Eukaryotes tend to have multiple, large chromosomes -Each chromosome tends to have multiple origins -The replication fork tends to move more slowly than the bacterial replication fork, probably for purposes of higher fidelity of replication -If you have a lot of DNA you have to be more careful about copying it or the collaboration between genes could easily fall apart with the introduction of mutations |
|
|
|
Typical speed of the replication fork in prokaryotes? Eukaryotes?
|
1. Prokaryotes.
-->As fast as 60,000 bases per minute. 2. Eukaryotes. -->Slower than prokaryotes, 500 to 5000 bases per minute. |
|
|
|
What are the basic enzymes we need to keep in mind at the replication fork?
|
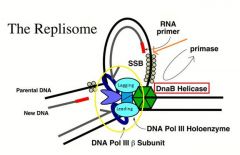
The enzymes at the replication fork.
1. The DNA polymerase III holoenzyme. -This is a complex enzyme with multiple subunits. -One subunit has the active site for the polymerization of nucleotides. -Another subunit has the 3' to 5' exonuclease for proofreading. -Other subunits control the processivity of the DNA polymerase and arrange holoenzyme as an asymmetric dimer. -One side of the DNA polymerase is highly processive, suited for leading strand synthesis. -The DNA polymerase at the other side is suited for lagging strand synthesis, suited for multiple associations and dissociations from the template necessary for multiple rounds of Okazaki fragment synthesis. -Anchored to the polymerase for leading strand synthesis, the lagging strand polymerase can be efficiently recycled for repeated rounds of DNA synthesis. 2. Helicase. -DNA polymerases cannot catalyze DNA synthesis through a duplex region. -The helicase serves to unwind the DNA helix for the progression of the fork. 3. Primase. -This enzyme catalyzes the synthesis of RNA primers that initiates each round of Okazaki fragment synthesis. 4. Single-strand binding protein or helix-destabilizing proteins. -These proteins quickly coat single-stranded DNA created during the propagation of the replication fork. -These proteins serve a number of functions. -For example, one major function is to maintain the lagging strand template in a fully single-stranded configuration so that lagging strand synthesis can proceed unimpeded. 5. Topoisomerase. -The movement of the replication fork causes the region ahead of the replication fork to become overwound or positively supercoiled. -A topoisomerase is required to relieve this superhelical strain for the progression of the fork. 6. DNA polymerase I. -This is a DNA polymerase of relatively low processivity, having 3' to 5' and 5' to 3' exonuclease activities. -The 5' to 3' exonuclease activity functions in the removal of the RNA primer. -The DNA polymerase can serve to fill in the small gap created by the removal of the RNA primer, using the adjacent Okazaki fragment as primer. -The relatively low processivity is well suited for repairing such small gaps. 7. DNA ligase. -The enzyme that seals the nicks between the Okazaki fragments to make a contiguous strand of DNA. |
|
|
|
As we pull the strands apart at the replication fork exposing single strands of DNA, how do we efficiently copy both strands of the parental DNA (the blue DNA) simultaneously?
|
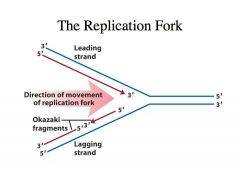
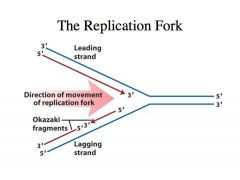
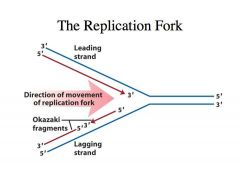
The problem:
-We have duplex DNA -DNA is antiparallel -If the one strand goes from 3’ to 5’, the complementary strand is of opposite polarity -All RNA polymerases and all DNA polymerase polymerize nucleotides (nucleoside triphosphates) in a 5’ to 3’ direction where the 3’ OH of the preexisting chain is always the next nucleophile that is going to attack the alpha phosphate of the nucleoside triphosphate -If you look at the leading strand, as we expose single stranded DNA at this fork, you can see that the polymerase that is highly processive and can continually polymerize nucelotides as this DNA helix is being unwound -The DNA polymerase that is catalyzing this DNA synthesis in the leading strand is highly processive. -It can catalyze the polymerization of almost infinite numbers of nucleotides without dissociating from the template. -This makes it very efficient because you don’t need to have a polymerase that comes off each time it polymerizes a nucleotide. -You can very QUICKLY replicate the DNA -This is very convenient because the direction of polymerization is in the same direction as the movement of the fork or the unwinding of the DNA helix -This is called the leading strand in DNA synthesis because the DNA synthesis on this strand happens first but DNA synthesis on the other strand LAGS behind Why does synthesis on the other strand lag behind? |
-As we expose single stranded DNA we have to catalyze DNA synthesis on this strand.
-Because polymerase adds nucleotides in the 5’ to 3’ direction, it has to go in the direction opposite to the movement of the fork -Thus, DNA synthesis on the lagging strand takes place in the form of small fragments called OKAZAKI FRAGMENTS -Every time single stranded DNA is exposed, polymerase cant catalyze synthesis de novo, so an enzyme called PRIMASE comes in, and it will synthesize a primer on the DNA template and then DNA polymerase will extend it -Then it comes and collides with the previous Okazaki fragment -Once more single stranded DNA is exposed by leading strand synthesis, a primase will come in and prime another round of Okazaki fragment synthesis |
|
|
Processivity
|
-The ability to polymerize nucleotides successively without dissociating from the template
-Both the DNA polymerases for leading and lagging strand syntheses are highly processive -Leading strand polymerases will polymerize DNA almost infinitely -Lagging strand polymerases are also highly processive, but it is designed to disengage as it meets the next Okazaki fragment and go to the next RNA primer for the next Okazaki fragment synthesis |
|
|
|
Size of Okazaki fragments:
in bacterial cells? in eukaryotes? |
in bacterial cells
-1-2 kb in length -very tiny compared to size of genome In eukaryotes -Typically smaller, about 200 or so bases in length |
|
|
|
Why have a primase?
|
-One of the problems is that we have to do lagging strand synthesis in short spurts and the polymerase can’t continuously catalyze
-DNA synthesis on the lagging strand -As it completes one Okazaki fragment it has to detach and go to the next Okazaki fragment -Lagging strand keeps up with leading strand synthesis somehow!! -->For that, we have to understand the replication apparatus |
|
|
|
Why do we make it in the form of Okazaki fragments?
|
-The RNA primers are going to be removed eventually and then the DNA polymerase is going to fill in the gap and do the repair
-Every new chain (in both the leading and lagging strands) is started with an RNA primer at the origin of replication -When you polymerize a nucleotide, you have to align the OH group of the preexisting chain together with the incoming nucleoside triphosphate. -If the nucleoside triphosphate fits perfectly into the primer template polymerase active site, the alpha 3’ OH will be perfectly aligned with the alpha phosphate to promote polymerization of the nucleotide -However when you start a new chain with RNA polymerase and you align two nucleoside triphosphates together, that 3’ OH is not going to be perfectly rigid in its positioning. It can move quite a bit on the DNA template. The alignment does not need to be perfect to form the first dinucleotide -When you first start the dinucleotide chain de novo, there is a very large chance for ERROR BUT this doesn’t matter when we do Okazaki strand synthesis or we start leading strand synthesis with a primase is because an RNA primer is ALWAYS destined for removal. -It has to be removed and corrected and filled in with a DNA polymerase -Any error made by primase will be erased and so the replication machinery goes through this awkward process for the purpose of maintaining fidelity of DNA replication |
|
|
|
Summarize the attributes of DNA polymerase
ie. In what direction does it polymerize? |
-5’ to 3’ direction
-Requires a DNA template -Requires a primer -->All DNA polymerases are unable to initiate a DNA chain. -->DNA polymerase can only add deoxynucleotides to a preformed nucleic acid chain termed a primer. -->This is in contrast to RNA polymerase which can initiate the synthesis of a new polynucleotide chain at the promoter. Processivity -The ability to polymerize nucleotides successively without dissociating from the template -Both the DNA polymerases for leading and lagging strand syntheses are highly processive -Leading strand polymerases will polymerize DNA almost infinitely -Lagging strand polymerases are also highly processive, but it is designed to disengage as it meets the next Okazaki fragment and go to the next RNA primer for the next Okazaki fragment synthesis |
|
|
|
What is nucleotide discrimination?
How is this accomplished? |
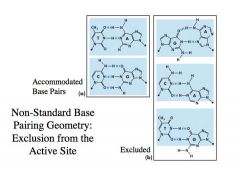
NUCLEOTIDE DISCRIMINATION:
-->the polymerase at the replication fork will have high discrimination of nucleotides to be as accurate as possible -There are about 15 different DNA polymerase encoded in the human genome -Some of the polymerases have LOW fidelity and even though they have low fidelity they serve the function of assuring high fidelity of copying the DNA -Still, we cannot achieve complete accuracy --> One issue is that nucleotides undergo tautomeric transition |
|
|
|
What happens when cytosine undergoes a tautomeric transition?
|
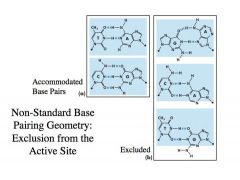
Nucleotides undergo tautomeric transition
Eg. C –tautomeric transition-> base pair with A and look like an A-T base pair -With just tautomerism being considered, a polymerase would make a mistake 1/10,000 times -By doing this discrimination very carefully as polymerase does, we can increase the fidelity of replication 10-100 fold -->Still, this means polymerase makes a mistake 1/1,000,000 times -If you think about 12 billion nucleotides having to be copied for one cell, you can see that a polymerase that makes a mistake 1/1,000,000 times is too inacurate to support a viable cell. -So, how do we get to a system that copies the DNA and make only a handful of errors for every cell division? -What is depicted in the blue frame is the active site for DNA polymerase in the primer-template active site complex -When you have a Watson-Crick base pairing as shown on the left, template C and the incoming dGTP nucleotides will fit perfectly into the active site so that the OH of the growing polynucleotide chain will attack the alpha phosphate of the nucleoside triphosphate -That perfect alignment will allow polymerization to occur very efficiently -This does NOT mean that non-Watson-Crick base (on the right) cannot take place -->For example, an A residue can base pair with a G residue, but invariably, as illustrated by the top example on the right, some part of this base pairing will not fit into this rigid active site and allow some erroneous polymerization to take place **This is how we get the high Vmax and low Km for the right nucleotide to be incorporated **This is the opposite for the wrong nucleotide (low Vmax and high Km) |
|
|
|
Exonuclease
|
-An exonuclease is a nuclease (an enzyme that will hydrolyze phosphodiester linkages in DNA) that does so from the END of a DNA
-This exonuclease would not have access to a circular single strand -A 3’ to 5’ exonuclease starts degrading DNA at the 3’ end |
|
|
|
What proofreads the bases that are added to DNA?
|
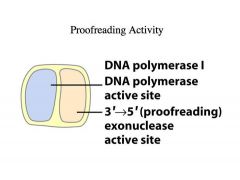
This brings us to an enzymatic activity that is associated with many (but not all) DNA polymerases
-->The 3' to 5' exonuclease associated with many DNA polymerases plays a proof-reading function. Eg. DNA polymerase I -This was the first DNA polymerase that was identified (Arthur Kornberg) -This is NOT the DNA polymerase that you find at the replication fork, it’s actually the polymerase that’s necessary for removing the primers from Okazaki fragments and filling in the gaps -It is a polymerase that has to be accurate -It has associated with it a 3’ to 5’ exonuclease activity -An exonuclease is a nuclease (an enzyme that will hydrolyze phosphodiester linkages in DNA) that does so from the END of a DNA -This exonuclease would not have access to a circular single strand -A 3’ to 5’ exonuclease starts degrading DNA at the 3’ end |
|
|
|
How does the proofreading activity work in a 3’ to 5’ exonuclease?
|

1. Here is a DNA polymerase polymerizing nucleotides
-->The blue is the active site for the polymerase and the yellow is active site for the 3’ – 5’ exonuclease activity -Note the dCTP molecule being incorrectly incorporated opposite an A residue -Suppose that C is in a tautomeric form in which it base pairs with the A residue quite well and it gets polymerized incorrectly -Once it gets incorporated, the rare tautomeric state of C is a high energy state that isn’t usually maintained for a very long time, so C residue goes back to its normal tautomeric state -When that happens, C doesn’t maintain a proper Watson-Crick base pair with the A residue, and thus we have a FRAYED end -When it gets frayed, this frayed end enters into the exonuclease domain of the polymerase 2. Now you can see the exonuclease domain covering the frayed end When it enters into the exonuclease domain, it hydrolyzes this phosphodiester linkage with the wrong nucleotide incorporated 3. That wrong nucleotide is removed and following the removal, the 3’ OH is perfectly aligned to accept the correct nucleotide being placed in the polymerase active site 4. That wrong nucleotide is removed and following the removal, the 3’ OH is perfectly aligned to accept the correct nucleotide being placed in the polymerase active site, and DNA synthesis is resumed 5. Typically with high fidelity DNA polymerase a 3’ to 5’ exonuclease domain is present on the same polypeptide (as in the case of DNA polymerase I) OR in a separate polypeptide subunit that forms a tight complex with the DNA polymerase - Although many of the high fidelity polymerases have proofreading functions associated with them, there are other polymerases that play an important role in maintaining fidelity yet they are not as accurate in their function |
|
|
|
What is a replisome?!
|
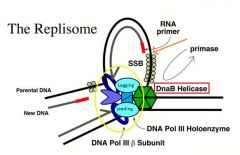
-This is a depiction of a replisome
-We don’t really need to know too much about the replisome that is doing leading and lagging strand synthesis -However, be sure to note: a. DNA B helicase (red box) -->This is an example from e.coli but the mammalian apparatus is very similar and almost a parallel of this although it has different names -For our purposes, learning the prokaryotic replisome is sufficient because it illustrates the main mechanisms involved -DNA B helicase serves as the major replicative helicase -It pulls the parental DNA strands apart, exposing the single stranded DNA that is going to be copied by the DNA polymerase -DNA B helicase also plays a second role as a mobile promoter that guides the primase to sites at which it is going to catalyze RNA primer synthesis on the lagging strand template (orange) -The most important point (circled in yellow) is the DNA Polymerase III holoenzyme -DNA polymerase III in e.coli is the polymerase that promotes leading and lagging strand synthesis at the replication fork. -The aqua colored ovals are the polymerases |
|
|
|
How does lagging strand polymerase keep up with leading strand synthesis so efficiently even though lagging strand synthesis is a discontinuous process?
|
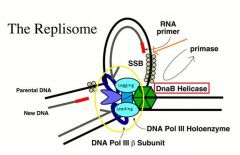
-Note that it is a DIMERIC DNA polymerase
-->There is a polymerase that is dedicated to leading strand synthesis and one that is dedicated to lagging strand synthesis -This is important because as the lagging strand synthesis completes an Okazaki fragment and disengages, that lagging strand polymerase does NOT have to dissociate from the DNA template -Because leading strand synthesis is taking place highly processively on the leading strand, it never comes off -Lagging strand polymerase, on the other hand, has to come off almost every second and go to the next Okazaki fragment -By having the lagging strand polymerase tethered to the leading strand polymerase, the lagging strand polymerase can easily find the next RNA primer, so we don’t have to have a polymerase that’s constantly coming on and off the template. -This is one of the important secrets behind how lagging strand polymerase keeps up with leading strand synthesis so efficiently even though lagging strand synthesis is a discontinuous process unlike the leading strand synthesis which is a smooth and continuous process |
|
|
|
What does single stranded binding protein do??
|
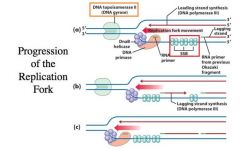
-As we’re doing leading strand synthesis we’re creating single stranded DNA which becomes the site for primase to lay down an RNA primer and allow DNA polymerase to initiate DNA synthesis to make an Okazaki fragment
-Single stranded DNA has a tendency to be hydrophobic, it tends to collapse on itself, and that can impede DNA replication SSB -Single strand binding protein -Binds to single stranded DNA -One of its multiple functions is to keep the single strand in an extended configuration so that lagging strand polymerase synthesis can proceed unimpeded |
|
|
|
What does topoisomerase II do?
|
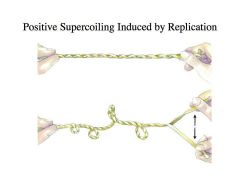
Topoisomerase II (DNA gyrase – e.coli)
-Although the leading and lagging strand templates are often shown as parallel lines, remember that in reality they compose a helix so they’re intertwined around each other -If DNA B helicase comes in and unwinds the helix for the propagation of the replication fork, the DNA ahead of the fork is going to become positively supercoiled unless you unlink the two strands that are intertwined against each other -Topoisomerase II comes in and relieves the positive supercoiling -It acts as a swivel so the propagation of the replication fork can go unimpeded |
|
|
|
How do you finish lagging strand synthesis?
|
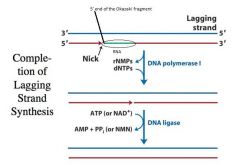
Completion of Lagging Strand Synthesis
-The RNA primer is laid down and is marked for disposal because it is RNA -This is a good thing because there are errors introduced in making an RNA primer usually -DNA polymerase I has one more exonuclease activity -->5’ to 3’ exonuclease activity removes the green RNA and produces a GAP in that region -The DNA polymerase activity of Pol I fills in the gap -It is made into a continuous strand by filling in the nick with an enzyme called DNA LIGASE -The adjacent Okazaki fragment has to serve as the primer for DNA polymerase to fill in the gap !! |
|
|
|
Examples of eukaryotic replication proteins.
|

Examples of eukaryotic replication proteins.
1. The propagation of the eukaryotic replication fork is catalyzed by DNA polymerase α and δ. -->Pol α is tightly associated with primase and functions in lagging strand synthesis. -->Pol δ may be the eukaryotic equivalent of DNA polymerase III. -->However, polε may also have some function in the propagation of the fork. 2. DNA polymerase β functions in base excision repair. 3. DNA polymerase γ is involved in the replication of mitochondrial DNA -What he described previously was the prokaryotic replication apparatus -We ARE NOT responsible for these :) :) :) |
|
|
|
What are the key features of the origin?
|
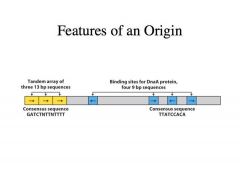
What is taking place at the origin?
-This is the key place of regulation -Can think of initiation of replication as the committed first step in a metabolic pathway -Depicted on this slide is the ORIGIN at the e.coli chromosome, called OriC -This has two important features: 1. Multiple binding sites (blue) -->Simple consensus sequence -->These are bound by an initiator protein called DnaA protein -->DnaA protein is what regulates when replication is going to be initiated 2. Adjacent to the binding site for DnaA is the AT rich region |
|
|
|
How is DNA synthesis initiated?
|
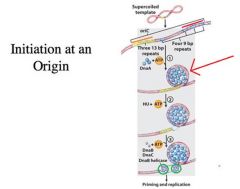
The major event in initiation and replication is duplex opening, loading the helicase at the origin, and laying the primer down for leading strand synthesis
__ A. The process by which DNA replication is initiated at the origin. 1. Opening of the duplex and laying down an RNA primer to begin DNA synthesis. 2. In E. coli, the initiator protein, the DnaA protein, serves to open the duplex and recruit helicase and primase to the origin. Once the primer is laid down, DNA polymerase III holoenzyme extends the primer for the propagation of the fork. B. The initiation of DNA synthesis, whether in eukaryotes or prokaryotes, must be coordinated with the cell cycle. -In eukaryotes the cell cycle can be divided into four phases: G1, S, G2, M (also G0) C. Initiation of DNA replication in eukaryotic cells: -Licensing, a process that requires cell division 1. Binding of ORC, equivalent of DnaA 2. Association of loading factors Cdc6/18 and Cdt1 (early G1), equivalent of DnaC 3. Loading of MCM, equivalent of DnaB, to complete licensing. Licensing requires that cells pass through the M phase of the cell cycle. 4. Geminin, candidate for blocking licensing until mitosis is completed. __ -What’s depicted here is the binding site for DnaA (red line) and the AT rich region (orange line) -Lots of DnaA binds to its binding site and forms a higher order structure (red arrow) *There is ATP involved -As DnaA protein binds, it promotes duplex opening at the adjacent AT rich region -What happens is that when you open the origin then two DnaB helicase molecules can be loaded on each strand (green circles) -DnaB helicase is like a mobile promoter, so it is going to promote the synthesis of one RNA primer on each strand -That is going to be the primer for leading strand synthesis going in both directions -Then, the DnaB helicase starts migrating apart from each other promoting the unwinding of the parental DNA in both directions -DnaC -->“molecular matchmaker” -->Promotes the interaction of DnaB with the DnaA protein, allowing DnaB to be homed in on the site |
|
|
|
Why do we get initiation of replication once and only once?
Why do we have such differentiated cells that have lost the capacity to do any more replication any further? |
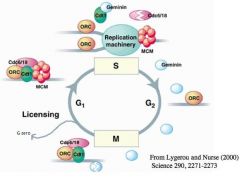
-In the eukaryotic initiation event, there is a protein called ORC --> ORC = origin recognition complex
-ORC is bound to the origin at almost all times in the cell cycle -In the G1 phase, two proteins called Cdc6/18 and Cdt1 act like molecular matchmakers and bind to ORC -When those two proteins bind to ORC, then MCM (mini chromosome maintainence – parallel to DnaB helicase in eukaryotic cells) is loaded at the origin -The cell is now considered to be LICENSED and ready to initiate DNA replication -As we initiate replication, MCM (helicase function) allows the replication machinery to do leading and lagging strand synthesis -Cdt1 and Cdc6 are the important molecular matchmakers necessary for licensing -->Cdc6 gets degraded after it disengages -->Cdt1 is bound by a protein called Geminin which is an inhibitor -Geminin ensures that Cdt1 is inactive -Once it fires, that licensed origin is no longer licensed. It has lost the capacity to initiate replication -During the G2 phase Geminin stays around and Cdc6 is NOT allowed to be expressed, so we cannot initiate replication any further -Once we go through the M phase, Geminin is degraded and Cdc6 is expressed and we get the matchmakers for licensing attached to ORC, MCM binds, and we get licensing once again -The cell can go into a G0 stage -->This is a resting stage -->This is shown to be reversible, but it can be such that it loses the capacity to license its origins, thereby the differentiated cell loses its capacity to initiate further rounds of replication -->In that way, the cell becomes SENESCENT and cannot replicate any further or accumulate any more mutations and is prevented from becoming a tumor cell!!! |
|