Reading...
![]()
Play button
![]()
Play button
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
479 Cards in this Set
- Front
- Back
|
S phase
|
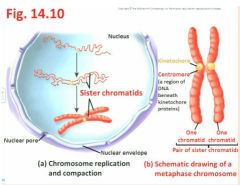
- S is the time for Synthesis (=replication) of the nuclear DNA; each elongated chromosome has been duplicated, and is now said to consist of sister chromatids - see Fig. 14.10
"the bulk of what we're seeing here may be 23-24 hours so interphase is a long phase" didn't you say that 20 hours for cell division was fast ealrier somewhere? - For now, the sister chromatids remain attached at their centromeres, a region of DNA beneath kinetochore proteins which are the eventual attachment points of part of the spindle apparatus - see Fig 14.10a, b "hard to identify chromatin starts to condense so we can more easily see it "now you have each sister chromatid which will eventually say goodbye but for now is hooked up at the centromere… kinetochore" |
|
|
When S phase is completed...?
|
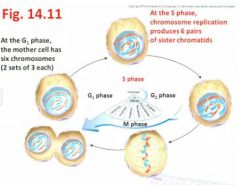
- When S phase is completed, the cell then contains twice as many chromatids as the number of chromosomes present in the G1 phase - revisit fig 14.11,
|
|
|
cell division table?
|

|
|
|
members of a pair of chromosomes?
|
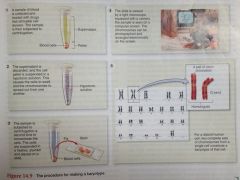
- Note that members of a pair of chromosomes are called homologues (one homologue received from mother, the other from father) - see Fig 14.9 (female, human karyotype)
"down in the bottom, this is the 23rd chromosome and there is no Y, and we have diff steps of that process… we can go back to a few lessons ago where we were talking about hypotonic solutions so water rushes in to make it more plump and in that case this helps to separate the chromosomes so they're more easily spread out and then by microscopy after fixation, in the top right in the monitor you can see all manner of chromosomes and those can be imaged and then cut and pasted and lined up in this way and so that is what a karyotype is and so there you can see the 23 types of chromosomes " |
|
|
closer look at karyotype picture?
|
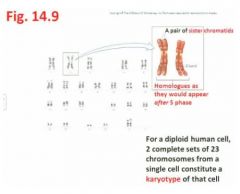
"...we know this is a human cell and we have two complete sets of 23 chromosomes from a single cell and that constitutes the karyotype of that particular cell; here we have separate chromosomes but that chromosome has undergone the S phase and so going into the G phase, that is what it would look like with it's pairs of chromatids and then the same has happened say from the other parents, homologous chromosome number 2."
|
|
|
G2 phase
|
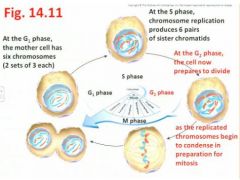
- the second Gap (gap before you get to the M phase) or Growth stage where the cell prepares for division, eventually to be followed by the M phase - revisit Fig 14.11"Sister chromatids per chromosome are going to start to condense and coil a little more so it's easier to see them as chromosomes in the nucleus which is about to start breaking up"
|
|
|
M phase
|
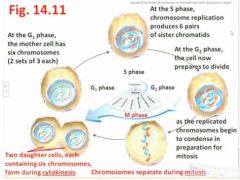
- includes both Mitosis and Cytokinesis (we'll see this soon) [Note: G0 phase - assigned to certain cells that have simply postponed a commitment to a further cell division, or have differentiated to a mature state (eg ,nerve cells in animals) and so will never divide again]
- Duration of the cell cycle varies tremendously, from several minutes (eg embryos) to several months (eg slow-growing cells of adults) - As an example, in actively dividing cells of an adult mammal, it takes 24 hours to complete a cell cycle, with these intervals being typical: - G1 phase (11 hrs), S phase (8 hrs), G2 phase (4hrs) M phase (1hr) - Thus even though its duration is relatively very short, there are several noteworthy details pertaining to the M phase … revisit Fig 4.11 |
|
|
Mitosis and Cytokinesis (chapter 14 , pp. 322-327)
|
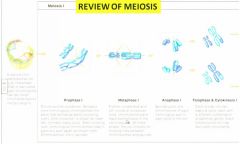
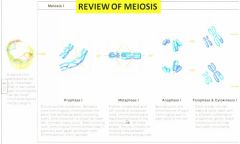
- The M phase of the cell cycle includes 2 consecutive processes:
1) Mitosis results in the orchestrated division of the genetic material (DNA) of the mother cell`s nucleus, to deliver the same complement (i.e.. number and type) of chromosomes into the two genetically identical daughter nuclei; followed by 2) Cytokinesis in which the mother cell`s cytoplasm is separated into the two daughter cells (we`ll return to cytokinesis shortly) Mitosis involves four progressive steps (prophase, metaphase, anaphase, telophase) of chromosome sorting and separation - |
|
|
Prophase
|
- the elongated chromosomes duplicated during S phase, now condense/coil and are even visible by light microscopy (eg, Lab 3)
- Also, the nuclear envelope breaks down, and a spindle of microtubules (part of the cell`s cytoskeleton - a polymer made of the protein, tubulin - these same structures make the 9 + 2 arrangement of microtubules found within a flagellum; seen in Lab 2) starts to form across the cell |
|
|
Metaphase
|
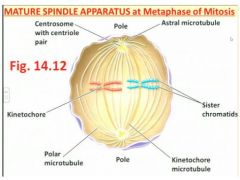
- alignment of all duplicated chromosomes occurs end to end, at the centre of the cell, along the metaphase plate that forms half-way between the poles - see Fig 14.12 including spindle apparatus
- When complete, the spindle apparatus consists of three types of microtubules (MTs): * Polar MTs that project toward, and help separate, the two poles of the dividing cell; * Kinetochore MTs that actually bind to the kinetochore protein near the chromosome`s centromere, and hence will pull the chromosome to the pole; and *Astral MTs which are small clusters that anchor the spindle`s two poles, where centrosomes (also known as MTOCs = Microtubule-Organizing Centres) are located |
|
|
Metaphase of mitosis prof's drawing on the board?
|

|
|
|
Mitosis - Metaphase?
|
1) Polar MTs that project toward, and help separate, the two poles of the dividing cell;
2) Kinetochore MTs that actually bind to the kinetochore protein near the chromosome's centromere, and hence will pull the chromosome to the pole; and 3) Astral MTs which are small clusters that anchor the spindle's two poles, where centrosomes (also known as MTOCs = Microtubule-Organizing Centres) are located |
|
|
Mitosis - Anaphase?
|
centromeres of each duplicated chromosome separate, as individual chromosomes are pulled along kinetochore MTs of the spindle, to opposite poles of the mother cell which become even more distant, by pushing and lengthening of the polar MTs "make a V shape"
|
|
|
Final cell cycle chart?
|
|
|
|
Telophase?
|
chromosomes reach the poles, as the nuclear envelope reforms around each chromosomes complement (also nucleolus) - Chromosomes start to decondense and uncoil, binding with protein to become chromatin again, as mitosis ends
|
|
|
Cytokinesis?
|
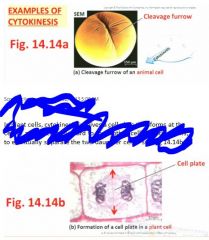
occurs immediately as mitosis is completed, with the portioning of the mother cell's cytoplasm into the daughter cellsIn animal cells, cytokinesis occurs via a cleavage furrow that pinches inwawrd between the two nuclei, to form two daughter cells
"Usually done quite equally so that the two are quite identical" In plant cells, cytokinesis involves a cell plate that forms at the centre and extends outward to the mother cell's existing walls, to eventually separate the two daughter cells "In here we can find all manner of golgi forming vesicles that are single membrane bound organelles that become part of the new cell membrane" |
|
|
Review of cell cycle in an animal cell?1
|
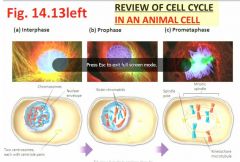
|
|
|
Review of cell cycle in an animal cell?2
|
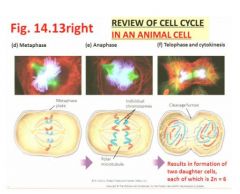
|
|
|
Prometaphase is...?
|
nbetween like Brunch is between breakfast and lunch.
|
|
|
review of mitosis?
|
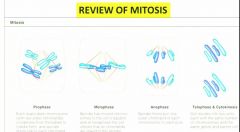
On the right (telophase & cytokinesis): Two identical body (somatic) cells are the result of mitosis and cytokinesis
|
|
|
Why produce sexually?
|
- Remember that mitosis keeps yielding daughter cells identical to the mother cell - but if the environmental conditions change such that the species can no longer adapt, production of clones via asexual reproduction can even become a liability for the species
- Perhaps is the reason why many eukaryotic species can produce botgh asexually and sexuall (eg, strawberry - runners, vs. flowers/fruits) If you can get away with aesexual reproduction, then you don't have to go thru the costs of producing powers and hoping for pollinators to move pollen around |
|
|
Meiosis translates to
|
Meiosis translates to "to make smaller", in reference to the formation of four small sex cells (=gametes) from the mother cell
|
|
|
gametes participate in
|
gametes participate in sexual reproduction (rather than asexual reproduction, like mitosis can)
|
|
|
Meiosis represents
|
Meiosis represents an extremely important process because it leads to genetic differences in the gametes (whether egg cells or sperm cells) resulting in variation within a species
|
|
|
Each mature gamete has
|
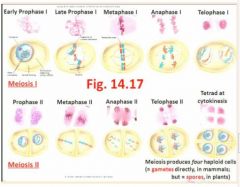
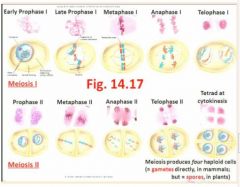
- Each mature gamete has only 1 set of chromosomes (ie, there is no homologue of each chromosome present), so this condition in the gamete is called "haploid" - see Fig 14.17 for synopsis of Meiosis I & II
"You don't have a red and a blue one." |
|
|
"Each gamete is 1n (haploid)
In meiosis metaphase 1 the homologues find each other, and then line up, two red sister chromatids and then two blue sister chromatids of the homologous chromosomes, so you never see 4 in mitosis." |
|
|
When these sex cells unite (egg with sperm) at fertilization,
|
- When these sex cells unite (egg with sperm) at fertilization, they combine their variability inot a single "diploid" cell, the zygote, which produces a uniqu individual while restoring the diploid condition of having 2 sets of chromosomes per cell
|
|
|
After many mitotic divisions, it leads to
|
- After many mitotic divisions, it leads to a new individual similar (but not identical) to either of the parents
|
|
|
Probably an indication of the value of their gametes,
|
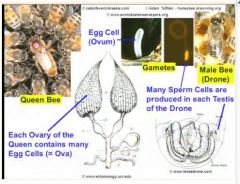
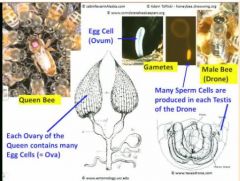
- Probably an indication of the value of their gametes, organisms surround and protect their products of meiosis, while also having various mechanisms to allow mature gametes to be delivered or escape eg.g., animals - form gametes directly, without delay, inside the ovaries of the female (i.e., egg cells = ova) or testes of the male (i.e., sperm)
|
|
|
examples of meiosis?
|
- e.g., flowering plant - egg cell located within an ovule, where sperm cells are enclosed and protected inside a pollen grain (which is a spore)
e.g., fern plant - has an alternation of generations, between a diploid sporophyte (which forms spores by meiosis) and then a haploid, heart-shaped gametophyte that grows from the spore, and after some delay, eventually forms an egg cell at the base of each archegonium and many sperm inside each antheridium - |
|
|
" Queen's abdomen is large because of the ovary sex organs and she is in control as to whether she releases sperm that she's stored in her body to cause fertilization of that egg. Workers are sterile.
" |
|

|
"Pollinated by a lot of flies and bees. Pollen grain gives protection to sperm cells located inside. "
|
|
|
Production of sperm cell is in testes (male gametes and the egg being the female gamete sometimes called egg). Almost all of the Queen's cells are diploid. Meiosis is the production of sex cells.
|
|
|
To yield four products (ie gametes; spores) of meiosis, the entire phenomenon is designated into two processes simply called...
|
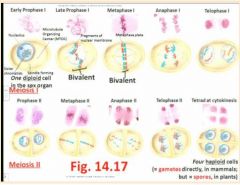
Meiosis I (followed by cytokinesis) and Meiosis II (again followed by cytokinesis)
- Each process features distinct phases, and the same prefixes introduced during Mitosis, are used again: pro-, meta-, and- and telophase; for instance, meiosis has phases called anaphase I and anaphase II "Homologues find each other. We want four variable products. Bivalent is when ?chromosomes? find each other in fours. At S, the chromatid doubles so both chromatids must be identical (two big As are homozygous dominant and two small As are heterozygous. In meiosis II, the cell wall is 90 degrees to the previous. In humans we have 23 pairs. Completely random whether you have a red one or whether you have a blue one on the right or the left in metaphase but it has a huge impact on what kind of gamete is formed" |
|
|
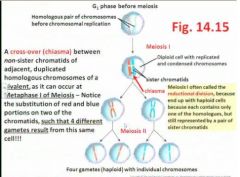
Very importantly, a critical difference between Mitosis and Meiosis I is that late in prophase I of meiosis...
|
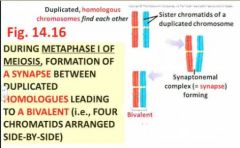
late in prophase I of meiosis, each duplicated chromosome (ie containing sister chromatids) is drawn to its homologous chromosome ( a synaptonemal) complex = synapse forms), which causes the homologues to align side-by-side (rather than aligning end-by-end as occurs in the metaphase plate of Mitosis) - alignment (left or right) occurs randomly!
Thus, in metaphase I of meiosis, find the arrangement of bivalents (=the duplicated homologous chromosomes are tightly held side-by-side to one another), so that in each bivalent there are actually 4 chromatids across - see Fig 14.16 |
|
|
Another very important event that also happens randomly and leads to increased variation, is the formation of a chiasma (a cross- over) between...
|
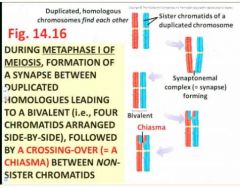
between adjacent, non-sister chromatids of the bivalent
|
|
|
Chiasma allow
|
- "allows exchange of DNA between chromatids"
- "chiasmas are a completely random event" Thus, the alignment of duplicated chromosomes at random within the homologous pair, plus the random formation of cross-overs (chiasmata) at a random site along the non-sister chromatids of the bivalent, leads to incredible possibilities for variation within the four haploid products of meiosis, especially when the diploid (2n) number of chromosomes is high! (ie, in humans, 2n=46) - the stage is set for causing variation, here in metaphase I of meiosis - |
|
|
Notice that by the end of Meiosis I (ie, following completion of anaphase I, telophase I, and cytokinesis), the 2 cells produced are already reduced to the...
|
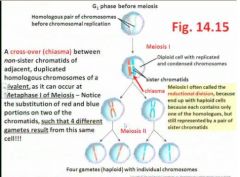
to the haploid state; that is, although each cell still contains a duplicated chromosome with sister chromatids, the homologue is no longer there (because it has moved to the other cell!), so there is only one set of each chromosome per cell; thus, Meiosis I is often referred to as the reductional division of the entire process of meiosis
|
|
|
Note that Meiosis II shares similarities with Mitosis, in that the duplicated chromosomes at metaphase II now align end-by-end and, by anaphase II, centromeres have separated so that sister chromatids now get delivered by kinetochore microtubules of the spindle apparatus, to the separate poles; thus four diff _____ cells are produced
|
haploid
|
|
"Different lengths are not the same homologues"
|
"Different lengths are not the same homologues"
|
|
|
Each one of the four products of meiosis (ie gametes in animals; spores in plants, fungi) are typically much diff (based on
|
based on the alleles of their chromosomes' genes) from the other three, owing to chromosome alignment and chiasmata formed at metaphase I- ie, they end up with a diff genetic make-up - hence, variation from the parent has been achieved, leading to a unique, brand new individual once fertilization (involving another parent) has occurred!
|
|
|
diff orgs vary greatly in terms of their size (and hence
|
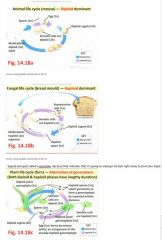
and hence how many mitotic divisions have occurred to build up their number of somatic (body) cells), plus the duration of the diploid and haploid stages in their life cycles, and where and when meiosis occurs
|
|
|
Comparison of Life Cycles?
|
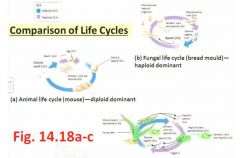
"Pollen are spores and they're highly reduced spores. Inside them they undergo a mitotic division to produce two sperm cells and these sperms are needed for double fertilization which is beyond our course"
|
|
|
Classical genetics?
|
transmission of hereditary info
|
|
|
molecular genetics?
|
mechanisms related to transmission and use of genetic info, and genetic mutation
|
|
|
Bioenergetics?
|
how energy is harvested from sunlight, and how it is used by plants and animals?
|
|
|
Applications of classical and molecular genetics to can be summarized as...
|
bio tech and experimental techniques
|
|
|
learning outcomes for this section: (genetics moll biology, applications)
|
learning outcomes for this section: (genetics moll biology, applications)
|
|
|
classical genetics?
|
the basis by which traits are inherited and teh major patterns of inheritance
|
|
|
moll genetics?
|
mechanisms related to transmission and use of genetics info, related to gene transcription and gen product translation
|
|
|
classical genetics are the encapsulation...
|
of this course.
|
|
|
Mol genetics has two main...
|
processes: gene transcription (the info that is encoded in DNA sequences is transcribed into RNA prior to use) and gen product translation (gene products being translated from nucleic acids into proteins). You should be aware that proteins are the user information of the cell for genetic sequences.
|
|
|
molls are held toegether by...
|
chem bonds; all sorts of chem bonds in particular strong bonds that are covalent, weaker bonds that are ionic and hydrogen bonds
|
|
|
The major molls that form the bulk of the structure of cells are...
|
polymers which are polymerized from relatively few monomers.
|
|
|
In this part of the course, the polymers we'll be most interested in are _____________ and the monomers are......
|
nucleic acids
and the monomers are nucleotide bases |
|
|
_________________ are for biochemical specialization within the cell
|
eukaryotic
|
|
|
Although proks are strucurally ___________, they are extremely _________________ biochemically and we depend on proks and contend with them in all of our daily lives
|
structuralliy simple
sophisticated biochemically |
|
|
Plant cell wall gives structure which is supported by internal _______________ pressure
|
hydrostatic
|
|
|
_________ are ___________________ organelles which were originally derived from the chloroplast. They share ___________.
|
plastids
endosymbiotic Mitochondria. and nucleus. |
|
|
What are the three kinds of genetics?
|
transmission genetics
molecular genetics population genetics |
|
|
transmission genetics?
|
inheritance of traits
|
|
|
molecular genetics?
|
genes to phenotypes
|
|
|
population genetics?
|
allele frequency related to natural selection, drift, mutation, flow between populations
|
|
|
what kind of genetics will we focus on?
|
transmission genetics
|
|
|
Traits that are inheritable are...
|
ones from your parents that'll go to your offspring. Other traits include ones that you'll get from nurture rather than nature, but this has to do with inborn or intrinsic features
|
|
|
Pheonotype is...
|
the sum of all the characteristics createed by your protein coding genes and by the relationship between these genes durin org development
|
|
|
What kind of genetics will we not talk about at all in this course?
|
population genetics
|
|
|
Hippocrates?
|
inherit acquire characteristics from your parents
|
|
|
Aristotle?
|
In herit the potential to form the same features as your parents
|
|
|
Early 19th century?
|
characteristics of the parents were blended in the offspring
- populations would be expected to become more similar over generations - difficult to reconcile with the sudden appearance of new traits |
|
|
It was originally thought that you inherited acquired characteristics...
|
from your parents
- eventually realized that you inherited the potential |
|
|
By th 1500s 1600s, horticulturalists had already...
|
created a variety of orgs with distinctive traits
|
|
|
from the 1950s Dmitri Belayev took...
|
2 groups of foxes, bred them together and in each succeeding gen, he selected the most friendly and the least friendly and bred them to themselves and over 8 generations these wild animals have become very much more like dogs (their vocalizations, they actions, in another 3 gens they have droopy ears, diff coats like dogs) other population selected for lack of friendliness had become more like that. The point here is that selection takes very few generations. So selection for crop plants, for crop animals can be repeatedly generated in a relatively short period of time that depends mostly on the generation time of the organism in question.
|
|
|
Who were the first geneticists?
|
Farmers were the first geneticists
- selected and propagated animal and plant strains with desirable traits |
|
|
Nowadays the grains that we eat are extremely...
|
large compared to the wild seeds. Most grains weigh at least 50mg.
|
|
|
We have been able to create domesticated animals of anumber okinds but
|
but not of others. Cattle, pigs, sheep, chickens have been domesticated in a number of ways because they have become metabolically attuned to living w people. Deer zebras and bison can be herded by they can't be domesticated.
|
|
|
The blending idea is a good predictor for...
|
mutli-gene characteristics but not a good predictor for single gene characteristics and until someone came along and was able to investigate single gene specified traits we couldn't get any further and that person was Gregor Mendel.
|
|
|
Gregor Mendel was trained to be...
|
a science teacher (studied mathematics, practical and theoretical subjects) but failed to qualify, so returned to his abbey to farm.
|
|
|
Gregor Mendel was not allowed to?
|
Study of inheritance of animal characteristics (mice) was not permitted by his abbot. Chose peas.
|
|
|
In the 1850s while Mendel did his work,
|
- relatively little was known about cell theory
- nothing was known about nuclei - microscopes were not generally available |
|
|
In Mendel's experiments....
|
- several pairs of true-breeding pea strains (these would have been created by previous generations of farmers)
- grew these strains for three seasons to confirm - the traits he studied were controlled by single genes that had two distinctive alleles "He had strains where all were purple and all were white There were also differences in flower position Fortunately for him and fortunately for us, it turns out that the traits he was studying were controlled by single genes and the genes had distinctive alleles and the alleles are the characteristic of an individual variant of a gene that controls some aspect of its phenotype and so here we have a gene for colour and it has an allele that's white and it has an allele that's purple. One for position and one for terminal." |
|
|
How did Mendel reproduce the plants?
|
he could dissect the flower and either keep the stamens(male part) which contain one of the gametes or stigma(female part) and he could dissect his plants before fertilization and control where the pollen came from.
|
|
|
How long did Mendel's experiments take?
|
several months
|
|
|
Mendel's results could not be explained by...
|
a blending of parental characteristics or tendencies, or else you would have slightly wrinkled seeds
|
|
|
particulate inheritance?
|
discrete "particles" of genetic information are inherited from each parent and one particle will be dominant over the other (Mendel's hypothesis)
|
|
|
How many true-breeding traits did Mendel test?
|
seven true-breeding traits
|
|
|
for classical transmission genetics, testing a dominant-phenotype individual's genotype involves...
|
mating
|
|
|
Mendel's term for gene?
|
discrete particles
|
|
|
Genotype?
|
genetic make up of an organism?
|
|
|
Traits we see?
|
Phenotype?
|
|
|
Gene?
|
A unit of hereditary information?
|
|
|
Allele?
|
A version of a gene?
|
|
|
Homozygous?
|
When both alleles of a given gene are identica (only in diploid orgs)?
|
|
|
Heterozygous?
|
When two alleles for a given gene differ in an individual?
|
|
|
Phenotype is the result of...
|
the interplay of all the genetic characteristics as they play out in the final org.
|
|
|
Allele is the version of a gene that...
|
that you can see
|
|
|
Mendel looked at
|
- flower color
-flower position -seed color -seed shape -pod color -pod shape -plant height when he crossed the true breeding lines |
|
|
Genes are heritable
|
heritable particles
|
|
|
Gene variants are
|
alleles
|
|
|
Mendel focused on how many genes at a time?
|
One gene
|
|
|
Mendel`s 1st law?
|
Alleles of one gene segregate independently from one another during the formation of gametes.
|
|
|
Monohybrid Cross?
|
a cross involving one gene
eg. the gene for plant height |
|
|
You'll only get the 3:1 ratio thing if ...
|
if according to Mendel's first law, alleles of a single gene segregate independently during gamete formation
|
|
|
For this model to be true, the individual must have ______ copies of each gee and the gametes must have only _____ copy
|
two copies
one copy ---> law of segregation of alleles |
|
|
For one gene you need how many alleles?
|
two. one from mother and one from father
|
|
|
If two alleles are different, one will be
|
dominant
|
|
|
"gene" was coined by
|
Wilhelm Johannson, 1911
|
|
|
Each sperm or egg cell carries...
|
only one alele of a given trait because they segregate from one another
|
|
|
Alleles are represented by
|
single letters
|
|
|
True breeding plants are
|
homozygous
|
|
|
Genetic make up of an org?
|
Genotype?
|
|
|
Traits we see?
|
Phenotype?
|
|
|
Gene?
|
A unit of Hereditary information?
|
|
|
Allele?
|
A version of a gene and they are indicated by letter symbols?
|
|
|
Diploid orgs can be?
|
homozygous or heterozygous
|
|
|
homozygous?
|
When both alleles of a given gene are identical?
|
|
|
Heterozygous?
|
when two alleles for a given gene differ in an individual?
Aa (one gene) BbQq (two genes) |
|
|
The punnet square was invented by?
|
Reginald Punnet
|
|
|
Reginald Punnet's first book was?
|
in 1905
|
|
|
Results Mendel got in his dihybrid crosses of pea plants revealed...
|
another important principle of inheritance now referred to as Mendel's second law of inheritance
|
|
|
Mendel's 2nd law?
|
Alles of diff genes assort independently of one another during gamete formation
|
|
|
Aspergillus and most fungi are vegetatively ...
|
haploid, there is one diploid nucleus
|
|
|
certain results are only possible because the two alleles segregate...
|
independently from each other
|
|
|
Probability and genetic analysis?
|

|
|
|
Tri-hybrid crosses?
|

|
|
|
True-breeding is _______________ in nature
|
unusual
|
|
|
Individuals have _____ copies of each gene
Gametes have _________ copy |
two
one |
|
|
segregation in modern terms?
|
Alleles separate into diff haploid cells that eventually give rise to gametes. Then during fertilization, male and female gametes randomly combine with each other.
|
|
|
Monogene inheritance and digene inheritance are a matter of...
|
are a matter of interpretation ... how many things we're interpreting in the cross
|
|
|
Incomplete dominance?
|

You see the heterozygotes immediately. You don't have to do another breeding to see the heterozygotes.
Incomplete dominance permits direct observation of heterozygosity, unlike peas. |
|
|
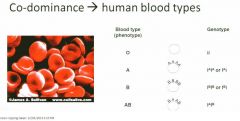
Many genes have multiple alleles (more than two)
Sometimes these alleles are expressed together |
|
|
|
In the human blood type phenotype, red blood cells have a _____ _____________ on the surface and it can either be elaborated in the A type with
|
basic backbone
in the A type with a small sugar molecule called the N-acetylgalactosamine, In B type it’s the galactose , in the AB you an have both kinds and in the O you have neither |
|
|
These diff phenotypes are not required for the function but are involved in the...
|
in the interaction between blood cell types and if you have a transfusion where you are transfusing blood that contains an antigen type that your body is not accustomed to then the recipient for that transfusion will mount an immune response against it because the transfused blood is being recognized as foreign and you get a clotting of the transfused blood which leads to death.
|
|
|
In diff racial groups you have diff ...
|
- In diff racial groups you have diff proportions of people who have diff kinds of antigens. Original Africans have all four kinds. Native Americans only have two.
|
|
|
1939v new problem with transfusions arose.
|
People with right ABO match still had problems. Rhesus macaque - kind of monkey blood
90% have the Rh factor 10% do not. So we now have a nuanced understanding of this blood type cross matching. |
|
|
Universal donors are the
|
O-
|
|
|
Universal recipients are the
|
AB+
|
|
|
Can't have O and A parents resulting in
|
- Can't have O and A parents resulting in AB - now we have more complicated paternity tests but they all stem from Mendellian genetics
|
|
|
___________________ _______________ are more likely to share these factors than unrelated donors
|
family members
|
|
|
Blood matching is less complicated than?
|
Tissue matching is more complicated than?
|
|
|
Genes can lead to predisposition to...?
|
Genes can lead to predisposition to habit
|
|
|
Some diseases 'run in families'. Is this
|

|
|
|
family trees are also called
|
pedigree analysis
|
|
|
pedigree analysis is used
|
used to determine if a disorder may be related to heredity
|
|
|
many _______________ respond to environmental factors
|
phenotypes
enviro factors such as temperature |
|
|
Although you can examine the effect of a single gene, you're always doing it in the context of
|
the entire organism.
|
|
|
Some traits are controlled by multiple genes
|
What traits were the basis for blending inheritance models in the 1800s?
|
|
|
Done more experiments with _______ than any other species.?
|
dogs?
|
|
|
How many genes control the hairiness of dogs?
|
Three.
Hair length, consistency, and curl. There are alleles for each of these. eight other genes govern color |
|
|
Can one gene affect many traits?
|
Yes. Genetic pleiotropy.
|
|
|
Who first noticed genetic pleiotropy? And what did thye notice?
|
Mendel noticed
- plants with coloured seed coats had coloured leaf axils - plants with colourless seed coats had non-pigmented axils |
|
|
What is an animal example of genetic pleiotropy?
|
About 40% of blue-eyed white cats are deaf
- this is associated with degeneration of the cochlea (inner ear) - Some odd-eyed cats are deaf on the blue side |
|
|
In humans, there are ____ pairs of autosomes and ________ pair of sex chormosomes
|
22
1 |
|
|
In humans, women are
|
XX
|
|
|
In hhumans, men are
|
XY
|
|
|
Autosomes are
|
chroms that affect only general body characteristics
|
|
|
Sex chroms determine
|
determine the gender of the individual
|
|
|
The sizes of the X and Y?
|
They Y chrom, although it is very small has some extremely important sexual determining characteristics whereas the X is very large and encodes a large number of autosomal traits as well as the sex trait.
The Y chrom although is small and has relatively few protein encoding genes, many of these turn out to be transcription factors that are turning on sexual characteristics in the developing fetus. If you lack Y, then you are female, if Y is overlaid on the X then you are male. |
|
|
We know the most about genetics in chickens because..
|
we like to eat chickens and that's often how it works
|
|
|
Genetics in birds?
|
ZW females
ZZ males best studied in chickens |
|
|
genetics in bees
|
XX FEMALES
XO MALES unfertilized female bees can only produce males Johann Dzierzon, a Catholic priest 1845 discovered long before Mendel |
|
|
Reptile genetics?
|
30 C -> females
30-34 C -> both sexes 34 C -> males could become an issue as climate change transpires |
|
|
Depending on the gene and the species, alleles can show
|
- complete dominance (Mendel's peas)
- incomplete dominance (flower colour in 4-o'clocks) - co-dominance (human blood type) |
|
|
short definition of pleiotropy?
|
One gene, multiple phenotype responses.
|
|
|
The Y-chromosome has only
|
has only a few genes (about the size of chromosome 22)
|
|
|
If a human male has a defective allele on his X chromosome
|
no backup copy on Y
|
|
|
red-green colour blindness is most
|
is most common sex-linked problem
|
|
|
If you are XX
|
then you're female and one is active and one is not
|
|
|
if you are male and you have XY and if there's a problem on X
|
there's no backup copy of those genes on Y and so if you have a defect in the X chrom, then you wind up being female (I think)
|
|
|
Colour blindness is is found in ______ % of men
but only in ____ % of women |
5-10
0.5-1 |
|
|
Why the difference between genders?
|
If you are a color blind male, all you have to have is they y chrom from your father and the color blind X from your mother so you're color blind for x and normal for y. Women have colour blind father and a mother that has one copy of a color blind X gene. Rare for women.
|
|
|
Potential adaptive advantages?
|
Peopple that are colour blind have better grey scale perception.
|
|
|
Pedigree analysis is for...?
|
organisms where gender is determined by chromosome
|
|
|
What are the implications of pedigree analysis?
|
This means that not only can genetic diseases run in families but in addition they have a sex linked preponderance.
You don't see hemophiliac women, you do see hemophiliac men. |
|
|
In an autosomal linkage you can have either
|
gender being a carrier because each chrom is represented twice in both genders. Here you can have transmission of a trait but the trait is not gender specific.
|
|
|
If there are are relatively few individual represented, then these are
|
recessive traits and that means that in order to show the phenotype you need to have both copies, in this case this is very much like flower color inheritance in peas for example where if you have one copy of the dominant gene you show the purple color phenotype but you need two copies of hte recessive to showt he sam phenotype.
|
|
|
Sex linkage was first determined to be a genetics phenomenon back in
|
1910 shortly after the rediscovery of Mendel's ideas. This has been very extensively studied since that time originally in Morgan's lab where he was studying Drosophila
|
|
|
Why did Morgan study Drosophila?
|
because rather than people, drosophila has a very short generation time (flies). Like us the female is XX and the male is XY
|
|
|
What did Morgan find wtih his flies?
|
After two years of studying these things and trying to understand how the phens were inherited, a fly was isolated that had white eyes rather than the usual red eyes. These flies also happened to be blind and this turns out that pigment and eye perception were linked. this fly happened to be male.
In the F1 generation, there were no white eyed flies and this is what you'd expect because the wild type female having not come from a mutant population would be expected to have both wild type X. But in the F2 gen.... This suggested that the defect was on the X chrom |
|
|
Crappy notes on Morgan's Drosophila?
|
- Morgan used fruit flies to demonstrate the chromosomal basis of inheritance of sex-linked traits
- In fruit flies, female is XX, male is XY - In the f2 generation, all the white-eyed flies were male - The gene that was affected was located on the X chromosome and can be followed through various other crosses. |
|
|
If you have a sex linked trait, when you mate a mutant with a wild type,
|
If you have a sex linked trait, then when you mate a mutant with a wild type, the characteristic disappears in the f1 gen and when you mate the f1 gen to itself, it reappears but you only see it in the gender which is considered to be hemizygous for that trait
|
|
|
linkage between autosomal traits?
|
We've talked about sex linkage and now we can talk about linkage between autosomal traits. When Mendel was doing hist studies on peas, each of the characteristics he was mating had no apparent relationship to any other traits but taht isn't always the case. There are going to be cases where if you look at a parental inheritance, you will see the standard 3:1 pattern, but if you look at the pattern pairwise, you see a very different kind of inheritance relationship. So we don't see this in single genes but we do see it when we look at pairs of genes. You don't get the same expected phenotype.
|
|
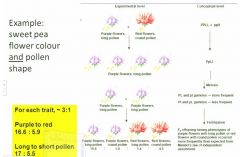
Was Mendel wrong? Does it work in peas but not in sweet peas?
|
It's that there's more than one locus on each chrom and loci that are close together tend to be inherited together. For purple to red, you have 18:6 which is good and for Long to short pollen you have about 18:6 which is good but for the pairwise inheritance we don't see that pattern.
|
|
|
Gene linkages being inherited together?
|
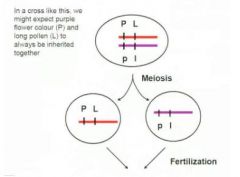
|
|
|
Only have to worry about linkage when you're talkng about...?
|
dihybrids
|
|
|
That divergence from expected and observed phenotype ratios indicates recombinants was first discovered in...?
|
Morgan's lab
|
|
|
Crossing-over in meiosis I increases
|
genetic variability by recombining parental allele assortment for loci on the same chromosome
|
|
|
Linkage can be used for mapping
|
distances between loci
|
|
|
Crossover frequency is related to
|
physical distance between loci
|
|
|
Genetic distances are
|
% recombination, measured in centiMorgans
|
|
|
map distance =
|
(number of recomb offspring/total number of offspring) x 100
|
|
|
They can organize loci on a chrom by looking at the
|
inheritance of parental traits vs the inheritance of recombinant traits.
Mutant flies are mated with wild flies and then you look at the paralyzed inheritance of the two traits and in doing this we've been able to order diff genetic loci down a chrom. |
|
|
Linkage is when
|
you have two traits where the parental combinations are more preferrentially inherited than the recombinants.
|
|
|
If you have unlinked genes, you will have situations where you have the function of one gene depending on
|
depending on the function of another gene (previous gene), so you have a series of genes in a biochemical pathway. The function of downstream members of the pathway is going to depend on members of the upstream. The white phenotype can't make pigment and there' s two step process where there's yellow and then the fully formed pigment is green so what happens here is that if you have a parent who has a white spore then that will be inherited 50% of the time and if you in herit that then it doesn't matter what you have at the other genetic locus, you will be white. Approx. 50% of the matings for a strain where one of the parents is white must be white because it's unable to make any kind of pigment no matter what the other locus encodes.
|
|
|
Epistasis is?
|
When inheritance of a trait is dependent on more than one allele.
- the inheritance of an allele at one locus affects the phenotypic expression of an allele at a second locus - spore colour in aspergillus |
|
|
Epigenetics?
|
- Mitotically or meiotically heritable changes in gene function, that are not related to DNA sequence
Epigenetics has been considered as a relatively recent kind of genetic mechanism but it is becoming more and more relevant and more and more important for biotech and for understanding of disease. |
|
|
Environmental gene regulation
- prenatal environment -> nutrient supply, stress ? |
One of the first places this was identified was a the end of WWII in NW Netherlands. During the war there was an imposed famine on part of the Netherlands, calorie intakes were dramatically reduced so ther ewas a whole cohort from September to April just 6 months where calorie intakes were cut by up to 2/3rds so the question that was asked following the resolution of the second wordl war was What happened to the children who were devleoping in eutero during that time? These children have been followed since and these children who were stressed in eutero have developed many kinds of phenotypic disease relationships particularly enhanced diabetes and enhanced heart disease compared to the populations who were born immediately before the famine
Post WWII Netherlands study Suggests that there are relationships between the genes and the cellular enviro that the genes are operating in which means what we had originally imagined that genes were the master orchestrators of protein production, but actually the genes are responses to the cellular context that they're operating in. 2 major ways that we're understanding the way that these effects are generated. |
|
|
Mechanisms
- chromatin modeling and histone modification - dna methylation patterns |
During chrom condensation of mitosis and meiosis, the DNA is never entirely exposed. It's wound around proteins called pit stones and it is modification of the pit stones that relates to the relative affinity of the histone 40 DNA double helix and the reason this is important is that because it's never exposed, the tightness between the histone and the DNA is going to relate to the transcription rate so the ability for a gene to be able to transcode a protein is related at a fundamental level to its exposure to the biosynthetic complexes that are going to generate it.
The other way is through methylation of cytosene on the DNA. When an area of DNA is methylated then it tends to be less highly transcribed and less highly translated so again you can have long term changes in the methylation of a gene that will change the relative transcription and relative translation of the genes that are in herited regardless of the alleles that are in that gene. This is an extra level of regulation which we now know is also going to be important. |
|
|
DNA-histone association affects
|
gene activity, not DNA sequence
|
|
|
Within an indivudal's lifetime, this histone stuff is related to
|
cell differentiation.
During embryonic development and cell differentiation, many genes are 'turned off' During cancer development, some genes are 'turned on' |
|
|
Epigenetic factors can be modified. Potential...
|
potential therapy.
|
|
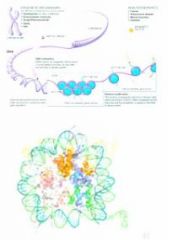
|
So here we have a histone protein which is wrapped around by a DNA double helix so the interaction here is going to relate to the ability of the transcriptional complexes to access this kind of information so these patterns are long-term stable and they particularly affect the access and ability to translate the content of the genetic code to the cell.
|
|
|
this stuff is an overview of
|
regulation mechanisms
|
|
|
What is the advantage of understanding epigenetics?
|
you can fine tune a gene regulation to make it very relevant to a temporally local or spatially local event much more rapidly than a gene mutation.
|
|
|
1883
|
Weismann and Nageli suggested there was a chemical substance in living cells responsible for inheritance
Purely theoretical at that point because nuclei was still not understood and cell theory was at a primitive stage. |
|
|
1838
|
WH Perkin - synthetic dyes - some selectively stain cell components - Perkin dyes are responsible for bright colored clothing today and have selective affinity for diff cellular components and using microscopy you can see components that you couldn't previously resolve. Also known by them that chroms contained proteins and something that they called nucleic acids.
|
|
|
Early on proteins vs nucleic acids?
|
Proteins were known to be more chemically complex than nucleic acids, they were known to be the parts of the cell that had structure and function and seemed to be chemically more important and were therefore originally expected to be the genetic material, in contrast the nucleic acids appeared to be the same no matter what org they came from.
|
|
|
After WWI and during WWI,
|
bacteria had killed more ppl than the combatants so Griffith was interested in the inheritance and characteristics of pathogenic vs not pathogenic pneumoniae. It was known at that point that there were 2 morphotypes of this bacterium. One that produced smooth colonies were able to cause disease whereas there was a morphotype that produced rough colonies was avirulent. So here we have two types of apparently the same org where there is a phenotypic diff. these things can be differentiated morphologically and they have a difference in virulence. So to begin, Griffith shows that if he injects living S bacteria in to mice they die, whereas if he injects living R bacteria into mice, they're fine. His first exploration is that he takes S bacteria and he kills them and if they no longer grow in the culture then they can't cause disease. And then he does something quite ingenious and that is that he injects the living type R and the type S into the same mouse at the same time and the mouse dies. When he extracts the bacteria from that mouse, he sees that he has live S type bacteria. He calls this a transformation and he says the transforming property must be heat stable so what this is telling us is that although proteins are the more chemically variable and functional forms of the chemistry of cells, they are not heat stable and there is a heat stable substance in the cells that is capable of transforming avirulent cells into virulent cells. So here is a clue and a hint that it's not protein and that it could possibly be nucleic acid.
|
|
|
Avery, McLeod, McCarthy?
|
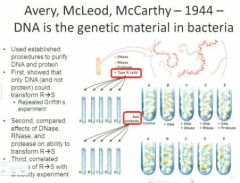
This question is taken up by a number of people, most notably these peoplevvv
The first thing they do is to repeat what Griffith did. This time though they have some extra tools. Not killing mice anymore. From the S cells, they're going to purify DNA, protein, RNA, and then they're going to ask the question which of the components of the S cels can transform the R cells? It is essentially impossible to say that you only have the protein, the DNA, or the RNA, so they add a second aspect to this. They want to be extra sure so they take an enzyme that can fragment the DNA called Dnase and use that to act as another kind of control. So they have their control cells, the R cells, plus SDNA, etc. SO now they ask the question. If we take the components and enzyme combinations where do we get the ability to transform the virulent avirulent R cells into the avirulent S cells? What they find is that in the first instance, they see trnasformation when they take the R cells plus the S DNA, but if they treat the SDNA with DNAse then the transformation ability is lost and it's not lsot if they treat it with rnase or protease. They done a more subtle experiment because they've added the factor that they expect is going to b etransforming and they try to break it down in a number of diff ways. They know also however that the transofmation might not be 100% efficient so they add another level to the expeirment and what they do is take an antibody that can coagulate the R cells but not the S cells and they mix this in with all the various treatments and allow the R antibody to agglutinate the R cells which they then remove from the mixture with centrifugation so now they have all of the mixtures that we talked about and now they're going to remove any potential R cells which could perhaps complicate the interpretatino of the results.vv The antibody they have binds to Rcells (removed by centrifugation). And what they see in the end is that the control cells have a defined colony phenotype. If they add the DNA they see a dramatic colony phenotype change. If the control cells have one colony phenotype on the plate if they add the DNA extract they`ll see a dramatic change in phenotype which can be prevented by treating with Dnase but not with treating with Rnase or protease so here again we have evidence that the transforming principle is DNA.vv |
|
|
Hershey and Chase - 1952 - DNA is the genetic material in T2 bacteriophage
|

This is followed up a few years later with a much more sophisticated study. So far what we`ve seen is that DNA is the transforming principle for bacteria. Is this a universal principle or is this somehow just for bacteria. H & C another group of researchers take the study into a diff type of organism. These are the bacteriophages which are bacteria specific; they are only composed of protein and DNA. Whereas before they were worried about all this stuff, these guys are only protein and DNA. Viruses attach themselves to the surface of a bacterium and they inject their DNA through the protein-atious sheath into the cell and down in that cell we have the invading DNA encodes the synthesis of more virus like particles. Now we have a case where we`re going to be able to distinguish the effect of is DNA carrying the message into the bacteria or is protein? What H and |C are going to do is they're gong to lable the bacteriophages by growing bacteria on either p32 radioactive phosphorous for labeling the dna or they're going to grow cells on s35 to label the protein they're goin to allow the viruses to infect these labeled cells and after a few gens we're going to wind up with selectively radioactive bacteriophages where either the dna or the protein has a radioactive label.vv
Phages are an excellent model system. Contain dna in capsule head surruonded by protein. Can be chemically and spatially separated. Chem separated b;y the fact that the dna will be labeled by phosphorous 32 and the protein is labeled by sulphur 35 and these are going to be used to infect bacteria.vv Also new tech for the time: Blenders They took the bacteria, allowed the labeled phages to infect the bacterium, inject the DNA into the bacterial cells and then remove the empty coats from the inside. So what they've done is infected ecoli cells with lableed bacteriophage and then after the bacteriophage has emptied itself of its dna content then they've removed the empty phage particle and looked at where the radioactivity is. They taken their cells they've sheared them apart , then they've centrifuged them and looked for where the radioactivitiy is. If it's in the protein then you'd expect it to find it in the super natant ? If its in the phage coat that is not going to be able to palate effectively so you'll find it in the super natant. If the radioactivitiy has been transferred into the ecoli then you will expect to find it in the palate and that is indeed what they find. They find the p32, the dna marker, is in the palate. So now we have very strong evidence that DNA is the transforming principle not only in bacteria but also in other kinds of organisms and in this case viruses. |
|
|
How were these people detecting radioactivity?
|

Two easy ways. In the early 1900s, they did it with geiger counters. By the time H and C were doing their experiments they could use Scintilation counters to see exactly where the radioactive decay events were taking place so they could determine that when the phage were first infected by the phage that the radioactivity regardless of f35 or p32 was all found in the same place but as the sheering continued you could begin to see a diff in the distribution of the radioactivity.vv
|
|
|
Before Chargaff, it had already been known that...
|
nucleic acids were relatively simple (sugar and bases).
|
|
|
What Chargaff did (1950)...
|
was to isolate DNA from many speciess and determine the relative proportion of the four bases and within experimental error, he discovered that the amount of adenine was approximately equal to the amount of thymine and same for c=g. So this was key to showing that DNA was probably double-stranded
|
|
|
xray diffraction?
|
- dna was extracted from cells, placed in the path of high intensity xray beam
- diffraction pattern - it had been imagined for a while that it could be a brush like model with the ncleotide bases being exposed - the info appeared to be held on the inside of the moll - watson and crick created what appeared to to be a very robust model - sugar phosphate backbone. sugar and phosphate sugar and phosphate - strands are anti parallel - one strand it has a 5 prime phosphate exposed at its end with a 3 prime OH at the other end - critical for how dna is replicated, transcribed into RNA, and translated into protein. - the antiparallel nature is important for its structure and for its function - base pairing here is by hydrogen bonding between polar residues on purine which has a double ring structure complementary bonded to a thyrimidine so we have complimentary structure and complimentary function. - sugar-phosphate backbone is deoxyribose |
|
|
Between the two dna strands, the bonding is...
|
hydrogen bonding
|
|
|
The hydrogen bonding between the two dna strands is relatively weak so
|
compared to the covalent bonds that join other atoms in the molecules, the hydrogen bonds are relatively thermally labile which means they can form and disperse depending on temperature which is going to be consistent with other aspects of the biochem.
|
|
|
You can split apart the double dna strands without
|
without losing the info. And you'll see later on that the info encoded in the strands is in the order of the bases in the strands, not whether they're at any particular time hydrogen bonded together…
|
|
|
We know now the fact that dna is going to be the gen material… And we have information that says it is double stranded and that the concentration of a and t vs the conc of g and t is approx equal, so the suggestion...
|
that was already apparent to w and c back in 1953 was that one strand can encode its complement and that this would provide the theoretical mechanism for understanding replication.
|
|
|
Theoretically, you can nevertheless imagine 3 ways that replication could take place.
|

You could have a parental strand where each strand encoded a daughter strand and then each strand encoded a daughter strand again. You could imagine a case where each parental strand encodes a daughter strand but the daughters are segregated from the parent. So here you could have one parent strand being followed through generations. Here we have both parent strands segregating together and all of the daughter strands segregating together. Or you could imagine a case where there's a mixture where we have encoding of daughter strands and these are intermixed throughout the daughter strand population.
|
|
|
How do we figure out which replication method is so?
|

Meselson and Stahl (1958) used another feature of isotope chemistry. Used stable isotopes as opposed to radioactive isotopes. Grew bacteria in heavy nitrogen for many generations until all the DNA in those cells and all the molls in those cells had heavy nitrogen then they transferred those samples to ordinary light nitrogen medium and extracted the DNA at short intervals so the duplication time of ecoli is between twenty and thirty minutes depending on diff factors. So essentially what they did was isolate dna from the cell populations at the point when they had been growing for a long time on heavy nitrogen and tat time periods corresponding approx to generations growing on light nitrogen. They extracted dna and wanted to know about the density so they centrifuged the dna they extracted in cesium chloride which can be generated at an appropriate conc for separating minor differences in dna density based on nitrogen isoptopes. Vvv
What they saw here was that from the heavy population they had a band of a particular density but shortly after they transferred from heavy to the lighter nitrogen they began to see two bands . By the time they had completed one cell doubling in the light nitrogen there was no more heavy dna left. As time went on the light nitrogen continued to accumulate in the dna so they'd gone from the heavy to the half heavy. This was maintained throughout the generations but the proportion of light nitrogen dna continued to increase. The half heavy never disappeared but the light continued to increase which suggested that the replication mechanism is semi conservative meaning that each parental strand encodes a daughter strand and that the original heavy nitrogen in dna is maintained indefinitely but the proportion of light nitrogen dna increases with each generation after the transfer. |
|
|
Okazaki fragments?
|
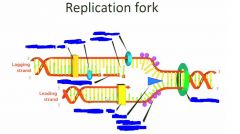
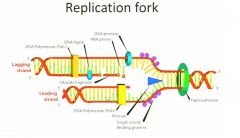
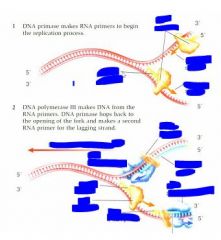
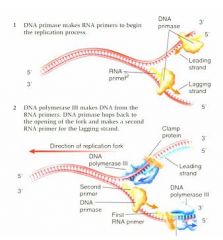
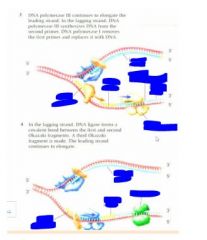
In order for Dna synthesis or dna transcription there has to be a free 3'OH. The 3'OH strand is fine but the 5' strand cannot act as a site for dna synthesis. For a long time ppl looked for 3' to 5' syntheases and they simply do not occur. What does occur is that for this strand that has the 5' phosphate, there is interrupted backwards synthesis. In other words there is synthesis of short. We have the spooling out of a single stranded dna and then the backwards copying 5' to 3' of the complimentary strands and then these are stitched together. This was discovered by a team of Japanse scientists. Ogasaki fragments. So while things are going very easily on the leading strand, on the lagging strand, we now have to have x extra steps. Spooling out of the dna which has to be stabilized by binding proteins and then you have a new enzyme called a primase which creates a short rna template primer with a free 3'OH so we can have backwards synthesis of the lagging strand and then the rna primer is going to be edited out and the gaps filled in by dna polymerase and then the whole thing stitched back together
|
|
|
rna/dna primase?
|
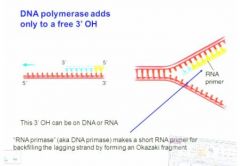
DNA polymerase only adds to the free 3'OH cannot add to the 5' phosphate but this 3'OH can be on DNA or RNA. DNA requires a free 3'OH but RNA can actually land on a sequence and begin without an existing 3'OH so the RNA primase creates a new free 3'OH for DNA synthesis to begin on the lagging fragment. Vv
Here we have an RNA primer which is added by RNA primase and from that we have the 5' to 3' synthesis of the dna strand and then this is going to be...vv So we've got the rna primer which is created by the rna primase (also called dna primase) this is going to make a short fragment that will permit dna synthesis again and then eventually this rna primer will be edited out. There will be filling in with this fresh dna and then all of this is going to be hooked in together.vv |
|
|
full youtube explanation
|
When dna replicates, its strands are separated by the enzyme helicase. Single stranded dna binding proteins keep the strands from realigning. One dna strand encodes the leading strand which forms from it's 5' to its 3' end using dna polymerase 3. No problem here but the lagging strand presents problems. It has to form from 5' to 3' too. It forms in pieces called Okazaki fragments. First an RNA primase lays down an RNA primer then DNA polymerase III lays down new DNA. The process repeats again and again. DNA polymerase I replaces the RNA primers with DNA. Finally DNA ligase links the Okazaki fragments.
|
|
|
Dna polarity?
|
The second fact is that DNA has a polarity. The DNA polymerase can only work from the 5' end to the 3' end. To understand this we need to look at the DNA structure. This photo shows a single strand DNA structure. No matter how long this single strand is, there will only be one free phospher group on the very top and only one free OH group and the polymerase can only elongate the strand from the 3' end. So this is the polarity of the DNA replicationvv
|
|
|
dna is anti
|
anti-parallel
|
|
|
continuous / discontinuous?
|
Continuously is the leading strand, lagging strand is discontinuously.
|
|
|
DNA replication in E.coli?
|
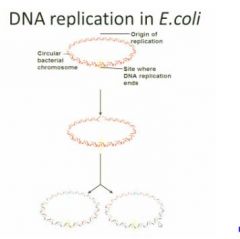
E. coli is a circular DNA structure so there's no free end. So on this circulr structure, the replication can only start from one side and this part has a special sequence. This sequence can be recognized by an enzyme. The enzyme will bind to the sequence and open the double strand of DNA and before the polymerase is added to the dna, it can't bind to the double dna, it needs to bind to the single dna. So the initial step is to open the double dna, then dna polymerase and other enzymes come and duplicate dna from there. And dna replication in Ecoli is bidirectional meaning there are two sites of identical enzymes to synthesize the half circles simultaneously. Two sides syntehsize at a constant speed. When they meet at the end site, they deassociate from the DNA moll and make two copy of dna structure in the cell.
|
|
|
RNA primer is only about ______ nucleotides long
|
8-12 nucleotides long and this phenomenon is also found by Okazaki
|
|
|
Beginning DNA synthesis?
|
The beginning of dna synthesis is just to open the double strand of dna and getting the polymerase to bind to the single strand. You need several enzymes to work here. The very first and important enzyme is called DNA helicase. It's like a ring. It will bind to a single strand dna and moving along the dna structure towards to the double strand part. In that case we open the double strand to a single strand.
|
|
|
The second protein in dna replication?
|
The second protein that needs to be used here is the single-strand binding proteins. Because single strands are not stable in the cell, they tend to anneal together which means they will bind back together as a double helix or they will be hydrolized by dnase in which case they will be destroyed. So to avoid this the small proteins which is binded to the dna to stabilize it as a single strand.
|
|
|
Topoisomerase?
|
Then there's the dna topoisomerase. The function is to solve some sterical problem when you unwind the double helix of DNA. It solves the supercoiling problem.
|
|
|
topo1?
|
Topoisomerase 1 enzymes cut a single strand of the double helix, pass the other strand thru the cut and seal the break, relaxing the overwound moll which now has one fewer twists.
|
|
|
topoisomerase 2?
|
Topoisomerase 2 enzymes do the same thing but with both strands of the double helix. Topo 2 cuts both strands of a double stranded DNA, and passes another double strand through the berak and then reseals the break so if a moll of dna is supercoiled topo 2 can remove the supercoiling two twists at a time.
|
|
|
So with the help of topoisomerase the helicase ....
|
So with the help of topoisomerase the helicase goes thru all the dna circle and separates the whole thing. This is the first step and then polymerase comes and synthesizes the whole strand. At the beginning it's just topo and helicase, then you've got these other ones….:
|
|
|
Right after the double helix is separated...
|
Right after the double helix is separated, the dna polymerase can't really bind there so it needs a primer structure and we'll have dna primase which is actually an rna primer but we'll call it dna primase. DNA primase is very short. On the leading strand you only need one primer, but on the lagging strand they need many primers.
|
|
|
After you have the primary structure,
|
polymerase will come to synthesize a new strand.
There are three dna polymerase in ecoli 1, 2 and 3. The number indicates when they were discovered, but we know 3 is the main one to synthesize replication. 1 is also important to synth in the lagging strand. 2 we don't know much about because it's not essential in ecoli.vvv |
|
|
|
|
|
|
|
|
|
|
|
On the lagging strand, if we have a polymerase start from the primer structure and moving along the strand...
|
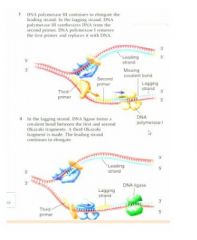
it will eventually meet or face to the primary structure of the last okazaki fragment and then it can't process any more and then at that point dna polymerase 3 is replaced with dna polymerase 1 and the function of poly 1 is to remove the rna structure from the okaz fragment and replace the rna by dna so after that you will have several okaz fragment on the lagging strand and they are all dna structure but it's still not very ??????DNA ligase - covalently attaches adjacent okazaki fragments
Because they will still have some spaces which is the missing covalent bonds. On the lagging strand because the poly 1 can't join the okazaki fragment and how you fix this is with the dna ligase which will join the fragments by the suagar backbone and then all the okaz fragments will be joined to be a single strand. So that is the step sof how it happens in ecoli. Polymerase I - removes RNA primers and fills the gaps Polymerase III - replicates most of the DNA during cell division |
|
|
Natural mistake rate of polymerase is
|
1/10^5
|
|
|
Genome size of e.coli is
|
4*10^6
|
|
|
how many mistakes per replication?
|
40
1/10^5 is a high mistake rate considering the size because it makes 40 mistakes per replication. |
|
|
1, proofreading function of DNA polymerase III and I
|
direct remove and repair the mismatch base: 1/10^10
If it's the right base pair, they continue but if it's wrong, they remove it and add the right one. |
|
|
2, mismatch repair system:
|
remove part of DNA after synthesis shortly: 1/10^11
|
|
|
This is not how many mistakes happen in
|
vivo, only in vitro. The repair mechanism makes up the difference.
|
|
|
In vivo it`s one mismatch per
|
per ten billion
|
|
|
dna repair system?
|
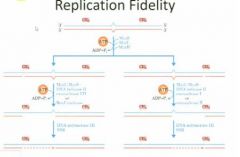
The repair enzyme is composed by 3 proteins, MutS, MutH, MutL. We use ATP as the energy to scan. In the middle of this strand is a mismatched pair. The repair system will cut a piece of small DNA from the new synthesized dna strand and then leave a gap there. After that dna polymerase 3 will come to fill the gap as it did in replication. How can the enzyme recognize what's the old strand and what's the new strand? On the top dna structure, there are two methyl groups. Methylation is done by a specific enzyme. Methylation is common in old orgs. There will be many methyl groups on the dna. This repair system must happen shortly afterwards because it must happen before the methylation occurs. By having this repair system, it brings the mismatch rate to one mismatch rate in ten billion.
|
|
|
helicase
|
unwinds the dna
|
|
|
topoisomerase
|
relaxes dna supercoiling
|
|
|
single stranded binding protein
|
protects the single stranded DNA
|
|
|
primase
|
adds a short RNA primer
|
|
|
DNA polymerase(s)
|
synthesize new DNA in a 5' to 3' direction
|
|
|
Ligase
|
join DNA fragments into a continuous strand
|
|
|
bacterial dna replication begins at a single, defined dna sequence of
|
245 base pairs called oriC
|
|
|
DnaA?
|
A protein called DnaA increases in conc as a cell grows and gets ready for cell division. This protein, as a complex with ATP, controls the onset of initiation of cell division by binding to specific 9-bp repeats at oriC. The binding distorts the DNA, leading to the opening of adjacent 13-bp repeats in the DNA.
The opening in the DNA allows protein complexes to enter the replication bubble and bind to the single-stranded DNA. Each complex consists of a DNA helicase and a DNA helicase loader. |
|
|
DNA helicase loaders?
|
The DNA helicase loaders open the DNA helicase protein rings and place the rings around the single-stranded DNA. The loaders are then released.
|
|
|
helicases?
|
The helicases use energy from ATP hydrolysis to unwind the DNA helix at each of the two replication forks.
Each DNA helicase recruits an enzyme called DNA primaswe, which synthesizes an RNA primer on the DNA template. |
|
|
RNA primers?
|
An RNA primer has on its end a 3' hydroxyl group, which is required as a starting point for DNA polymerase to add DNA nucleotides.
|
|
|
The main replication polymerase in E.coli is called
|
DNA polymerase II
|
|
|
DNA polymerase II complexes...
|
are ferried to the replication forks by protein complexes called clamp loaders. Clamp loaders also carry other protein complexes, called sliding clamps.
|
|
|
The clamp loader places....
|
places the sliding clamp onto the DNA. It then places an attached DNA polymerase III complex next to the sliding clamp. The sliding clamp holds the DNA polymerase in position on the 3'end of the growing strand as the polymerase synthesizes new DNA. Nucleotides with complementary bases to the template strand are added one by one in the 5'to3' direction.
The synthesis of DNA in the direction of the fork occurs continuously to the end of the template. This new strand is called the leading strand. In contrast, the other new strand, called the lagging strand, is built in fragments, called Okazaki fragments. |
|
|
The template strands are anti-
|
anti-parallel with their 3' and 5' ends oriented in opposite directions
|
|
|
Because DNA polymerase can add nucleotides only in the 5' to 3' direction,
|
the leading strand grows continuously in the direction of the replication fork, but the lagging strand can grow only in short segments as the parental DNA molecule unzips.
|
|
|
single strand DNA binding proteins
|
quickly coat exposed single-stranded regions of DNA and protect the single-stranded DNA from attack by nucleases
|
|
|
the polymerase and the sliding clamp disengages when
|
DNA replication continues as the DNA polymerase on the lagging strand meets the 5' end of the next primer, causing the polymerase and the sliding clamp to disengage
|
|
|
After DNA helicase has moved approx 1000 bases,
|
a second RNA primer is synthesized at the fork. The sliding clamp loader adds a new sliding clamp to the primer, and then adds the DNA polymerase to begin synthesis on a new Okazaki fragment
The cycle continues for the length of the template strands The lagging strand now consists of Okazaki fragments with a segment of RNA at one end. The RNA is cleaved by an enzyme called RNase H. Another enzyme called DNA polymerase Note that the lagging strand now consists of Okazaki fragments with a segment of RNA at one end. |
|
|
RNase H
|
The RNA is cleaved by an enzyme called RNase H
|
|
|
DNA polymerase I
|
Another enzyme called DNA polymerase I uses the 3ÒH group of the adjacent Okazaki fragment to fill in the large gap with DNA nucleotides.
|
|
|
DNA ligase
|
Finally, an enzyme called DNA ligase closes the remaining nicks on the DNA, leaving a continuous DNA moll.
|
|
|
Diff between prok ecoli and euksÉ
|
there's only one dna structure and there's only one origin side on the circular structure. But in euks there's more than one chrom and on each chrom there's more than one origin side.
This is because euks have quite a big chrom size which is usually hundreds or thousands of times larger so if they have only one replication side it would take a really long time to finish the replication and all these sides can start simultaneously. Second key diff is in euk there are 5 dna polymerase and two are responsible for dna replication in nuclear and 2 are responsible for the repair system and last is responsible for dna replication in mitochondria but not in the nucleus Last is most important diff. This diff is in the dna structure. In proks it's circular and in euks it's linear. The linear chrom proposes a problem: no problem for leading strand but for lagging strand there's no primer structure at the end so if you don't have the primer structure, there's a part that you can't replicate. So euks have an enzyme called Telomerase to solve this problem which is composed of short piece of rna and a protein; funciton is to repeat a sequence many times at the end of the linear chrom.vv |
|
|
TelomeresÉ
|
polymerasesm work with a backstitching mechanism. RNA primers provide free 3`hydroxyl groups at regular intervals along the lagging strand template. The lagging strand stops short of the end. Even if a final rna primer were built at the very end of the chrom, the lagging strand would still not be complete. Because of this inability to replicate the ends, chroms would progressively shorten during each replication cycle. Telomerase recognizes the tip of an existing repeat sequence. Using an RNA template within the enzyme, telomerase elongates the parental strand in teh 5`to 3`direction and adds additional repeats as it moves down the parental strand. in this way the original info at the ends of linear chroms is completely copied in the new dna.
Scientists postulate that the length of the telomere has to do with the life of the cell and this has to do with cancer cells so this is a hot spot for research. It might provide a way to make us forever young. |
|
|
life cycle in ecoli sometimes shorter than dna replication cycle. How could that happen?
|
you don't need to wait for it to be finished.
|
|
|
DNA replication is semi
|
semi conservative
semi continuous |
|
|
DNA replication only happens in one
|
one direction
|
|
|
How do you look at dna replication in vivo?
|
by looking at e.coli structure
e.coli dna structure is circular and there's only one structure in e.coli. After replication starts, it happens in the two directions simultaneously. Helicase is like a ring and it moves from single strand towards double strand and it breaks the hydrogen bond in between the two strands. DNA topoisomerase relaxes the supercoiling that the helicase causes. |
|
|
Any given org wants to pass its dna on ...
|
as accurately as possible with the least amount of mistakes
|
|
|
there's _______ repair mechanisms
|
2
|
|
|
The first repair mechanism...
|
The first is based on dna polymerase III and I. The DNA polymerase starts at the 5' end… going to the first side to check what's the base on the template and checks the base pair to see if it's right or wrong and if it's right it goes to the next one.
|
|
|
The second repair system is happening after synthesis
|
upper part is old strand, lower part is new strand and there's a mismatch in the middle. So enzyme scans until it finds mismatch and it stops there and then recruits other enzymes to cleave this part and remove a little piece of the dna from the new strand. After removing a piece of dna, the dna polymerase III which is the one used in dna replication will come to fix this gap and then it fixes this mismatch problem. However the second problem for this repair system is how does the enzyme know which one is the new strand and the old strand? The methylation. It'll have many methylation sites. When it's being replicated it'll give you two diff dna structures in the end. Repair mechanism must happen shortly after before methylation happens. That's how you get to one mistake per ten billion.
|
|
|
Insulin?
|
Insulin which treats diabetes is discovered in 1920s and shortly after ppl found it had an effect on diabetes but at that time there was a problem that you can only extract it from animals and if u used animal insulin to treat humans you got a side effect; second problem was the price because you got so little from each animal; in 1970s with development of moll technology ppl figured out how to use ecoli as host to develop human insulin so now it's affordable; used recombinant dna technique which is moll cloning.
|
|
|
If a protein wants activity, it needs a suitable
|
enviro and one critical condition is temp. For most human proteins we have suitable temp at 37 degree and if we get a fever, highest temp is 46 and if you get higher it's jeopardising life so we can use htis for PCR
|
|

|

|
|
|
original PCR
|
vvSo initial experiment: at the begininng you set up 3 water baths of the indicated temps. Then you take a tube and add the template dna and all the nucleotides as well as the primer into the tube and put it in the 95C bath for 2 min and then all your double stranded dna will be totally separated into single stranded dna.
Then you transfer the tube into the second water bath and cool it down to 55C. So here your primary structure is annealed to the single strand dna Then you take the tube out and put in the dna polymerase and put it in the 37C which is the best ttemp for the dna poliymerase to work so in here the dna polymerase will band to the primer site and start synthing the new strand of dna. The reason you added the polymerase at this step rather than the beginning is so that it isn't destroyed. They only get a small yield. Easiest way to get more is to repeat the process to double the yield. In each cycle you need to add dna polymerase in the third step and it's not a cheap compound. Each cycle is 5 minutes and if you do it 30 times that's 2.5 hrs so that's not a fun time so we use machines now. |
|
|
Scientists didn't think there was anything living in water nearly ______C so they just wanted to see if there was anything there and they found this bacteria so that means all its protein survives in hot water.
|

80 C
|
|
|
PCR components?
|
- template DNA
- dNTPs - Primers - Taq DNA polymerase |
|
|
brief PCR explanation?
|

|
|
|
After each mitosis cycle you're getting a
|
clone
|
|
|
YOu don't care if clones endup with exactly the same shape....
|
you care whether they have exactly the same genetic information
|
|
|
Which cycle doesn't produce clones?
|
meiosis
|
|
|
What's a common form of clones in plants?
|
grafting.
Most apples come from grafting Also using tissue culture techniques in a lab. |
|
|
omnipotent-ness?
|
All plant cells are omnipotent. In humans only the stem cells are omnipotent.
|
|
|
Farmers and gardeners have used vegetative cloning for_____________s of years`
|
1000s
|
|
|
dolly?
|

Take somatic cell from A and extract whole genome from that cell then you take egg cell from B and remove nucleus from there then you fuse the nucleus from A with egg cell from A which doesn't have the nucleus. After this, you culture it on a plate with medium which develops into an embryo which you transfer into a sheep which develops into a new lamb. So the new sheep has all the genetic info from A but it comes from the body of the sheep it was inserted into.
|
|
|
What kind of cloning will this class focus on?
|
cloning a moll or a piece of dna and is not cloning an org or a cell
|
|
|
plasmids
|
small circular dna structure naturally occuring in bacteria which can be replicated independently in the bacterial cell when it undergoes mitosis.
|
|
|
Bacteria always have plasmid because
|
it needs it because it has antibiotic resistent gene that makes ecoli resistent to certain antibiotic
|
|
|
The first RE found in Ecoli was
|

EcoR1
So for this enzyme, it scans along the dna double helix and when it finds a specific sequence as shown in the blue here, it stops and cuts the double strand and makes two smaller molls |
|
|
What is a palindromic sequence?
|
well when you read it in the opposite direction, you read the same sequence
|
|
|
Each restriction enzyme can only work in one
|

in one way
|
|
|
with plasmids the function of ligase
|
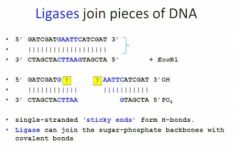
is the same as in dna replication which is to draw the dna fragments together as one dna fragment.
At the beginning here vv we have a double strand dna and we use EcoR1 to cut this double strand dna because it has a restriction enzyme for EcoR1 and then you have two small moll that look like that. So we can see here for the sticky end of this it's totally complementary. When they're complementary, they're compatible sticky ends, so they'll tend to create hydrogen bonds but without ligase they'll break again later. Ligase provides an opportunity for them to be very close. |
|
|
Only when the sticky ends are compatible
|

can they bond
|
|
|
ampicillin resistant ecoli experiment?
|
In one tube we have a plasmid and we add EcoR1 as the RE. Because this plasmid has been engineered to have only one RE for EcoR1 so we only cut this plasmid at one position and make the circular dna structure into a linear dna structure.
Then in another tube, we have our human dna there and also added EcoR1 in that part. The human genome is very big and probably has many EcoR1 sites so in the end what we have is there are many dna fragments cut by the EcoR1 and on the end of each fragment there's a sticky end for Ecor1 because they are all cut by EcoR1. Then we purify the linear plasmid from Tube A and then we purify a piee of dna fragment from tube B and then we assume that in the tube B the fragment that we have we extract from there is having the insulin gene for humans so we assume this is the blue part here and you can in fact purify any part from solution. After we purify these two part together and put them together in one tube it will ook like this, you have linear dna structure from tube a and you have small piece of dna from tube b. So right now if we add the ligase in this tube, the ligase will join the sticky end together and make these two fragment binding together and forming a bigger circular dna structure like that and in this case we successfully insert a piece of human genome into a plasmid and this what we call a recombinant plasmid vector. So next, you just need to transfer this new plasmid to Ecoli. So you transfer this thing to Ecoli on a plate that's containing ampicillin so only the ones which contain the plasmid can grow. |
|
|
Electrophoresis separates molls by
|
charge and size
|
|
|
DNA and RNA have uniform __________________ charge
|
-ve
|
|
|
DNA ladders are
|
mixtures of fragments with known size
|
|
|
using diff primers
|
gives you diff sizes.
diff primers gives you diff sequences |
|
|
difference between sequencing and PCR?
|
- Need taq polymerase, DNA template, primers (only one primer unlike PCR), dNTP, ddNTP (unlike PCR). There's no 3'oh group on ddNTP and we have known from dna replication that 3'oh group is very important for elongation... without it you can't have the next nucleotide binding to elongate the strand... so in that case whenever a ddNTP is integrated into a growing band, the band will stop there and not be elongated any more because there's no 3'oh group. The next nucleotide will band to the 3'oh group... if there's no 3'oh group that reaction can't happen so it stops there. ddNTP is a very similar structure to dNTP.
|
|
|
Sanger DNA sequencing: ?
|
- Put that stuff in then what happens in the machine? Similar to regular PCR process. Heat up tubes to 95C and then double strand is separated into single strand, then you cool to 55C so the primer is annealed to the single strand> After that you start with the elongation step which is 72C and in this step the taq polymerase will work from your primers and to elongate the primer structure according to the template.
|
|
|
Sequencing industry is developing very fast....?
|
This is another sequencing technique right now. This technique started in 2008 and it became available in 2010. This technique can produce a huge amount of data shortly and cheaply. Human genome project was happening from 1990s to 2000s which cost about 3 billion $ to finish. Here by having this technique we can do this in about 2 weeks. Some company is announcing that it only costs several thousand dollars to sequence the human genome. So this provides the possibility to sequence every person's genome and also provides the possibility to sequence every organism, but right now it's so easy and so fast. This technique does have problems though that it can't target any gene, it has to be the whole genome (unlike Sanger). Also this method relies on the computer to analyze because you can't analyze it yourself because of the huge amount of data.
|
|
|
central dogma of molecular biology means
|
that the genetic info that is gong to encode proteins and other regulatory sequences that permit the formatino and functioning of a cell is contained in the dna that`s in the nucleus or in the nucleoid region in a euk cell or a prok celk. This is the library copy, it doesn`t actually have a direct functioning application to the cell because it has to be transcribed into an rna moll so rna and dna are comparable in nucleotide sequence so they contain the same kind of info but they`re differently regulated in terms of activity and stability so it`s going to be copied into an rna moll and this is going to be encoded into a polypeptide, the protein which has the structural or functional role in an enzyme.
|
|
|
where does 3`oh and 5`phosphate come from?
|
Sanger's sequencing is a fundamental method for determining the nucleotide sequenc ein a region of dna and it now has applications for sequencing rna as well. Here we have a standard nucleotide. In a nucleotide you have a sugar and this sugar is ribose. A dna base in this case it's cytosene which is a pyrimidine and it has a phosphate so when yo unumber the attachments to a sugar they're numbered from the carbon. So the 3' Oh comes from this and the 5' phosphate. With RNA you have a slightly different organization. For rna, you have a slightly diff organization but the important thing is that although in rna this is an h instead of an oh, both of them have a free 3'oh which is critical for dna polymerase and for rna polymerase to continue to add basesvvv
|
|
|
When can you polymerize and when can you not?
|
So here we have a cartoon of a double stranded segment of dna and so you can see that one end has the free 5' phosphate and the other end has the free 3' oh and if you have that you can polymerize and if you do not, you can notvv
|
|
|
because hydrogen bonds are relatively weak and numerous they can be separated by
|
heating the dna
|
|
|
ddNTPs?
|
How does this get used for sequencing? No wwhat we're going to do is to modify, use a mixture of nucleotides so that the vast majority can continue the dna polymerase reaction until the end of the extension cycle, but about 1 in 1000 are going to be special and what these are going to be is di deoxy nucleotides so ther is no free 3'oh this has been taken out so that as randomly some individual nucleotidse are incorporated polymerizatino is terminated at that nucleotide base and these are called terminators and so what's going to happen here is for eg a labled atp so it's got no possibility of continuing the polymerization reaction but it will have a tag that says here I am, so the poollymerization continues and then at some point at a random T because it's an AT base pairing you will have that particular strand is no longer going to be able to extend so if you have then a small number of these di deoxy atps, polymerization will start and it occurs at about a rate of 1000 base pairs per minute and it will continue continue continue and it will hit one of these di deoxy atps that has been tagged in a way that we'll be able to see it and that polymerization will cease but others going on at the same time in the same reaction from the same time are going to be able to continuevvv
|
|
|
Agarose is
|
a simple carb with 5 carbons water solutble at high temps and then it forms a gel sort of like gelatin except it's a carb gel instead of a protein gel and then it cools and the conc of agarose in the gel is going to determine the pore size (relative resistance to flow)
|
|
|
What makes dna and rna negatively charged?
|
the phosphate attached to it that has extra oxygens
|
|
|
Electro phoresis for dna sequencing
|
because we are trying to differentiate fragments that differ by a single base pair not by a thousand base pairs, you have to use a slightly diff gel that has a much finer pore size
|
|
|
in electrophoresis, DNA is visualized by
|
specific dyes
|
|
|
how do ddNTPs work in sanger sequencing?
|
there's going to be a tagged terminator that is going to interrupt dna synthesis at the complementary base pair for the nucleotide in question. So here if you're adding ddNTP you are terminating the sequence at the corresponding thymine (residue).
|
|
|
electrophoresis procedure?
|
you 've tagged your di deoxy atp, you run it all on a gel, at this point it's invisible, but you have separated the fragments one base pair after another by single base pair amounts and then you take the gel and overlay it with xray film. As the P32 undergoes a fission reaction it lets off a high energy gamma ray which exposes the gel.
|
|
|
You get a lot of sequence info in electrophoresis
|
for the first few hundred base pairs close to the dna primer and then relatively you see fewer and fewer and in order to continue to query that sequence, you generate another sequencing primer here and you do it again. This is called primer walking.
|
|
|
in the early days you could read up to
|
300 bp if you were lucky
|
|
|
later on the sequences were tageed with
|
a fluorescent primer instead of the 3'OH and what this allowed was to run all of the reactions together so you could do all of the sequencing in one tube instead of four tubes and you could have that combined product and run it thru a gel that at the bottom had a fluorescence reader so that it could tell you which colour of fluorescent tag was being processed (coming off the bottom) at any one time) This allowed for long reads.
This allowed for long reads. Longer reads are important because longer erads means fewer overlaps, fewer overall sequencing reactions and more fidelity. Increases in the affinity of some of the tags and the affinities and efficiencies of the thermostable dna polymerase now allows us to read up to a thousand base pairs for a single sequencing reaction. |
|
|
Sanger's seq is important...
|
even today even though we now have many other techniques for reading dna sequencing because it reads the template sequence directly and allows for high fidelity and for the ability to query a particular dna seq.
|
|
|
Other kinds of sequencing\??
|
Some of you may have heard of next generation sequencing which is often an entire genome which is fragmented into relatively short pieces and multiple overlapping fragments are sequenced often a hundred million fragments which are overlapped overlapped overlapped to permit figuring out what the consensus sequence is. Sanger's is an important first step because it provides an unambiguous read of the backbone. So if you are doing multiple sequencing then you will have multiple overlapping fragments and it is the consensus that it gives you the seq, but because there are so many copies of everything it is much more complicated, there is a lot more bio tech processing that has to be done to make sure that you are getting an unambiguous result.
|
|
|
dna sequencing detection depends on the
|
labeling method
|
|
|
in the 1980s you could read?
|
300 bp readable (32p)
|
|
|
1990s you could read
|
500 bp readable (fluorescent tag)
|
|
|
Nowadays you have sequencing software for
|
alignment and annotation
|
|
|
Before info in dna can be used it needs to be
|
transcribed in a process that is analogous but not entirely similar to replication
|
|
|
what is a gene?
|
a heritable unit of information
|
|
|
The part of a gene that mendel was studying is
|
the transcribed region which is the actual code for the gene product and it is the part which is eventually translated
|
|
|
upstream of the transcribed region towards the 5'end is
|
some important nucleotide seqs. The most upstream one is called the promoter and then there is a series of regulatory seqs which we now know are extremely important for determining how often a gene is transcribed.
|
|
|
If it can't be transcribed
|
then it can't be translated.
|
|
|
And at the 3' end there
|
there's a terminator
|
|
|
the promoter
|
allows the assembly of the rna polymerase that's going to copy the dna into rna
|
|
|
ther termintator
|
causes diassembly of the machinery so after the rna polymerase binds to the promoter and this is its ability to bind (controlled by the regulator) it transcribes and then falls off
|
|
|
and the primary transcript here is the rna and the transcribed region is the part that encodes the info for the translation product but this is going to vary dependin on what kind of cell we're talking about
|
and the primary transcript here is the rna and the transcribed region is the part that encodes the info for the translation product but this is going to vary dependin on what kind of cell we're talking about
|
|
|
gene expression requires
|
transcription and translation
|
|
|
promoter and regulatory sequence
|
binding sites for rna polymerase and accessory proteins
|
|
|
transcribed region
|
coding region
|
|
|
terminator
|
releases RNA polymerase
|
|
|
Difference between prok and euk transcription and translation?
|
So in a prok cell, you will recall that the nucleoid region in that cell is within the cytoplasm of the cell so that there`s no barrier between the dna and the translation machinery (the ribosomes). Much more complicated in euk cells because the transcription is occuring within the nucleus but the translation is occuring in the cytoplasm.
|
|
|
Why the difference between transcription and translation in prok and euk cells?
|
Why would euks do this? Because it provides an dextra level of control and organization so we can get more subtleties in the translation products for a euk sequence compared to a prok sequence. As soon as a prok gene is transcribed it si already available for translation, and in contrast in a euk cell there is a spatial delay and a temporal delay between transcription that allows for some processing in the nucleus so there can be differential processing of certain kinds of transcription products so you can get more than one kind of info out of a particular gene sequence and then after modification the mature messenger rna is going to be carried out into the cytoplasm and that's where it's going to be translated. So in euk cells transcription occurs, in the nucleus translation occurs, and in the cytoplasm and in contrast in proks all of this happens in the same place and essentially at the same time.
|
|
|
messenger RNA is abbreviated
|
mRNA
|
|
|
All cells: genes are transcribed into _______ __________ before translation into proteins by the ribosomes
|
messenger rna
|
|
|
the promoter region is important for
|
binding the rna polymerase to the double stranded dna and prepare it for unwinding using factors including the sigma factor because just like dna replication rna transcription requires that the double stranded dna be separated so that the nucleotide bases be exposed.
|
|
|
In order to not lose info , the transcription site is going
|
is going to upstream 5' of the translation start but then after it carries thru the dna it will end at the terminator
|
|
|
promoter region is
|
recognition site for sigma factor and RNA polymerase
|
|
|
DNA is unwound to create
|
the open complex
|
|
|
Trnascription start site is slightly upstream of the
|
translation start
|
|
|
transcription ends at
|
the terminator site
|
|
|
rna polymerase binding to the promoter site with accessory proteins including the sigma factor which are going to open up the dna double helix to allow for enzyme activity so it requires a polymerase as with dna replication and in this case it's rna polymerase because rna is going to be transcribed from the original dna seq
|
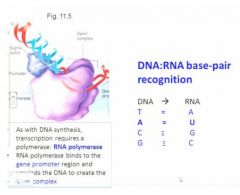
|
|
|
diff between dna and rna
and stability of rna? |
because for dna you have four bases and for rna although you also have four bases, instead of thymine you have uracil, uracil is also a pyrimidine and it base pairs with adenine, it forms the same 3 hydrogen bond coordinate bonding but it is an older kind of nucleotide and it is somewhat less stable. The stability of the rna product then is somewhat lower than the dna product and this is important because if it were not that rna were somewhat more ephemeral when you transcribed dna into rna then that gene transcription product would be maintained in the cell for a long time so it's important for messenger rna not be stable, it has to be able to be turned over so the cell can not only turn on gene function but also turn it off again.
|
|
|
unlike dna replication, we are only going to be transcribing
|
one strand. Only in the 5' to 3' direction, so there's no okazaki fragments in the transcription process.
|
|
|
the open complex allows
|
the access of rna nucleotides into the transcription site
|
|
|
RNA polymerase dissociates at the terminator, and is available to
|
transcribe a new gene (or the sme one again)
|
|
|
In prokaryotes, as soon as the mrna as been transcribed from the dna,
|
the ribosomes can land on that primary transcript even before it is complete and they can already be translating protein so it's a very fast and efficient process and this is part of the reason that prok life cycles can be very fast, because there's no waiting here.
|
|
|
eg of quick rna synth in proks?
|

immediate landing of the ribosomes onto the transcript and they can begin peptide synth even before the message is complete so you can see here we have the earliest transcribed mrna and ribosomes that are working along that mrna and are translating it immediately as it is transcribed
|
|
|
In euks there are exons which are
|
the part that';ll be translated
|
|
|
introns have to be
|
spliced out by a euk specific regulatory mechanism
|
|
|
There are recognition sequences that these protein machines can land on so that
|
these parts are precisely spliced out and then the mature messenger rna is transcribed
|
|
|
So why would you do this intron exon thing?
|
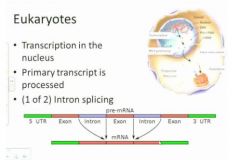
It seems like an awful lot of work and somewhat risky but what's happening here is that if you have a single primary transcript in some cases you may choose to remove all the introns, if you're a cell. In some cases all of the introns will be removed and you'll have a full length transcript, but in other cases you have differential processing at this stage that allows the cell to encode more that one kind of translation product for a given transcript so this allow the euk genome to have tremendous amount more flexibility.
|
|
|
poly a tails?
|
other thing happening here is that the 3' end of a euk transcript is modified at this stage by adding what's called a poly a tail so this is a polyadenilation chain which is added here and the poly a chain has some very important features, it is added to a recognition site here and it is in fact the gate keeper which allows the mature message to leave from the nucleus out into the cytoplasm so the poly a tail then is the cellular message that allows the mature message to leave from the nucleus and get out into the cytoplasm
|
|
|
The poly a tail is then the
|
cellular message that allows the mature message to leave from the nucleus and get out into the cytoplasm so there's a signal site and this signal site as you can tell is in rna cause there is uracils rather than thymidines and so what's going to happen here is that after the message has exited into the cytoplasm then translation can take place so you have the message with a poly a tail, this can be translated translated translated, however at the end of the translation activity cycle, the poly a tail is removed and the poly a with the removal of that poly a tail then the message is targeted for depolymerization and for recycling.
|
|
|
eg of regulation
|
there are regulatory seqs that are important for determining the relative activity of binding of the rna polymerase complex.
There are regulations in the accessibiliyt to splicing and there are alternate splice sites so you can get more than one kind of protein product from a message. Then there's regulation as the mrna is taken out into the cytoplasm because it has to interact with a protein complex to get there and then finally there's regulation by the timing and relative activity of poly a degradation that is going to turn off translation |
|
|
There are no introns in
|
proks
|
|
|
In proks the primary transcript is translated directly
|
into protein
|
|
|
In euks it's more complicated than in proks (rna synth) because
|
IN euks it's more complicated cause the primary transcript is subject to rna splicing and processing which allows for differential regulation of the message so tha tmultiple kinds of transcripts can be translated from a single message and in particular the introns of some important internal regulatory sequences. There's also the addition of a poly a tail which is important for getting the transcript out of the nucleus where it si formed but cannot be translated into the cytoplasm where it can be translated and regulated.
|
|
|
Summary of dna transcription:
|
This is the summary for dna transcription, you have the double stranded dna, you have the landing of the rna polymerase on the promoter region , you have the opening of the double stranded dna helix, you have the copying of one strand and one strand only into rna dn then in a a prok you can have immediately translated product and in a a euk you have to have additional processing and moving of that primary rna out into the cytoplasm.
|
|
|
ribosomal machine?
|
It's a two part machine made largely of ribosomal rna subunits and these are going to be decorated with proteins that provide functional information.
|
|
|
RNA polymerase dissociates at the terminator and...
|
is available to transcribe a new gene (or the same one again)
|
|
|
Ribosomes are rna...
|
rna protein machines
|
|
|
ribosomes come in two...
|
two subunits, the large subunit and the small subunit and these are very diff functions
|
|
|
(general overview of ribosome function cycle starting at end of translation) When translation is over...
|
ribosomes dissociate so that they get reused one association for each translation event so what's going to happen here is that the small subunit shown here in blue is going to be where the message is bound reversibly and this is going to be where the decoding is for the information that's in that message and is the large subunit that's going to be involved in polymerization of the protein product.
|
|
|
in depth understanding of ribosomes?
|
all this now is understood extremely well with high structural detail. About four years ago the final crystal structure was solved in high resolution so now we have very precise information about how this is done. And as many things go in science, this was not an individual effort but was a collaboration and it was an international collaboration.vvv
|
|
|
The different ribosome subunits are called
|
ribosomal cores
|
|
|
there are many _________ associated with each ribosomal core
|
proteins
and each one has functionality |
|
|
Back when ribosomes were first evolvinb
|
there would not have been proteins, this entire catalytic cycle would have just been the ribosomal rnas.
|
|
|
there are parts to these ribosome subunits and these are homologous but not absolutely identical in bacteria and in euks
|
the bacteria ribs are somewhat smaller than the euk ribs
|
|
|
Svedverg?
|
S in this case stands for Svedverg. Back when cell biologists and physiologists were trying to understand how the relative size of diff machines, they had to develop a methodology for doing this and Sved came up with the idea that if you centrifuged a suspension fo small aprticles, the rate at which they moved thru the suspension when accellerated by a million gravities which we would generate would be consistent measure of sedimentation. So S is also for sedimentation and it is not an absolute 1 to 1 correlation with molecular weight of the subunits.
|
|
|
size of proks ribs?
|
So for the proks, the overal size of the prok rib is 70 s but it is divided into the 50s large and 30s small so you can't just add up the small pieces to get the big pieces.
|
|
|
size of euk rib?
|
The euk rib is somewhat larger both in the size of the rib rna and also in the number of proteins involved
|
|
|
many of these ribosome proteins are involved in
|
are involved in how the mrna docks and interacts , how the protein product is moved thru the machinery so S is for svedberg and this is hwo many of the small components in cells are defined for sizevvv
|
|
|
S is for
|
Svedberg, which describes sedimentation rate
A substance with a sedimentation coefficient of 26 S (26x10^13s) will travel at 26 microns per second (26x10^-6 m/s) under the influence of an acceleration of a million gravities (10^7m/s^2) |
|
|
TRNA etc?
|
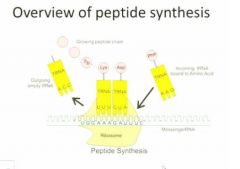
An overview of what we're going to be talking about here. We have the large subunit on top and the small subunit on the bottom and here they're shown as a single piece. You see that the mRNA is docking on the small subunit of the ribosome and hwat'll happen is that transfer rna (special kind we haven't talked about yet) will act as a decoding machinery that can recognize the mrna thru base pairing at one end and they have a covalent bond to a particular amino acid at the other end so for each codon you'll have a separate transfer rna andso you have a particular transfer rna for each type of codon and these are covalently linked then to a particular amino acid. These are highly conserved
|
|
|
cartoon of a more realistic veiew of a transfer rna?
|
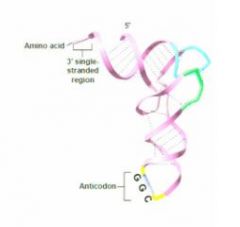
|
|
|
inter strand base pairing of tRNA?
|
They have homologous sequences that allow for internal inter strand base pairing that allows them to fold up into this particular shape
|
|
|
Each a mino acid has it's own
|
transfer rna
|
|
|
Why is the structure of the rnas highly conserved?
|
because they have to fit properly into the large subunit ribosomal binding sites
|
|
|
Messenger rna binds to
|
the small subunit before the large subunit docks
|
|
|
start codon?
|
is always the same for every protein product and it's always going to encode thiamine.
|
|
|
upstream region of rna
|
important for stability of this docking
|
|
|
P site
|
site where the peptide bond will be formed
|
|
|
a site
|
where the next amino acid bound to its transfer rna is going to dock to the next codon on the mRNA.
|
|
|
e site
|
the exit site where the empty transfer rna that's given up its amino acid to the peptide chain is going to leave the large subunit.
|
|
|
moving from one amino acid to the next?
|
What we're going to have then here is what we saw before so you've got the initator transfer rna. Now we have the addition , the entry o ft the second trasnfer rna carrying the next amino acid residue for the polypeptide and what' shappening heree is that there's catalysis that is going to form the peptide bond between the existing, or in this case the first amino acid with the next, subsequent amino acid, so having had initiation then we have a series of stepwise additions of single amino acid residues, one by one for each anticodon along the messagevvv
|
|
|
moving up to termination of rna?
|
So we've had initation, we now have elongation and proteins can be from short ones a couple hundred amino acids, up to thousands of amino acids, so the elongation stage can be extremely extended and then eventually, the message will hit the stop codon (will talk about in a bit) and at this point I t will trigger dissociation, release of the polypeptide, release of the message, and this is the process of terminationvv
|
|
|
n is the
|
amino terminal
|
|
|
c is the
|
carboxy terminal
|
|
|
there are ____________ amino acids
|
20
|
|
|
Who figured out that a codon is 3 base pairs?
|
Nirenberg
|
|
|
many amino acids are encoded by more
|
than one triplet
|
|
|
all protein products when they are initially synthesized begin with
|
thianine
|
|
|
What happens at the first base pair in the triplet
|
is going to be the most important part of the decoding
|
|
|
for most amino acids, the first two places in the codon
|
are the most important for determining the aino acid that's going to be encoded
|
|
|
the third amino acid
|
is often not so important and what this is called is the wobble hypothesis
|
|
|
thianine is also called
|
AUG
|
|
|
what are the 3 stop codons?
|
uag, uga, and uaa
|
|
|
upstream includes the
|
the promoters and regulatory regions
|
|
similar colours have
|
similar chemistry
this wheel is called sunflower versions |
|
|
if you have second base pair mutations
|
you may have a change in the actual amino acid but not in the chemical specificity
|
|
|
even if you have mutations in the message
|
you can still encode a potentially useful protein product
|
|
|
The polarity of the message 5' to 3' is directly
|
mirrored in the polarity of the amino acid chain that it encodes.
|
|
|
what determines the structure and folding of the proteins?
|
the side chains
|
|
|
polarity of side chains?
|
some are polar, some aren't. some are charged both positive and negative
|
|
|
cysteine?
|
there is the amino acid cystein which has the capacity to form covalent bond between cysteine which can provide a region of high stability and cross linking. (polypeptides)
|
|
|
two main important side chain interactions of polypeptides?
|
alpha helices which are involved in certain kinds of functions. These are going to be important particularly for membrane spanning and transmembrane proteins.
|
|
|
polypeptide hydrophobic interactions
|
There are also a large number of hydrophobic interactions. These hydrophobic interactions are based on Vander Valls forces so these are associated with regions of primary protein structure wher all or most of the side chains are hydrophobic so these tend to repel water and they tend to be in the middle of the finely folded protein.
|
|
|
disulphide bridges and ionic bonds in polypeptides
|
There are disulphide bridges which are important for stability of certain cross links and occasionally there are ionic bonds between positively and negatively charged side chains which are important for other kinds of folding.
|
|
|
tend to find in polypeptides?
|
In a fully folded protein then what we tend to find is hydrophobic intereactions on the inside of the protein that exclude water and allow for stability and on the surface we tend ot find charged regions that are important for protein ineteractions between diff members of a complex.
|
|
|
Proper protein folding is essential for
|
proper protein function
|
|
|
Evidence of protein folding stuff?
|
We have two kinds of evidence for this: we have misfolded proteins due to mutations and we also have misfolded proteins due to prions diseases. Prions are normal proteins but they have for various reasons misfolded into a stable conformation that is nonfunctional; they have the capacity when they associate with a ordinary protein of the same type to cause the misfolding of that protein so it is a protein folding problem that leads to product wasting disease, tha tleads to alzheimers disease, that leads to a whole series of very difficult to treat problems and here it si not the primary amino acid chain it is not a defect in folding but in the fact that a misfolded protein can change the tertiary structure
|
|
|
Polypeptide chains fold based on the properties of the
|
amino acid R-groups
|
|
|
each amino acid is linked by
|
a peptide bond that was formed in the large subunit of the ribosome
|
|
|
possible secondary structures?
|
secondary structure which is a helix or a secondary structure which is called a beta pleated sheet and these tend to go back and forth, they have a different kind of stability.
|
|
|
protein pla ces where there is no defined secondary structure?
|
regions which are called coils
|
|
|
alpha helices and the beta sheets are typically involved in
|
stabilizing the structure of the protein whereas the loops typically are more involved in dynamic interactions with other proteins
|
|
|
Not all proteins are individual for their function and
|
sometimes you have multiple peptides working together to produce a functional subunit
|
|
|
different protein structures?
|
|
|
|
So the quaternary protein structures are
|
the multi moll machiens which are required for higher order function.
|
|
|
Actin is the most
|
abundant protein in our cells.
|
|
|
Actin is involved in
|
the contraction of muscles. It's involved in many features of motility and euk cells and related proteins in prok cells.
|
|
|
What are the two ends of actin?
|
The pointed end and the barbed end.
|
|
|
the pointed end of actin has
|
the binding site for functional molls which include atp and calcium and large numbers of these subunits and large numbers are going to be able to asociate with each other in order to form the quaternary structure filaments
|
|
|
What areas can you see in this diagram of actin
|
regions of secondary alpha helices, you have regions of secondary beta sheets. you've got the loops which will be important for interactions between the subunits, you've got binding pockets for co-factors and all of these together are going to form a structural moll
|
|
|
What are the two important kinds of quaternery structure?
|
There are structures like this for actin and microtubules, where you have a repeating polymer of the same kind of subunit over and over and then proteins which interact with these sides of these filaments provide extra functionality and extra specificity for targeting these proteins.
We also have enzymatic quaternary structure, and an example is hemoglobin which has four subunits, in this case they have to work together cooperatively to find oxygen and to release it as necessary. |
|
|
If you have a change in the third base pair, it's called a
|
silent mutation
some large proportion of random mutation will have no effect at all |
|
|
semi conservative protein mutation?
|
when you go back to the wheel and look at the semi redundancy of the code you can see that it's possible to have changes from one amino acid to another amino acid which are semi conservative so instead of having in this sense a mutation that changes from one chemical amino acid to another , you can have relatively small change so that you have some conservation of function even though you've had a change in the conservation of structure
|
|
|
kinds of messense mutations
|
premature terminations leading to truncated proteins
frame shift mutations: insertions or deletions into the message |
|
|
When we study the underlying features in physiology, in agriculture, in engineering, it almost always comes down to
|
identifying and manipulating genetic seqs
this can span everything from chem engineering to health sciences |
|
|
Potential problems with GMO are related to
|
downstream or peripheral issues with selective pressure to maintain the preponderance of the gmo and the other problem is in outcrossing between a gmo food crop like canola and wild meaty relatives that can potentially then acquire the same kinds of resistance.
|
|
|
applications for molecular biology
basic science? |
- genetics, biochem, taxonomy, medicine agriculture
|
|
|
applications for molecular biology
biotechnology? |
- cloning, GMOs, artificial protein production
- xenotransplantation, crop improvement |
|
|
what can cause gene mutations?
|
natural things like UV light, certain chemicals that are dna damaging and it can also be caused by certain viruses
|
|
|
dna mutations causing damage?
|
random mistakes in dna replication typically cause damage to the org in experimental situations we can use that kind of damage to an indiv gene to understand the function of that gene. So it's like taking indiv pieces of a car out to see what each piece does. So random mistakes in dna replication then are a powerful experimental tool that has allowed investigators to study aspects of gene function.
|
|
|
Beadle and Tatum?
|
Beadle and Tatum in 1950s used this kind of information to dissect the argenine biosynthesis pathway of ?a tractable model system ???To understand that there are multiple steps in argenine biosynthesis . So they created a suite of mutants that were unable to grow without the addition of argenine, hypothesized that these mutations were involved in the pathway, discovered that there were various kinds of the mutations and formulated in the end the hypothesis that said that a gene seq was responsible for encodinga polypeptide.
|
|
|
problems as a result of biochemical knowledge?
|
One of the downstream problems is because we've developed these techniquesk, we've eneded up in the unfortunate situation where we're using chems for our daily lives like for the production of food and animals we use an awful lot of antibiotics and have led to problems such as the development of microorganisms that are resistant to almost every kind of antibiotic we can give them...
A particular problem right now in hospitals is what we call m????? And so here we have an org that is resistant to a drug that used to be a powerful drug and it's no longer therapeutically useful, so the questin o is how likely is this to have happened. penicillin story |
|
|
penicillin story?
|
A particular problem right now in hospitals is what we call m????? And so here we have an org that is resistant to a drug that used to be a powerful drug and it's no longer therapeutically useful, so the questin o is how likely is this to have happened. Back in the 1940s when pennicilin which is chemically related to methicillin , there was a great biosynthetic effort to create peniccilinn which had been understood for decades to be an important anti-bacterial drug, but they didn't have very much. In fact all the peniccillin on the planet wasa a single gram. They had a human patient who had scratched his hand and had developed a bacterial infection in his blood called septosemia and at the point where the first peniccillin therapy was attempted, this patient was comatose near death, they gave him a dose of penicillin and over night he recoverred, came out of coma and was hungry. But they didn't have very much, only used a portion, they used the remainder of it over 3 days and in the very short time for a naïve bacteria, the bacteria developed a resistance and he died in a week and a half. So one of the important things to think about is that if you use a selective agent like a drug, if you use a therapeutic agent, you inevitably develop a resistance to that agent because bacteria and microorganisms grow very quickly and the faster they grow the more chances they have to have mutations during dna replication and the more chances they have for selection of resistant mutants.
We've used compounds like penicillin, methiciling, ampicillin, all the time now for lots of reasons, many of our pathogens have developed a resistance against them. |
|
|
in ecoli you get about _____ generations in a day
|
72 generations in a day
This is about as many generations as humans have had for a couple thousands of years |
|
|
Granny smith apples?
|
Granny smith had an apple farm in South Africa and one branch had unusual apples and all the granny smith apples we have today are direct descendents of a single branch of a single tree. The point here is that cloning per say may or may not involve genetic methods and it may or may not be GMO
|
|
|
genetic cloning uses molecular
|
techniques and tools
|
|
|
Enzymes manipulate dna
|
directly
|
|
|
most important enzymes
|
are restriction endonucleases which recognize the specific base pair seq in the dna and cleave it in a site specific manner and these have allowed researchers to specifically target and cut dna at defined place so it's possible to separate and re ligate (combine) it in defined ways So the RE cut in specific places. Ligases join seqs back together and polymerases are important for replicating dna and are also important for sequencing.
|
|
|
Gel electrophoresis separates
|
dna or rna or proteins depending on the kind of gels and the kinds of methodologies. It separates them by size based on a common charged and the fact that these are being forced electrically to migrate.
|
|
|
Cloning vectors?
|
Plasmids, extra ???nucleosome?? Dna which can be used as artificial chromosomes to host a seq of interest for replication
Dna seq is used to confirm that the manipulation of choice have occurred as expectedvvv |
|
|
enzymes
|
polymerases, ligases, restriction endonucleases
|
|
|
cloning vectors
|
plasmids to artificial chromosomes
|
|
|
enzymes like REs naturally
|
occur in bacteria and appear to have evolved as a protection method against viral dna
|
|
|
So like everything bacteria have
|
viruses. The viruses can attack the bacterium and if the bacterium can produce an enzyme that cuts the viral dna then the dna can be disabled.
|
|
|
The first RE to be discovered was called
|
Ecor1 and it recognized gaattc, we always talk about this in the 3' to 5' direction and one of the interesting things about REs is that they are palindromic and what that means is that you can read them in the forward direction or in the complementary strand they are identical forward and reverse.
|
|
|
All of the RE names relate to
|
the orgs from which they were originally isolated. So ecor1 comes from ?????? Ecoli which is a common gut bacterium.
|
|
|
Diff Res and there are hundreds now all recognize palindromic seqs but they recognize
|
specific seqs
|
|
|
Hundreds of different REs have been isolated from
|
various bacteria, recognizing specific base sequences
|
|
|
how do REs bind to the DNA?
|

The way they do this is that they're dimers, they bind around the dna so here we are looking down the dna double helix. So you hve two enzymes of two monomers of hidiIII which are forming a dimer so here we have a case of quaternary association used for function. They are binding to andable to recognize the internal seq of the base pairs and cut in a precise wayvvv
|
|
|
If you take sticky ends, mix them together and control the temp properly, you can allow
|
reannealing
This is not going to be very stable because the number of hydrogen bonds here is very low but if you can manage to do that then you can add a dna ligase to reform that phosphodiester bond and regenerate a double stranded dna so what's happneing here is you must have a 3' oh at the end of the guanine and a 5' phsophate at the adenine and what's going to happen then is with the ligase with energy from ATP si your'e going to be able to reform that phosphdiester back bone. |
|
|
can you join hindIII sticky ends with ecor1 sticky ends?
|
no
|
|
|
lack z experiment?
|
So sofar this seems to be okay except that now we've got diff sites and how are we going to put things together that have unlike sites? At the end of the early 1990s, researchers at the U of California took a plasmid and engineered it very carefully so that the plasmid which is shown here as the circle had a resistant marker for ampicillin so a bacterium tha thad that plasmid would be able to grow on ampicillin. It had an orgiin of replication so that it could replicate itself. |But most importantly it had two features here. One was called the lack promoter and the lack z enzyme that would allow it to form a blue compound when it was grown on a particular substrate but in addition it had what was called a multiple cloning site or a poly cloning site that had a closely nested seq of RE cut sites and that was interesting but what was particularly interesting was that they ahd also gone thru all of the rest of the plasmid which was about two and a half thousand base pairs and made sure that none of these particular sites was available anywhere else in that plasmid. So instea d of cutting with a particular RE and having it cut here and here and here, it was just one single cut. So this was a very powerful tool because you could cut and be assured that you could get exactly what you were expectingvv
So RE have specific cut sites and the specific cut sites are incompatible between diff RE but you can imagine that if you had a fragment of dna that had an ecor1 stie and a hindiii site and you cut your plasmid with ecor1 and hindii , you would then be able to ligate a fragment into a vector, now when you do that what you're going to be doing is taking your gene of interest that you're going to study, you're going to cut it with the two enzymes, then you're going to mix the fragment in with the plasmid, allow base pairing to occur and then use the ligase to fit the whole thing back together and then you have the question of how it is that you're going to figure out, because all these htings are small and in solution and you can't tell them apart, you need to figureo ut how you tell whether you've done what you'd expect. Here the advantage is in that ?????? Lack z?? Bio synthesis gene that will turn the entire colony blue if you grow it in a particular substrate. Vvv There are two kinds of ecoli that won't grow. There's the regular ecoli, and there's the ecoli with the untransformed plasmid. The ones that don't pick up the color will be white. |
|
|
ethical questions related to plasmid modification etc?
|
- foreign dna and selection markers
- would you like to know if you have inherited the potential to have a disease in your 40s or 50s |
|
|
bioenergetics
|
how you acquire energy, how you get ATP energy from the food that you've consumed and how you use it for growth and development.
|
|
|
metabolism is
|
energy capture and it's energy use
|
|
|
thermodynamics is
|
the study of energy
|
|
|
high energy bonds are transduced into useable formats
|
NADP and ATP which are going to drive metabolism
|
|
|
What forms of energy are there?
|
Gravity, nuclear which holds nuclei together, light is important for photosynthesis, electrical/chemical is important for metabolism, mechanical is the ability to move things, heat is a source of energy at high rates and is a waste product which is always generated as a part of interaction.
|
|
|
first law
|
total amount of energy in a closed system is constant
|
|
|
the major forms of energy are present
|
in all sorts of compounds
|
|
forms of energy?
second law? |
gravitational, nuclear, light, electrical, chemical, mechanical, heat
some usable energy is lost when transferring from one type to another |
|
|
entropy?
|
The amount of unusable energy that is lost between the energy in the reactant molls and the product molls is called the disorder in the system and it's also called the entropy
|