![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
24 Cards in this Set
- Front
- Back
- 3rd side (hint)
|
Für das Suchen des kleinsten / größten Elements in einer unsortierten Liste muss einmal... |
über die gesamte Liste iteriert |
|
|
|
Um das zweitkleinste / zweitgrößte Elemente zu finden, muss... |
das kleinste / größte ausgeschlossen und in der restlichen Liste weiter gesucht werden. Hierfür sind insgesamt n+n-1 Iterationen erforderlich. |
|
|
|
Welcher Komplexität ist die Berechnung des Medians in einer unsortierten Liste? |
O(n2) |
|
|
|
Sortiert man zunächst die Liste mit Hilfe des Algorithmus |
O(n*log(n)) |
|
|
|
Zählen Sie die Suchverfahren auf |
- Sequenzielle Suche |
|
|
|
Was passiert bei Fibonacci-Suche? |
Bei der Fibonacci-Folge werden iterativ jeweils die beiden |
|
|
|
welche ist die Voraussetztung für die exponentiellen Suche und wie funktioniert diese? |
Ist die Suchliste sehr lang und kennt man nicht die genaue Größe, so wird der Suchbereich mit exponentiell wachsenden Schritten erweitert, bis man den Bereich festgelegt hat, in dem der gesuchte Wert liegt. -Man prüft in der ersten Iteration, ob der gesuchte Wert im Bereich der ersten i Positionen liegt. Ist der Suchwert größer - Damit wachsen die Interwalle exponentiell an, was dazu führt, dass der Suchbereich vergleichsweise schnell gefunden wird. |
|
|
|
Wie funktionert die Interpolationssuche? |
- Ist die Größe der Elemente innerhalb einer Liste ähnlich |
|
|
|
Was passiert beim Hashverfahren? |
- Bei den bisher betrachteten Listen erfolgte die Speicherung der innerhalb einer Elemente Liste jeweils an einer bestimmten Position. |
|
|
|
Nennen Sie bitte die wesentliche Operationen beim Hashverfahren |
Suchen , Einfügen und Entfernen |
|
|
|
Bei den Operationtn Suchen, Einfügen und Entfernen wird davon ausgegangen... |
- Es wird meist davon usgegangen, dass anfangs die Elemente eingefügt und anschließend weitgehend nur nach Elementen |
Beispiel - Gegeben sei eine Hashtabelle mit 37 Elementen (mit den |
|
|
Beschreiben Sie die Hashfunktion |
Grundsätzlich ist es möglich, dass für unterschiedliche |
|
|
|
Welches Hashverfahren wird als "halb dynamisch" bezeichnet? |
Ist die Größe der Hashtabelle (=m) fix, so können nicht mehr |
|
|
|
Bei den dynamischen Verfahren kann die Größe der Hashtabelle... |
in Sprüngen verändert werden. |
|
|
|
Was ist ein Belegungsfaktor? |
Der Quotient aus Anzahl der belegten Positionen (=n) und |
|
|
|
Wie läuft Bearbeitung von |
- Wird in einer Hashtabelle an der Position i das Element k |
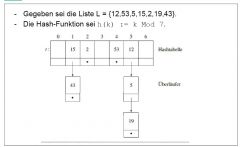
|
|
|
Was passiert bei offenen Hashverfahren? |
- Bei offenen Hashverfahren werden Überläufer innerhalb der |
|
|
|
Offenes Hashverfahren: Nennen Sie die Operationen |
-Sondierungsfunktion -Einfügen eines Elements/Schlüssels k - Suchen nach Element/Schlüssel k - Entfernen eines Elements/Schlüssels k |
|
|
|
Beschreiben Sie die Sondierungsfunktion |
Sondierungsfunktion: |
|
|
|
Beschreiben Sie das Einfügen eines Elements/Schlüssels k |
Es gilt, dass k nicht schon in der Hashtabelle t vorkommt. |
|
|
|
Beschreiben Sie das Suchen nach Element/Schlüssel k |
Beginne mit Hashadresse i = h(k). |
|
|
|
Beschreiben Sie das Entfernen eines Elements/Schlüssels k |
Suche nach k. |
|
|
|
Wie sieht die Funktion Lineares Sondieren aus? |
- Sondierungsfunktion: s(j,k) = j |
- Größe der Hashtabelle m = 7 |
|
|
Beschreiben Sie Quadratisches Sondieren |
- Beim quadratischen Sondieren wird verhindert, dass |
|