Reading...
![]()
Play button
![]()
Play button
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
243 Cards in this Set
- Front
- Back
|
what is multicollinearity?
|
refers to the extent of linear relationships among the independent variables
|
|
|
what is extreme multicollinearity?
|
when at least one independent variable is a PERFECT linear function of one or more of the other independent variables (e.g. x1 = 3 + 4x3)
|
|
|
what are the problems associated w/ extreme multicollinearity?
|
-no unique solution to the least squares criterion (there are an infinite number of different solutions that minimize the sum of squared residuals)
|
|
|
when will multicollinearity necessarily occur?
|
-necessarily occurs when sample size is less than or equal to the number of variables in the sample plus 1 (i.e. more variables than the number of observations)
-if you include the full set of dummies for a nominal variable -if you include a person's age, year of birth, and the current year |
|
|
what will Stata do to deal w/ extreme multicollinearity?
|
It will give you an error message and Stata will arbitrarily pick one of the variables and exclude it
|
|
|
what is near extreme multicollinearity?
|
"strong" linear relationships among the independent variables
|
|
|
what is affected by multicollinearity?
|
-standard error estimates...standard error estimates will be too large (true standard errors are smaller)
-note: only the standard error estimates of the variables that are collinear are affected! standard error estimates of variables that are not collinear are unaffected -the result of this is the p-values will be bigger, leading to it being harder to reach statistical significance (making it harder to reject the null hypothesis that a coefficient is 0)...this is NOT an 'error,' but yields misleading results |
|
|
what is NOT affected by multicollinearity?
|
-coefficients (still unbiased and efficient; coefficient estimates will not be affected)
-in other words, coefficients are still BLUE (best linear unbiased estimators) |
|
|
how do we check for multicollinearity?
|
-check the R-squared for regressing each independent variable on all of the other independent variables
-if R-squared = 1 for any of the independent variables, you have extreme multicollinearity -if R-squared is "high" (close to 1) for any of the independent variables, you have near extreme multicollinearity |
|
|
when does Paul Allison start to worry about near extreme multicollinearity? (at what R-squared level)?
|
when R-squared for regression of an independent variable on all of the other independent variables is greater than 0.6
|
|
|
since it would be time consuming to run all of the necessary regressions to check for multicollinearity, what else can you do to check for it?
|
-produce one of the following statistics:
Tolerance = 1-R-squared of regression of an independent variable on all other independent variables Variance Inflation Factor = 1/(1-R-squared of regression of an independent variable on all other independent variables) |
|
|
what does VIF mean?
|
-"variance inflation factor"
-tells you how much the variance of that particular independent variable is inflated because of linear dependence on other independent variables in the model -thus, a VIF of 1.8 means that the variance (squared standard errors) of that variable are 80% larger than they would be if the variable was completely uncorrelated with other independent variables in the model -VIF has a lower-bound of 1 but no upper bound -VIF of 2.5 corresponds w/ R-squared of 0.6 w/ other independent variable(s) |
|
|
what command in stata can you use to test for multicollinearity?
|
-first fit a model (i.e. run a regression)
-then type "estat vif" -this will give you the variance inflation factor for each independent variable regressed on the other independent variables |
|
|
how should you interpret the output from estat vif?
|
-if VIF is higher than 2.5 for a variable, this is evidence of multicollinearity (either extreme or near extreme)
-if 2 variables have high VIF, means they are highly correlated -if 3 variables have high VIF, means tall 3 are highly correlated -if 4 or more variables have high VIF, not really possible to know which ones are highly correlated with which other ones |
|
|
can you check for multicollinearity by looking at bivariate correlations?
|
having lower bivariate correlations doesn't necessarily rule out collinearity...so best to use estat vif command
-that being said, if find high VIF for 4 or more variables, can look at bivariate correlations to try to figure out which variables are strongly correlated |
|
|
will standard errors be larger, smaller, or the same if multicollinearity is worse? why?
|
-the worse the multicollinearity, the bigger the standard errors will be
-b/c standard errors are calculated using R-squared of the independent variable regressed on all other independent variables...as R-squared goes up, the standard error goes up |
|
|
why does including two measures of the same thing in a regression model lead to extreme or near extreme multicollinearity? give an example
|
b/c this essentially is trying to measure the effect of one by controlling for the other, which is a hopeless attempt to parcel out their individual effects
-example: y = # of children after 8 years of marriage; x2 = desired number of children at time of marriage; x3 = desired number of children 1 year later |
|
|
what will happen to the t-statistics for independent variable(s) that was highly correlated with another independent variable if that second independent variable is dropped from the model?
|
the t-statistic on the independent variable(s) still in the model will go up, producing lower p-values and making it easier to achieve statistical significance (than if second variable had not been dropped)
|
|
|
what is the other problem with multicollinearity, aside from increasing standard errors?
|
it makes regression less robust to violations of assumptions, such as
-measurement error in independent variables -nonlinearity -omitted variables -outliers in the data BUT, these problems ONLY affect the variables involved in the multicollinearity |
|
|
what is the "tipping effect" of multicollinearity?
|
if 2 independent variables, x1 and x2, are highly correlated, and x1 is slightly more correlated with y than x2, the estimated coefficients might overemphasize the effect of x1 on y and underemphasize the effect of x2 on y.
-in other words, a small difference at the bivariate correlation level translates into a big difference when controlling for the other variable |
|
|
what can you do about multicollinearity?
|
-only so much you can do b/c problem is a fundamental lack of info
-exclude one or more variables (problem: may be interested in effects of both variables) -make joint tests of hypotheses (will give legit and useful test but won't tell effect of 1 variable controlling for others) -combine the collinear variables into an index (most appropriate if variables are measuring the same thing) -construct latent variable model (assumes some latent variable is affecting both the dependent variable and the collinear variables) -get more data (can compensate for higher VIF by increasing sample size...but not always possible and if problem of misspecification, won't solve problem necessarily) -ridge regression (not recommended) (rarely useful...have to make assumptions that are at least as problematic as those made for OLS) |
|
|
how important is it to have a high R-squared?
|
-important if goal is forecasting (but if forecasting for business, low R-squareds are still useful b/c even a slight increase in consumption of the product is good)
-not so important if goal is to estimate and test causal effects (even when R-squared is low, can still get significant coefficient for variables; sometimes if n is very high, R-squared will appear low [b/c of formula for R-squared having n in bottom) |
|
|
Why does Paul feel there is too much emphasis on getting a high R-squared?
|
-it's more important to know whether your estimates are biased. R-squared tells you NOTHING about that
-a low R-squared is quite consistent with perfectly satisfying the assumptions of the linear model and, therefore, getting unbiased estimates -one can get a high R-squared with a model that is grossly misspecified and produces biased estimates -however, low R-squared does imply less precise estimates and, hence, smaller t-statistics...BUT you can compensate w/ larger sample size -a low R-squared also suggests that there are other variables out there that ought to be considered (but it's not guaranteed b/c world may not be perfectly deterministic) |
|
|
what does it mean for coefficients to be unbiased?
|
nothing systematically causing them to differ from the true population coefficient. This means that estimates will average out across multiple samples at the true value
|
|
|
what does it mean for coefficients to be precise?
|
means the confidence intervals/standard errors are small, allowing you to get an estimate of the coefficient that is a small range of numbers (as opposed to a large range of numbers). To have precise coefficients, the ESTIMATED standard error should be small.
|
|
|
what does it mean for coefficients to be efficient?
|
this means the coefficient is stable from sample to sample. to be more stable, the TRUE standard error associated with the coefficient should be small. In other words, there is minimal sampling variability
|
|
|
What types of data often yield high R-squared?
|
-time series data (measure of a single case at several points in time)
-aggregate data, such as data that includes averages (random variation cancels out) (b/c using multiple measures) -but both kinds of data also tend to have high multicollinearity among the predictors |
|
|
what types of data often yield low R-squared?
|
-dummy dependent variables, especially if there is an extreme split (e.g. dichotomous nominal variable). this is because there is less variability in the outcome
|
|
|
if R-squared is low, what does this tell us about standard errors?
|
-standard errors tend to be high when R-squared is low (because not able to precisely estimate coefficient(s))
-but getting larger sample can make this better |
|
|
what happens to R-squared when you add another independent variable to a regression model?
|
R-squared NEVER decreases. Will either go up or stay the same
-R-squared may go up even if the new variable(s) have no effect on y -this makes it hard to compare the predictive power of models w/ different numbers of variables |
|
|
what solution is there to allow for a comparison of predictive power of models w/ different numbers of variables?
|
adjusted R-squared
-this adjusts the R-squared for the number of variables in the model (i.e. it penalizes models that have more variables in them) |
|
|
when does adjusted R-squared make little difference? (in comparison to regular R-squared)
|
when the sample is large (i.e. it's the number of variables relative to sample size that will determine how big an adjustment)
|
|
|
is there a range for adjusted R-squared? What happens to adjusted R-squared when you add another variable to a model?
|
-adjusted R-squared can be negative (this would indicate a bad model...this would happen when the original R-squared was very low)
-it can go up, down, or stay the same if a variable is added to the model |
|
|
what happens to the standard errors of the coefficients when a new independent variable is added to a regression model?
|
We don't know...they could increase, they could decrease, they could stay the same...it depends
|
|
|
what are the 2 types of "non-response"?
|
-item non-response (a person doesn't answer one or more questions, e.g. they skip those questions in the survey)
-unit non-response (when a person doesn't respond at all...e.g. they don't complete the survey) |
|
|
what is the definition of "missing data"?
|
-when information on some variables is missing for some cases
-aka item non-response |
|
|
what are the causes of item non-response?
|
-refuse to answer the question
-don't know how to answer the question -can't remember information needed to answer the question -their response cannot be interpreted -question is not applicable |
|
|
what are problems associated with missing data?
|
-at the presence of missing data, there might be a reason to believe that respondents systematically differ from non-respondents, even after controlling for the observed info
-effective sample size will shrink, which may increase the standard errors of estimates |
|
|
will the presence of missing data seriously affect the estimates?
|
-normally the presence of missing data may affect:
the unbiasedness of the estimates -the precision of the estimates (the size of standard errors) |
|
|
which is worse, missingness that depends on the value of an independent variable or missingness that depends on the value of a dependent variable?
|
usually missigness that depends on the value of a dependent variable is worse
|
|
|
to deal w/ missing data, what do you first need to do?
|
-make some assumptions about the mechanism that results in missing data
|
|
|
what is MAR?
|
Missing at Random
-the probability that a particular variable is missing for a particular individual does not depend on the value of that variable, controlling for the effects of the other variables. -this condition is violated if, e.g. ppl with high income are less likely to report their income |
|
|
what is MCAR?
|
Missing Completely At Random
-the probability that a particular variable is missing for a particular individual does not depend on the value of ANY variables in the model of interest. -this condition is violated if, e.g. women are less likely to report their income than men |
|
|
what is NMAR?
|
Not Missing at Random
-the probability that a variable is missing depends on the (unknown) value of that variable, after adjusting for other variables in the model |
|
|
which assumption is stronger, MAR or MCAR?
|
-MCAR
note that MAR also allows for the probability of missing variable depending on value of other variables (the prob. of missing variable just can't depend on value of that same variable) |
|
|
can you test for MAR and MCAR?
|
-you cannot test for MAR
-you can partially test for MCAR (i.e. can test for correlation b/w probability of missing on variable A and value of variable B) |
|
|
what are the methods of handling missing data?
|
1. Listwise deletion
2. Pairwise deletion 3. Dummy variable adjustment 4. Estimation of missing values (imputation) 5. Multiple imputation 6. Maximum Likelihood |
|
|
what is listwise deletion?
|
-aka complete case analysis
-exclude all cases that have any missing data on any of the variables in the model -default method for handing missing data in Stata -yields unbiased estimates if data are MCAR (it's equivalent to taking a random subsample from the original sample) -but then later prof says that it doesn't produce bias as long as probability of missingness on independent variables doesn't depend on value of dependent variable??? -for regression models, yields unbiased estimates so long as the probability of missingness on any of the variables in the model does not depend on the dependent variable -can be used for any statistical method -standard errors are "honest" estimates of the true standard errors -BUT listwise deletion can drastically reduce the number of cases, and therefore waste an enormous amount of data (this would make it more likely to make Type II errors [i.e. concluding that a relationship doesn't exist when it actually does]) |
|
|
give an example of a case where listwise deletion would produce biased estimates. give an example of a case where listwise deletion would produce unbiased estimates
|
y = job satisfaction; x1 = salary; x2 = years on job.
- If missingness on salary depended on job satisfaction, the condition would be violated and listwise deletion would produce biased estimates - if missingness on salary depended on salary, would not violate the condition and listwise deletion would produce unbiased estimates |
|
|
what is pairwise deletion?
|
-aka available case analysis
-estimate each correlation with all the cases that have data on BOTH variables in the pair, then use the correlation matrix (with standard deviations) as data input. -produces consistent (approximately unbiased) estimates of the coefficients when data are MCAR -obviously this can only be used for statistical techniques that can use a correlation matrix as input, like linear regression -no easy way to do pairwise deletion in Stata -advantages: easy to do (w/ some software) uses all available data (and therefore likely to be more efficient than list wise) consistent (approximately unbiased) if the data are MCAR (if data are MAR and not MCAR, can give you biased estimates) -Disadvantages: correlation matrix may not be "positive definite" (a mathematical property required of correlation matrix). If not, then regression estimates can't be computed Can't compute many diagnostics (e.g. residuals, plots) reported standard error estimates incorrect |
|
|
what is dummy variable adjustment?
|
-no longer recommended for general missing data problems, although still widely used. Problem is it yields biased estimates, even when data are MCAR
-useful when data are 'missing' because a question is inappropriate for the respondent (i.e. not applicable) -basic idea is to include in the model a dummy variable, indicating whether or not the data is missing for each variable. When you do this, it doesn't matter what value you impute for the missing data (although imputing the mean for non-missing cases facilitates interpretation) |
|
|
how would you use dummy variable adjustment in the following situation?
y = hours of housework x1 = gender (1 = male, 0 = female) x2 = marital status (1 = married, 0 = single) x3 = measure of marital satisfaction (coded as missing for singles) |
suppose mean of x3 is 3.5 for married people
replace x3=3.5 if x2==0 reg y x1 x2 x3 the coefficient on x3 (marital satisfaction) is the effect of satisfaction among married persons the coefficient on x2 (marital status) is an adjusted difference in the mean of y (housework) for married and single persons (e.g. the difference in hours of housework b/w unmarried people and married people at a mean of 3.5 on measure of marital satisfaction) -note: the coefficient for x3 (marital satisfaction) is invariant to the choice of values to substitute for missing data -note: the coefficient for x2 (marital status) will vary depending on the choice of substitution value (e..g if replace with 0, x2 will compare difference in mean hours housework b/w unmarried people and married ppl w/ value of marital satisfaction equal to 0) |
|
|
what is estimation of missing values (imputation)?
|
-replace the missing data with some estimated value, and then proceed as usual
|
|
|
what are the different types of imputation?
|
-replacement with means: for each variable, calculate the mean for the cases with no missing data, then substitute the mean for the missing data. Not a good method (biased even under MCAR)
-regression estimates: use other independent variables to predict the values of the missing data. Variations depending on which other variables you use and how you use them |
|
|
what are the general problems with imputation-based methods?
|
-statistical properties not well-known, or difficult to calculate
-conventional standard error estimates are too low (b/c software doesn't take into account the inherent uncertainties about the guesses) -this results in t stats being too low, causing you to reject null when shouldn't (Type I error) |
|
|
what is multiple imputation?
|
-this method produces correct standard errors and consistent estimates of the regression coefficients under MAR
-basic idea: use regression models to generate imputed values but, for each regression, add a random draw from the simulated error distribution. Suppose, for ex., that we have missing data on Z and we use X and W as predictors. For the cases that don't have missing data on Z, we estimate the regression of Z on X and W, and we get the equation Zhat = b0 + b1X + b2W...to impute Z for the missing cases, we use Zimp = b0 + b1X + b2W + seE, where E is a random draw from a standard normal distribution and se is the estimated standard deviation of the error distribution (the room mean squared error). We use this method to create several data sets, each with different imputed values b/c the random component varies each time. Next, we estimate our model on each of the data sets. We then average the coefficient estimates and use the variability across estimates to correct the se |
|
|
what are the 2 attractions of using the multiple imputation method for dealing with missing data? which is more important?
|
-by doing multiple imputations and averaging, you can basically reduce sampling variability
-allows you to get standard errors right by directly building in the uncertainty about those missing values (this is MORE important)...standard methods underestimate standard errors b/c don't build in uncertainty about estimates of missing values |
|
|
what is the purpose of random draws in multiple imputation?
|
this reflects the uncertainty in estimating the missing values
|
|
|
what stata command can you use for multiple imputation?
|
mi
|
|
|
when doing multiple imputation, what is an "auxiliary variable"?
|
a variable highly correlated with one or more of the variables with missing data. It is good to include auxiliary variables in the command to produce imputed values b/c auxiliary variables will yield better imputations. It will also produce more accurate standard errors
|
|
|
in the output you get from running a regression after multiple imputation, what statistic is important to note?
|
the statistic "minimum DF" (minimum degrees of freedom). You want this number to be 100+ to get reliable estimates. If min DF is too low, do more imputations (i.e. need to average across more data sets)
|
|
|
how many imputations do you need?
|
-at least 5
-the higher the number of missing data, the more imputations needed |
|
|
When doing multiple imputation, sometimes you make a multivariate Normal assumption. What does that mean?
|
-this implies that all the imputations are based on linear regression
-note that multivariate Normality is actually a stronger assumption than assuming the Normality of each variable -note that the multivariate Normality assumption is possible to check, while MAV assumption that multiple imputation requires is NOT |
|
|
what are the disadvantages of multiple imputation?
|
-you get a different result every time you use it (but this is also the case for simple random sampling...might see different results w/ different samples of same pop)
-potential incompatibility between imputation model and analysis model (if model estimating has interactions or nonlinearities, but imputation model doesn't, can cause problems...so, in general, want to build interactions and nonlinearities into imputation model if in analysis model) |
|
|
what is maximum likelihood?
|
-a statistically optimal method for handling missing data, but requires specialized software
-averages the likelihood function (gives probability of observing your missing data over the parameters??) over the missing data, then chooses estimates to maximize the resulting likelihood -yields estimates that are efficient and approximately unbiased when data are MAR -more elegant and straightforward than multiple imputation -no potential incompatibility between imputation model and analysis model -to implement, need structural equation modelling (SEM) software, like Stata 12-13 |
|
|
do the results from multiple imputation and maximum likelihood usually differ greatly?
|
No, usually they ought to produce roughly the same estimates
|
|
|
What are Paul's recommendations regarding what methods to use regarding missing data?
|
1. Use listwise deletion if the proportion of cases with any missing data is not large (say, not above 10%)
-this is the easiest method to apply, and is relatively unproblematic from both a statistical and practical point of view (as long as missingness on independent varialbe doesn't depend on dependent variable) 2. don't impute missing values, b/c of standard error problems (don't take uncertainty of guesses into acct) unless you do multiple imputation 3. For 'important work,' use maximum likelihood method or multiple imputation -these methods produce optimal estimates w/ correct standard errors. They also make fewer assumptions than other methods 4. If you're collecting the data yourself, do all you can to minimize missing data 5. With rare exceptions, it's not productive to impute missing data on the dependent variable in a regression -if only have missing data on dep. variable, maximum likelihood reduces to list-wise deletion, so just use listwise deletion |
|
|
what makes listwise deletion better than maximum likelihood and multiple imputation (if less than 10% of cases have missing data)?
|
it is robust to NMAR on independent variables in regression analysis
-if have missing data on independent variable and missing is NMAR, for max likelihood and multiple imputation, can lead to bias -but this doesn't lead to bias in listwise deletion, as long as probability of missingness on the independent variable does not depend on value of dependent variable |
|
|
under what condition can you impute missing data on dependent variable?
|
-exception: repeated measurements on dependent variable...ie if have auxiliary variable correlated w/ dep var. at level of at least 0.5 (but this auxiliary variable cannot be an independent variable in the model)
|
|
|
can you add multiple auxiliary variables when doing multiple imputation and/or maximum likelihood?
|
Yes, but need to also include covariance b/w the auxiliary variables within model
|
|
|
what are 6 possible criteria you might consider when deciding what independent variables to include in your final regression model?
|
1. Unbiasedness
2. Parsimony 3. Precision of estimation 4. Avoid capitalizing on chance 5. Include theoretically interesting variables 6. Discover unexpected relationships |
|
|
what is the unbiasedness criterion?
|
Don't want to get incorrect estimates of effects. Thus, need to include any potential control variables. This criterion would favor including lots of control variables
|
|
|
what is the parsimony criterion?
|
Don't want models with lots of variables that have trivial effects.
Benefits of parsimonious models: -easier to understand -more likely to give you more precise estimates of coefficients (b/c don't have a lot of random variation) |
|
|
What is precision of estimation criterion?
|
-adding variables with strong effects reduces the standard errors of the coefficients of the variables already in the model (it may also change the coefficients themselves)
-adding variables with weak effects increases the standard errors of the coefficients of the variables already in the model -has to do with formula for standard errors...if add variables with high R-squared, reduces standard errors...if add variables w/ low R-squared, increases standard errors |
|
|
what is the avoid capitalizing on chance criterion?
|
If you start w/ 100 independent variables, none of which has a true effect on the dependent variable, you would expect to find about 5 that are significant at the 0.05 level due to chance alone
-want to try to guard against this in some way |
|
|
what is the theoretically interesting criterion?
|
want to include theoretically interesting variables regardless of whether they are statistically significant.
-shouldn't necessarily delete variables that aren't statistically significant from the model if theoretically important/interesting -note: if not statistically significant, inclusion or exclusion unlikely to effect model much |
|
|
what is the unexpected relationships criterion?
|
want to be able to discover unexpected relationships
-just because people expect to find certain things doesn't mean they're gonna be there -sort of in conflict w/ criterion of avoiding capitalizing on chance...so have to balance the two |
|
|
what are some problematic (bad) strategies for choosing what independent variables to include in final regression model?
|
1. Put all variables in the model
2. Include all variables with high or significant bivariate correlations with the dependent variable 3. Decide entirely in advance on theoretical grounds |
|
|
what is problematic about the strategy of putting all variables in the model? when is this okay?
|
-if you have a large number of variables, unless you have a large sample, you're likely to find nothing that is statistically significant and you'll certainly have a very unparsimonious model
-not bad if you only have a small number of variables |
|
|
what is problematic with the strategy of including all variables with high or significant bivariate correlations w/ the dependent variable?
|
-involves first calculating the bivariate correlations b/w each indep var and dep var and then including all indep var that have sig correlation
-problems: 1. capitalizes on chance: will pick up on things that are significant by chance alone 2. a particular variable may only show up as statistically significant if some other variable is present in model. If only look at bivariate correlations, will miss these variables 3. Can leave out some theoretically important variables |
|
|
what is problematic with the strategy of deciding entirely in advance on theoretical grounds which variables to include in model?
|
-statisticians love this method b/c conventional justification of significance tests is unproblematic. Once start letting data drive what variables are included, whole justification for p-values becomes problematic
-but, this risks missing unexpected but important relationships (never gonna discover anything unexpected this way) -problem: data do not drive your model in ANY way |
|
|
what does Paul think is a very important tool for deciding which variables to include in the final model?
|
Automated search procedures
|
|
|
what are some problems with automated search procedures?
|
1. Capitalize on chance (if searching through stuff, will definitely find relationships, even if don't actually exist)
2. May leave out theoretically interesting variables 3. Some programs cannot treat sets of dummy variables as a set |
|
|
what are the different types of automated search procedures?
|
1. Forward Inclusion
2. Backward deletion 3. "Stepwise" |
|
|
what is forward inclusion?
|
1. Find the variables with the highest correlation with y. If the p-value is above some specified criterion, stop. Otherwise, include this variable in the model. Note: the variable with the highest correlation w/ y will also have the lowest p-value. If variable that has highest correlation with y is not statistically significant, don't go any further with the model
2. Find the variable that produces the highest t-statistic when added to the model. If the p-value is above some specified criterion, stop. Otherwise include this variable in the model, and repeat this step |
|
|
what are the pros and cons of forward inclusion?
|
-pros: good at finding unexpected effects
-pros: you can specify groups of variables that are only entered as a group by putting parentheses around them on the reg command. This is especially useful if you have a set of dummy variables representing a single nominal variable. They should always be included and excluded together -cons: may leave out pairs of variables that show up as significant only if both variables are in the model (e.g. if X is only significant when Z is in model and vice versa, this model will never pick up either variable) |
|
|
what is backward deletion?
|
-start with all the variables in the model. Then successively delete variables, one at a time, whose p-values fall above a specified level.
-stop when all variables satisfy this criterion |
|
|
what are the pros and cons of backward deletion?
|
-pros: solves problem of sets of variables that only show up as significant when all the variables in the set are included. Also solves problem of a variable entering the model with a p-value below criterion even though adding variables to model results in that variable's p-value going above the criterion
-cons: may be impractical if the number of potential independent variables is large, perhaps larger than the sample size. Can't estimate a model with more predictors than sample size (due to multicollinearity) |
|
|
do backward deletion and forward inclusion produce the same results?
|
Sometimes, but not always (sometimes give different results)
|
|
|
What is "stepwise"?
|
A modification of forward inclusion so that variables already in the model can also be removed if their p-values rise above a specified level
|
|
|
what does Paul recommend as an approach to deciding which variables to put in the final regression model?
|
1. Select a core set of variables that are definitely in the model based on theory or standard practice. The maximum number in the set should depend somewhat on sample size. Even if you have a large sample, you probably wouldn't want more than 15 or 20.
2. Do some kind of search procedure for remaining variables -backward deletion preferred, but may need to use forward inclusion if there are many variables to search among -alternatively, if number is not large, could just put all in the model and delete those that are not significant -should use a fairly conservative level of significance (typically 0.05 is too high! this risks getting variables in the model that are only there due to chance) |
|
|
what should you be careful not to do when selecting the core set of variables that will definitely be in the model?
|
-make sure the core set does NOT include variables that are actually consequences of the dependent variable, rather than causes. This can seriously bias the coefficient estimates for all the other variables
|
|
|
what is a conservative level of significance when doing backward deletion?
|
If your entry criterion is alpha = 0.05, and you are searching through many possible variables, the actual probability of mistakenly including at least one variable is higher than 0.05, possibly much higher. A conservative approach is to use 0.05/m as the criterion, where m = the number of variables being tested. This is the Bonferroni criterion
|
|
|
what is heteroskedasticity?
|
when the variance of the error term is not constant over all individuals in the sample. In other words, error variance is not the same for everybody (ex. maybe error variance is higher for men than for women, or vice versa)
|
|
|
When is heteroskedasticity likely to occur?
|
1. For nonnegative, ratio-level dependent variables, it often happens that the variance goes up with the mean. In other words, the bigger the average, the more variability around that average (e.g. year-to-year fluctuations in income tend to be higher among high income people than among low-income people)
2. If the dependent variable has a ceiling or floor, the variance tends to be restricted as the variable approaches the ceiling or floor, e.g. if variable is proportion, variance will tend to get smaller as get closer to 0 or closer to 1 3. If the unit of analysis are groups (e.g. cities, department, etc) and the dependent variable is a mean for the group, the variance will be decreasing function of group size (if have very large group, tend to have smaller variations...if group very small, more variation) -e.g. units are colleges and dep. var. is mean SAT scores of entering students. We know the variance of SAT scores is sigma squared (the variance of y) divided by n |
|
|
what are the consequences of heteroskedasticity?
|
1. OLS is no longer efficient (other estimation methods may have smaller standard errors)
2. Standard error estimates are inconsistent (asymptotically biased). Thus hypothesis tests and confidence intervals may not be correct -i.e. p-values we get may be too high or too low and CIs too wide or too narrow Altogether, heteroskedasticity affects both coefficient and standard error estimates...it makes coefficients inefficient (but NOT biased) and standard error estimates too large or too small |
|
|
how do you test for heteroskedasticity?
|
1. by graph: plot values of residuals against predicted values of y (residuals on vertical axis, predicted values on horizontal axis)
-if spread is pretty even around horizontal axis, strong evidence against heteroskedasticity. If scatter of residuals increases or decreases along the horizontal asix, evidence for heteroskedasticity -in stata: after fitting the model, use command rvfplot ("residuals versus fitted values") 2. test in stata: regress the squared residuals on either the predicted values or the predictor variables in the model. If there is no heteroskedasticity, there should be no relationship! "estat hettest" -a low p-value is evidence of heteroskedasticity (null hypothesis is homoskedasticity) "estat hettest, fstat" -gives F-statistic "estat hettest, rhs mtest" -gives test for dependence of variance on each predictor separately |
|
|
what is another name for a graph of the residuals against the predicted values of y?
|
rupplot
|
|
|
in an estat hettest, do you want p-values to be low or high?
|
You want them to be high. A low p-value indicates a problem of heteroskedasticity b/c testing null hypothesis that there is homoskedasticity. Low p-value = reject the null hypothesis and conclude there is heteroskedasticity
|
|
|
what is the MOST important problem associated w/ heteroskedasticity?
|
you can't trust the standard errors. As a result, p-values are off and tests of statistical significance are off.
-in other words, can't put confidence in standard errors |
|
|
what is the 2nd problem associated with heteroskedasticy (less important)
|
the coefficients are no longer efficient (but not nearly as much as an issue as problems with standard errors)
|
|
|
what are the different methods for dealing with heteroskedasticity?
|
1. Transformations
2. Robust standard errors 3. Weighted least squares 4. Simultaneous estimation of a mean model and variance model |
|
|
what is the transformation method for dealing with heteroskedasticity?
|
-sometimes transforming the dependent variable will remove heteroskedasticity (e.g. log income may be more homoskedastic than income itself)
-problem: such transformations not only reduce heteroskedasticity, they also fundamentally change the way the independent variables affect the dependent variable. May not be appropriate. -taking log of income very popular not b/c it reduces heteroskedasticity but b/c more closely resembles relationship b/w income and independent variables |
|
|
what is another name for transformation methods?
|
variance stabilizing transformations
|
|
|
what is the robust standard errors method?
|
-a popular and easy method
-stick w/ the OLS coefficient estimates, but use standard errors that have been adjusted for heteroskedasticity -what makes robust standard errors particularly attractive is you don't have to know the form of the heteroskedasticity (can just put option 'robust' on regression command...don't need to know anything else about heteroskedasticity) |
|
|
what are alternative names for robust standard errors?
|
-Huber-White standard errors
-empirical standard errors -"sandwich" estimates |
|
|
under what situation might robust standard errors not be accurate?
|
in small samples (theoretical justification for this method assumes fairly large smaples)
|
|
|
will robust standard errors be higher or lower than original standard errors?
|
generally go up b/c recognizing that there's greater uncertainty...but can also go down!
|
|
|
what part of regression output does robust standard errors affect?
|
-standard errors
-t-statistics -p-values -95% CIs -F statistic but NOT coefficient |
|
|
what is the one flaw with robust standard errors?
|
it does not solve the problem of inefficient coefficients...coefficients are still inefficient
(but solves problem of standard errors not being consistent estimates of the true standard errors) |
|
|
what is the weighted least squares method for dealing with heteroskedasticity?
|
-a special case of generalized least squares
-suppose we know what the variance of the disturbance term is for each individual. The criterion of weighted least squares (WLS) is to choose coefficients to minimize the sum of the (squared residuals divided by the variance of the error term). -thus, observations with large variance get less weight than observations with small variance (if more error variance, then less info contributed by that particular observation) |
|
|
what are the pros and cons of weighted least squares?
|
-pros: satisfies the Gauss-Markov theorem, so coefficient estimates are BLUE (unlike robust standard errors)
-cons: we need to know something about how the variance of the error term depends on other things (i.e. we must model var(e)). We need to either know the variance of the error term for each individual OR have a formula about how the variances are related to things we do know |
|
|
what if the dependent variable is the mean of some variable for all the persons in a unit. How can you use weighted least squares in that case?
|
-when we're estimating a mean for a group, we know the variance of the mean is equal to variance divided by the size of the group
-suppose we know that the variance of the disturbance term is an unknown constant divided by the size of the unit. -this formula would be appropriate if the dependent variable was the mean of some variable for all the persons in the unit -then apply WLS, with the weight being equal to the size of the unit -the estimates will be BLUE |
|
|
what type of weights do you apply to do weighted least squares?
|
aweights are ideal, but might be able to do pweights if linear regression (will give you the same coefficients, and results will essentially still be correct)
-note: aweights are inversely proportional to the variance of an observation -note: pweights are weights that denote the inverse of the probability that the observation is included b/c of the sampling design. |
|
|
what is simultaneous estimation of a mean model and variance model (to deal with heteroskedasticity)?
|
-some software allows you to specify both a mean model and a variance model
E(y|x1...xk) = b0 + b1x1 +...bkxk logVar(y|x1...xk) = a0 + a1x1 +...akxk (note: variances can't be negative...by modelling the log of the variance, we guarantee that whatever is on the left-hand of the equation is a positive number) -these 2 equations can be simultaneously estimated by maximum likelihood -you can do this in Stata with the "intreg" command...this command is designed for dependent variables that are "interval censored," which means that, for each individual, you know that the value is somewhere between two numbers y1 and y2, but you don't know exactly where. However, it can also be used for regular, "uncensored" data by just making y1 = y2 -by modelling variance as a function of the x's, we correct for heteroskedasticity |
|
|
what are the pros and cons of simultaneous estimation method?
|
-pros: same attractions as weighted least squares (i.e. corrects coefficient estimates and standard error estimates)
-pros: easier to model variance than weighted least squares method -cons: estimates won't be exactly unbiased or nonlinear, but will be close to efficient while simultaneously correcting for standard errors (gives correct standard errors) -effectiveness depends on how well you model variance, but a lot more flexibility than weighted least squares |
|
|
what is panel data?
|
-data in which variables are measured at multiple points in time for the same individuals (usually have measures of the dependent variable at different points in time...sometimes, independent variable might also be measured at different points in time)
-some of the variables may vary with time, others may be time invariant |
|
|
in panel data, do we assume that time points are the same for everyone in the sample?
|
yes; if time points are variable, a somewhat different method may be required
|
|
|
what makes certain variables in panel data time invariant?
|
-either only measured once OR
-can't change (e.g. race) |
|
|
what are the two formats for storing panel data?
|
-wide form
-long form |
|
|
what is wide form?
|
-one record per individual
-time-varying and invariant variables are treated as separate variables on that individual (so if 2 time points, 1 record for individual with different variables for each time point) |
|
|
what is long form?
|
-one record for each individual at EACH time point (so if 2 time points, 2 records for the individual)
-ID number is the same for all records for the same individual -variable indicating which time point the record comes from |
|
|
does software usually process panel data in long form or in wide form?
|
- in long form, so usually first task is to convert from wide form to long form
|
|
|
what are the attractions of panel data?
|
1. ability to control for unobservables
2. ability to resolve causal ordering (i.e. does x cause y or does y cause x?) 3. ability to see how the effect of some variable changes over time |
|
|
in statistical analysis, purpose is to explain as much variation as possible. If use panel analysis to explain variation, which kind of variation would you expect to justify use of panel data?
|
within cluster variation. Panel design only helps when within cluster variation is large, thus need to collect data at different points of time
|
|
|
what are problems associated with panel data?
|
1. Attrition and missing data
2. statistical dependence among multiple observations from the same individual |
|
|
what are the problems associated with attrition in panel data?
|
it's hard to consistently follow-up over long periods of time (ppl move, ppl get tired of participating in study, etc.)
|
|
|
what are the problems associated with statistical dependence among multiple observations from the same individual in panel data?
|
-repeated observations on the same individual are likely to be positively correlated. Individuals tend to be persistently high or persistently low.
-but conventional statistical methods assume that observations are independent -consequently, estimated standard errors tend to be too low, leading to test statistics that are too high and p-values that are too low -also, conventional parameter estimates may be statistically inefficient (true standard errors are higher than necessary) -so, overall, standard error estimates will be too low, true standard errors will be too high, and coefficient estimates will be inefficient (though unbiased) |
|
|
what methods can you use to correct for dependence in panel data?
|
1. Robust standard errors
2. Generalized estimating equations (GEE) (very similar in results to random effects models) 3. Random effects (mixed) models 4. Fixed-effects models |
|
|
what is the robust standard error method for correcting dependence in panel data?
|
-already used them for heteroskedasticity
-also good for correlated observations |
|
|
how will robust standard error method affect the standard errors and coefficients in panel data?
|
-most standard errors will go up...as a result, t-stats will be smaller and p-values will be higher than without the correction, leading to lower probability of Type I errors (i.e. not too easy to reach stat sig)
-standard error on variable representing time itself will go down -variables that only vary with time and not across persons: standard errors might go down -however, TRUE standard errors will still be rather large, leading to estimates that aren't very efficient -coefficient estimates unbiased |
|
|
what is the problem with the robust standard error method for correcting dependence in panel data?
|
-coefficients are still not fully efficient
-doesn't solve problem of TRUE standard errors being rather large in panel data |
|
|
what are random effects models for panel data?
|
-to get efficient estimates that correct for dependence, we insert an additional error term into the regression model
-this additional error term represents all the differences between individuals that are STABLE over time (time invariant) and not otherwise accounted for by time invariant variables within the model. It can be said to represent "unobserved heterogeneity" (i.e. other sources of variation between individuals). -In other words, this error term represents unobserved individual characteristics associated with each individual person (noted as "alpha") |
|
|
why do we distinguish between alpha and epsilon in random effects model?
|
b/c within cluster variation and between cluster variation is different
-alpha = between cluster variation -epsilon - within cluster variation |
|
|
what assumptions are made in random effects models for panel data?
|
-must assume that the additional error term, alpha, which represents "unobserved heterogeneity" (or across cluster variation) is:
1. normally distributed with 2. a mean of 0 3. constant variance, and 4. is uncorrelated with the random disturbance term, the time variant variables and the time invariant variables 5. covariance of the two error terms is 0??? note: measurements closer together in time tend to be more highly correlated...but this model doesn't take this into consideration Also makes assumptions about coefficients on variables: 1. assumes they will be the same for every individual in the sample (i.e. edu has same effect on you as it does on me) 2. assumes that they will be the same at all points in time (i.e. college edu has same effect on wage in 1996 as it does in 2013) |
|
|
what is another name for random effects models?
|
random intercepts models
|
|
|
what command in Stata can you use to estimate random effects model?
|
xtreg
|
|
|
how does random effects model affect coefficients and standard errors?
|
-corrects for inefficiency of coefficients
-standard errors are different from both original and robust standard error approach...called "model based standard error" (b/c estimation of these standard errors involves assumptions we made b/c of random effects model, i.e. effect is constant for every person in data set and effect is constant overtime)...these standard errors thus involve important assumptions |
|
|
what if you want to use random effects model but without any assumptions?
|
can use xtreg command + robust option
-this gives you a random effects model but with robust standard errors (i.e. no assumptions are used in estimating standard errors, though they are used to estimate coefficients) |
|
|
what is sigma u? what is sigma e?
|
sigma u = alpha (across/between cluster variation)
sigma e = epsilon (within cluster variation) |
|
|
what does rho tell us?
|
the proportion of variation that comes from between/across cluster variation.
-If Rho is high, this means a significant amount of variation comes from differences between individuals. -The higher the rho, the more correlation between data points collected on the same individual at different points in time. -Rho is a proportion that varies between 0 and 1 -if Rho is .76, means 76% of variation is due to differences between individuals (as opposed to differences on the same individual at different points in time) |
|
|
if rho is 0, what does this tell you about the usefulness of panel data?
|
tells you that panel data is very useful, b/c variation is due exclusively to differences for the same individuals at different points of time (rather than due to between individual differences)
|
|
|
what is the advantage of estimating random intercepts model by maximum likelihood?**
|
-will give you a test of whether or not there is any unobserved heterogeneity (i.e. will report test of rho = 0)
-also get test of whether random effect has non zero variance |
|
|
what is the fixed effects model for panel data? what are the pros? what are the cons?
|
-enables you to control for all variables that are constant over time for each individual, even if these variables aren't measured
-cons: can only estimate the effects of variables that change over time for at least some members of the sample -pros: controls for the effects of all the variables that do NOT change overtime (even though these variables are not in the equation) (we're really using each individual as their own comparison) |
|
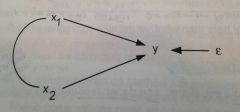
how would you interpret this path diagram?
|
"y is a linear function of x1 and x2, plus an error term"
|
|
|
what do straight arrows mean in path analysis diagrams?
|
direct causal effects
|
|
|
what do curved lines without arrows mean in path analysis diagrams?
|
correlation without any causal assumptions (i.e. "we're gonna let these variables be correlated with each other")
|
|
|
under what circumstances would you put an arrow on a curved line in a path analysis diagram?
|
might do this, but must but arrow on both ends of the curved line b/c correlation doesn't involve any assumptions about directionality
|
|
|
what does a straight arrow point toward a variable mean?
|
that variable is directly caused by another variable
|
|
|
what does a straight arrow pointing away from a variable mean?
|
that variable directly causes another variable
|
|
|
what does it imply if you do not put a curved line between two independent variables in a path analysis diagram?
|
it implies that the partial correlation between those 2 independent variables is equal to 0 (i.e. there is no partial correlation b/w the two variables)
|
|
|
what are endogenous variables?
|
-variables caused by other variables in the system. -These variables have straight arrows leading into/pointing toward them.
-they can be dependent variables or independent variables in the model |
|
|
what are exogenous variables?
|
-variables that are NOT caused by other variables in the system.
-no straight arrows leading into them (though may have straight arrows pointing away from them) -can NEVER be dependent variables |
|
|
what kinds of variables can curved lines link? exogenous, endogenous, or both?
|
-curved lines can only link exogenous variables!
-straight lines must be used to link exogenous and endogenous variables -if you want to indicate a correlation b/w two endogenous variables, need to draw curved lines between their error terms (cannot draw curved lines b/w the variables themselves) |
|
|
are there usually curved lines between the error term and the independent (exogenous) variables?
|
No, because in usual linear regression models we make the assumption that there is no correlation between the error term and any of the independent variables in the model
|
|
|
sometimes path diagrams put shapes around the variable names. If a variable is in an ellipse, what does that mean? If a variable is in a box, what does that mean?
|
-ellipse: latent variable
-box: observed variable |
|
|
how can you calculate the number of equations in a path diagram?
|
by counting the number of endogenous variables...ex: if there are 4 endogenous variables, there are 4 equations
|
|
|
how can you calculate the number of independent variables in a single equation within a path diagram?
|
by counting the number of variables connected to the dependent variable by a straight arrow; I THINK you only count the variables that have a direct effect on the dependent variable...
|
|
|
how do you turn a path diagram into an equation?
|
-start with an endogenous variable
-write the name of the endogenous variable, followed by an equal sign, followed by the intercept, followed by the coefficient and name of the first direct cause of that endogenous variable -add all coefficients and names of the direct causes of the endogenous variable -add the error term at the end -do NOT include variables that are indirect causes of the endogenous variable |
|
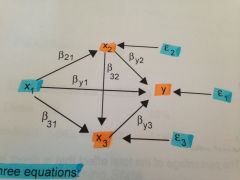
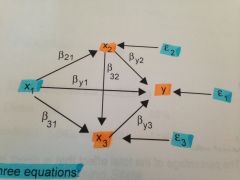
how would you write this path diagram as a series of equations?
|
y = by0 + by1x1 + by2x2 + by3x3 +e1
x2 = b20 +b21x1 + e2 x3 = b30 + 31x1 + b32x2 + e3 |
|
|
how do you calculate the total effect of a variable (x1) on another variable (y)?
|
must look for every possible path for x1 to affect y
-first, calculate how many different paths link x1 to y -multiply the coefficients for the segments on the same path -add the totals of each path -the final number is the total effect do NOT add in error terms! |
|
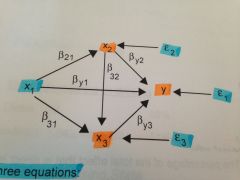
what would be the decomposition of the total effect of x1 on y?
|
(b21 x by2) + by1 + (b31 x by3) + (b21 x b32 x by3)
|
|
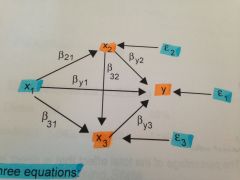
what is the direct effect of x1 on y?
|
by1 = direct effect
|
|
what is the indirect effect of x1 on y?
|
(b21 x by2) + (b31 x by3) + (b21 x b32 x by3) = indirect effect
|
|
|
what is the percentage of the direct effect of x1 on y?
|
direct effect/total effect
by1/([b21 x by2] + [b31 x by3] + [b21 x b32 x by3] + by1) |
|
|
will the percentage be the same or different when you use standardized vs unstandardized coefficients?
|
the same
|
|
|
when can you NOT calculate the percentage of the direct effect or percentage of the indirect effect?
|
when the effects are in multiple directions (can only calculate percentage when the effects are all in the same direction, i.e. all of the coefficients are positive or all of the coefficients are negative)
|
|
|
if you know that the error term on y was .32, how can you calculate the R-squared of the equation for y?
|
first, square the error term = .1024
next, subtract this squared error term from 1 1-0.1024 = 0.8976 so R-squared is 0.8976, meaning we have explained almost 90% of the variability in y by the model |
|
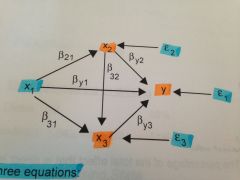
if you did a bivariate regression of x1 on y, what would the coefficient on x1 be equal to?
|
the TOTAL effect of x1 on y (including both direct and indirect effects)
|
|
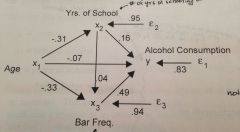
what is the direct effect of age on alcohol consumption? the indirect effects? what is the percent direct effect? percent indirect effect?
|
direct: -.07
direct = -.07 indirect: (-.33 x .49) + (-.31 x .16) + (-.31 x .04 x .49) indirect = -0.1617 + -0.0496 + -0.006076) Indirect = -0.217 Total = -0.287 -0.07/-0.287 = percent direct effect = 24% -0.217/-0.287 = percent indirect effect = 76% |
|
|
what command in Stata can you use to explore indirect effects of independent variables on y?
|
sem
|
|
|
how should you decide causal ordering in a path diagram? (i.e. what variables are the causes of other variables and what variables are the effects of other variables)?
|
1. sometimes temporal ordering provides a good rationale
-e.g. father edu --> child's education --> child's income at age 30 2. sometimes theory or common sense is a good basis -e.g. crime rate in neighborhood --> fear of going out at night -can often make plausible but not definitive arguments |
|
|
what is a recursive system?
|
a system of equations in which the causal ordering only goes in one direction
-if you follow the arrows, you can never return to your starting point |
|
|
what is a nonrecursive system?
|
a system of equations in which the causal ordering goes in more than one direction
-if you follow the arrows, you can return to one or more starting points |
|
|
what is the major, important difference between recursive and nonrecursive systems?
|
-recursive systems can be estimated by applying OLS regression to each equation separately
-nonrecursive systems require special estimation methods. Often they can't be estimated at all. They require special rules for tracing direct and indirect effects |
|
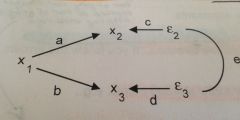
as previously mentioned, can draw curved lines between disturbance terms of endogenous variables to indicate that they are correlated. What does this curved line actually imply? Use the path diagram above to answer
|
that the unobserved causes of the two endogenous variables, x2 and x3, are correlated. "e" represents the partial correlation between x2 and x3, controlling for x1.
-not that we CANNOT also have a direct effect of x2 on x3, or vice versa |
|
|
when may it be useful to indicate a correlation between 2 endogenous variables?
|
when you know that the two variables have a relationship, but you can't specify the causal ordering of this relationship
|
|
|
what does it mean for a model to be under identified?
|
this means that there is too little information to estimate the model.
-most nonrecursive models are underidentified, either in whole or in part |
|
|
what determines whether or not a model is underidentified?
|
1. a nonrecursive model is identified if each endogenous variable in the feedback loop has at least one exogenous variable that affects it but NOT the other endogenous variables (sufficient condition for identification)
2. there must be at least as many reduced form coefficients as structural coefficients for identification (necessary condition for identification) |
|
|
what are the varieties of identification?
|
1. Just identified: the model is identified, and the number of reduced form coefficients is the same as the number of structural coefficients
2. Partially identified: some structural coefficients can be estimated, but not others 3. Over identified: the model is identified, and there are more reduced form coefficients than structural coefficients. This leads to multiple solutions for the structural coefficients -- an embarrassment of riches |
|
|
what is an instrumental variable?
|
an exogenous variable that causes an endogenous variable in a feedback loop but does not cause any other endogenous variables
|
|
|
what are the problems with our general approach to estimating nonrecursive systems?
|
1. must assume equilibrium
2. to get instrumental variables, you must be able to exclude paths on theoretical grounds -you are rarely able to do this in sociology -no amount of data can tell you whether the paths can be excluded -people frequently ignore this problem, but the results are very sensitive |
|
|
what does the usual regression model implicitly assume about measurement error?
|
that all independent variables are measured without error
-random measurement error in the dependent variable is incorporated into the disturbance term |
|
|
what happens if the assumption about independent variables being free of measurement error is violated?
|
coefficients will be biased
|
|
|
what kind of bias will result if there is one independent variable in the regression and it suffers from measurement error?
|
its coefficient will be biased toward zero
|
|
|
what kind of bias will result if there are 2 independent variables in the model, one measured with error and the other perfectly measured?
|
-the coefficient of the variable with error will be biased toward zero
-the coefficient for the other variable will usually be biased away from zero |
|
|
what kind of bias will result if there are more than 2 independent variables in the model and some are measured with error?
|
this is difficult to predict
|
|
|
what can you do about measurement error?
|
there are 2 ways to correct for it
|
|
|
what is the first approach to correcting for measurement error?
|
suppose the variable with measurement error has a known reliability
-the reliability is the squared correlation b/w the measured variable and the true variable -many standardized tests come with estimates of reliability -for multiple-item scales, reliability can be estimated by Cronbach's alpha, which is based on correlations among the items (in stata, command = alpha varlist) if you know reliabilities for one or more variables, these can be used to correct the regression estimates using the **eivreg command (EIV stands for errors-in-variables)** (need to know the eiv reg command) |
|
|
what in the stata output does correcting for reliability usually affect?
|
-coefficients (those on variables you are correcting will go up)
-but NOT p-values (not usually) |
|
|
what will happen to coefficients on variables highly correlated with corrected variable?
|
their coefficients will also be affected (may go up or down)
|
|
|
what is the second method for correcting measurement error?
|
suppose that the true variable X has 2 or more indicators (x1 and x2) each of which is measured with error
-then you can estimate a system of simultaneous equations, where X is not directly observed, but x1 and x2 are directly observed and are each equivalent to X + random measurement error -this is an identified system of equations, and all the paramaters can be estimated with the sem command in Stata -this can be extended to more than 2 indicators, and to more than one variable with measurement error |
|
|
what are the different kinds of weights?
|
1. fweights
2. pweights 3. aweights 4. iweights |
|
|
what are fweights?
|
-aka frequency weights
-indicate the number of duplicated observations -tells the command how many observations each observation really represents -the weighting variable contains positive integers -the result of the command is the same as if you duplicated each observation however many times and then ran the command unweighted -in other words, if you have a bunch of people in your data set with the same value for a variable, can store a single, weighted record -particularly useful if you are trying to work with data coming from a contingency table |
|
|
what are pweights?
|
-aka sampling weights
-denote the inverse of the probability that the observation is included because of the sampling design -often provided in public-use data sets -when dealing with complex sample survey, where certain groups of people have a higher probability of being included than others (on purpose), using pweights undoes the disproportionate sampling --> individuals with higher probability of being drawn will have a lower weight |
|
|
what are aweights?
|
-analytic weights
-inversely proportional to the variance of an observation -for most Stata commands, the recorded scale of aweights is irrelevant (that means you can multiply the weights by any constant and it won't affect the results) -Stata internally rescales aweights to sum to N, the number of observations in your data |
|
|
what are iweights?
|
-aka importance weights
-indicate the "importance" of the observation in a vague sense -no formal statistical definition -any command that supports iweights will define exactly how they are treated -usually, they are intended for use by programmers -don't use them unless you are sure you want to and have a good reason -iweights are rarely used and you ignore them |
|
|
which two types of weights have exactly the same effect for linear regression?
|
pweights and weights
-except that the use of the pweight option automatically requests robust standard errors |
|
|
can you do multiple weights simultaneously?
|
No, you can't do more than one type of weight at the same time
|
|
|
if you are estimating descriptive statistics for some population, what kind of weights should you use?
|
pweights
|
|
|
if you are estimating some kind of regression model under the assumption that everyone has the same beta coefficients, what kind of weights should you use?
|
-Paul generally discourages against the use of pweights in this situation
-but aweights may be appropriate in some of these situations |
|
|
when might you use a bivariate scatter plot that controls for other variables?
|
-to get graphical information about functional form (e.g. linear vs non-linear)
-problem: bivariate scatter plots that do not control for other variables can be highly misleading |
|
|
what is leverage (hat)?
|
-a measure of the "influence" of an observation based on the values of its predictor variables
-in a bivariate regression of y on x, leverage is simply (observed x - mean of x)^2 -in a multiple regression, it's much more complex -to get a leverage value for each observation, after fitting a regression model, issue the command "predict xdist, hat" (xdist can be any name you want for the new variable...observations with high values of xdist are influential) |
|
|
what is leverage vs residual squared plots?
|
-a useful diagnostic is obtained by plotting the leverage values against the squared (normalized) residuals
-the points to be most concerned with are those with high leverage and smaller than average residuals -- this means they probably had a big effect on where the line is (if were to remove the data point, line would probably have a very different slope) -but might also want to look at those data points with both high leverage and high residuals |
|
|
what are the problems associated with using linear regression for a dummy dependent variable?
|
1. Heteroskedasticity: smaller variances as predicted values get close to 1 or 0
2. Non-normal error: by very nature of this type of variable, error term cannot have a Normal distribution 3. Nonlinearity: can get predicted value outside of range of zero or one |
|
|
what is another name for estimating a linear model for a dummy dependent variable? why?
|
-linear probability model
-because if y is a dummy variable, the expected value of y is always equal to the probability of y equaling 1 |
|
|
we said there are three problems with estimating a linear probability model by OLS. What is the most important problem?
|
in many situations, estimation of this model by OLS is not too bad
-lack of normality is rarely a problem if the sample is a decent size -heteroskedasticity is usually not serious, and can easily be fixed by requesting robust standard errors (some suggest weighted least squares, but that usually exaggerates the non-linearity problem) Non-linearity is the most fundamental problem -the left hand side is constrained to lie b/w 0 and 1, but the right hand side has no such constraints -for any values of the coefficients, we can always find some values of x that give values of the dependent variable that are outside of the permissible range |
|
|
what three types of curves are possible for estimating a regression model with a dummy dependent variable?
|
1. Logit - logistic curve
2. Probit - cumulative normal distribution 3. Complementary log-log (assymmetrical) |
|
|
what is the concept of "odds"?
|
-an alternative way of representing the likelihood of an event
-if p is the probability of an event, then odds = p/(1-p) -in other words, odds is the probability that an event happens divided by the probability that it doesn't happen -odds can also be thought of as the number of "successes" divided by the number of "failures" |
|
|
what is the range of odds?
|
when p varies between 0 and 1, the range of odds is (0, +infinity)
|
|
|
if p = 0.6, what are the odds?
|
0.6/0.4 = 3/2
|
|
|
if 431 people have blood type O and 728 people have other blood types, what are the odds in this population of blood type O?
|
431/728 = 0.59
|
|
|
what does an odds of 1 mean?
|
that the event is equally likely to occur and not to occur (probability of 50%)
|
|
|
what formula can you use to calculate p from odds?
|
p = odds/(1+odds)
|
|
|
what is the probability of event A if the odds of event A is 3.5?
|
3.5/(1+3.5) = 0.78
78% |
|
|
why is odds a more natural scale for multiplicative comparisons?
|
-because if I have a probability of 0.6 of voting in an election, it doesn't make sense to say that someone else's probability of voting is 2x as great
-but it does make sense to say someones odds of voting are 2x as great |
|
|
how do you calculate an odds ratio?
|
-calculate the odds of event A when B is present (odds1)
-calculate the odds of event A when B is not present (odds2) -divide odds1 by odd2 -this tells you that B multiplies the odds of event A by (odds ratio) |
|
|
how can we measure the effect of a dichotomous variable? e.g. if testing a drug, 90 people given the drug survive and 10 die; 70 of people not given drug survive, and 30 die. How would you calculate the effectiveness of the drug?
|
for those who got the drug, estimated odds of surviving = 90/10 = 9
for those who didn't get the drug, estimated odds of surviving = 70/30 = 2.33 the odds ratio is 9/2.33 = 3.86. This says that the effect of getting the drug is to multiply the odds of survival by 3.86 |
|
|
if odds1 = odds of survival if given drug and
odds 2 = odds of survival if not given drug what does an odds ratio above 1 indicate? what does an odds ratio equal to 1 indicate? what does an odds ratio below 1 indicate? |
-odds ratio above 1: the drug improves odds of survival
-odds ratio equal to 1: drug has no effect -odds ratio below 1: the drug decreases odds of survival (i.e. it is lethal) |
|
|
if the odds of survival if given drug is 103/17 and odds of survival if not given drug is 248/152, how would you express the odds ratio as a percentage? what if odds of survival are reversed for drug/no drug?
|
103/17 = 6.05
248/152 = 1.63 6.05/1.63 = 3.71 (3.71 - 1) x 100% = odds of survival is 271% higher if take drug If reversed: 1.63/6.05 = 0.27 (1-0.27) x 100% = odds of survival are 73% lower if take drug |
|
|
why do we take the log of the odds when modelling a regression of a dummy dependent variable?
|
because this transforms the probability of the dummy variable so that it varies between negative infinity and positive infinity instead of between 0 and 1
|
|
|
what does a graph of the log odds look like?
|
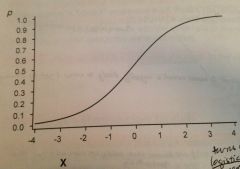
|
|
|
what are the implicit assumptions of the logit model?
|
1. No omitted explanatory variables (especially those correlated with the included variables)
-a little stronger than assumption of OLS...even if not correlated with included variables, can still create problems 2. No measurement error in explanatory variables 3. Observations are independent 4. Dependent variable doesn't affect the independent variables (i.e. don't have reverse causation in our relationship) |
|
|
what do we usually use to estimate a logit model?
|
maximum likelihood
-chooses parameter estimates which, if true, would make the observed data as likely as possible |
|
|
what are the good statistical properties of maximum likelihood?
|
-consistent (i.e. estimates will be approximately unbiased...note: the bigger your sample, the closer estimates will be to true values)
-asymptotically efficient (Gaus Markov theorem implied OLS efficient in that had minimum standard errors...also true of ML) -asymptotically Normal (same as Central Limit theorem) -internally consistent (nice thing about this is you get the same results from individual-level data and grouped data [assuming no info is lost in grouping]) |
|
|
when do we use maximum likelihood (ML)
|
-when other approaches are infeasible or nonexistent
|
|
|
what commands can you use in stata to do logistic regression? what is the difference between them?
|
-logistic (reports odds ratios)
-logit (reports beta [normal] coefficients) |
|
|
if find coefficient on x1 (average gift) is 0.0016, where y = probability of response, how do we interpret this coefficient?
|
-since the coefficient is a beta coefficient, need to do a transformation. Must multiply take e to the 0.0016, subtract this from 1 and then multiply by 100
-so: 100([e^0.0016]-1) = 0.16 -interpretation: a one unit increase in average gift is associated with a 0.16% increase in the odds of responding |
|
|
if find odds ratio of x2 (response to last mailing) is 1.54, where y = probability of response to current mailing, how do we interpret the coefficient?
|
-since the coefficient is given in odds ratio, we just subtract the odds ratio from 1 if it lower than 1 and subtract 1 from it if it is above 1
-since 1.54 is above 1, we subtract 1 from it --> 0.54 -we then multiply this number by 100% --> 54% -interpretation: responding to the last mailing increases odds of responding to current mailing by 54%, controlling for other variables in the model -or, we could say, the odds of responding for someone who responded last time is 1.54 times the odds of responding for someone who did not respond last time, controlling for all other variables in the model |
|
|
what problem is logistic regression prone to?
|
-non-convergence or quasi-complete separation
-most common cause of this problem is when have a categorical indep. variable in model and, for at least one of the categories, either everyone has the event or non one has the event -ex: if dep var = smoking indep var = gender 0 women in your sample smoke leads to coefficient of dummy variable getting larger until it reaches infinity |
|
|
what should you do to estimate a regression of a categorical dependent variable with more than one category (in situation where categories are unordered)?
note: no Q on this on final |
-can use mlogit command (multinomial logistic regression)
-this is essentially same as logistic regression, but for a dep. variable with more than one category (i.e. non-binomial) -must drop one category from the model so that it acts as a reference category (same as in the case of a categorical indep. variable) |
|
|
how should you choose which category of the dependent variable to omit?
note: no Q on this on final |
-choice of reference category does not change the model, but judicious choice can aid interpretation
|
|
|
what will the output of mlogit command provide?
note: no Q on this on final |
if there are 3 categories, mlogit will produce 2 different equations
-one equation will be a comparison of category 1 with category 3 -other equation will be a comparison of category 2 and category 3 -the coefficients will actually be comparisons with the omitted category |
|
|
what kind of model might you want to use if your dependent variable has more than 2 categories and the categories are ordered?
note: no Q on this on final |
cumulative (ordered) logit model
|
|
|
what does a cumulative logit model assume
note: no Qs on this on final |
it assumes that regardless of where we dichotomize the dependent variable y, the effect of the independent variable on the logit of y is the same
-for example, if there are 4 categories of y, cumulative logit model says that we could compare the 4th category with the first 3, the 4th and 3rd with the 2nd and 1st, or the 4th and 1st with the 3rd and 2nd...n all cases, the effect of x would be the same -note: no Qs on this on final |
|
|
what does the following tell you about the R-squared of a model:
-the coefficient estimates have large standard errors and small t-statistics |
the R-squared is low
|
|
|
does having a low R-squared mean that the model is wrong? does it mean that other variables should be considered for inclusion in the model?
|
-no, it doens't mean model is wrong
-yes, it does mean that you might consdier other variables |
|
|
when would you conclude that a regression model is wrong?
|
-when includes variables that have no impact on outcome variable (this is misspecification)
-when the causal relationship between 2 variables is misspecified in the model |
|
|
what is statistical efficiency? does it refer to true or estimated standard error?
|
-efficiency of a statistic is degree to which it is stable from sample to sample
-talking about TRUE standard error, not estimated standard error -if statistc A has a smaller se than statistic B, then statistic A is more efficient than statistic B |
|
|
what can bias the estimates of coefficients?
|
measurement error in the independent variables
|
|
|
can you use data to determine causal ordering of a path diagram?
|
No! you must rely solely on theory and common sense
|
|
|
what is the problem with relying on theory to decide what variables to include in a regression model?
|
might miss something important that neither theory nor you anticipate
|
|
|
what statistics can you use to compare 2 regression models, 1 with 10 variables and one with 5 variables?
|
it depends
-if the 5 variables are a subset of the 10, better off doing a direct test of whether additional variables have any effect. You should do an F-test of the additional variables (a direct test of the increment of R-sqared) -if the 5 variables are not a subset of the 10, you should compare the adjusted R-squareds of the 2 models |