![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
74 Cards in this Set
- Front
- Back
|
Was ist VQ? |
Vector Quantisation -> ein großer Vector wird duch eine kürzere Darstellung approximiert --> aproximation of data space with smaller number of vectors --> supervised und unsupervised |
|
|
Loss Functions for Clustering? |
Intraclass W(C) ? InterClass B(C)? Total? T(C) = W(C) + B(C) Minimizing W(C) is equivalent to maximizing B(C) |
|
|
VonNeumann Computer VS Neural Computationalnova.com |
•Processing: Sequential - Parallel •Processors: One - Many •Interaction: None - A lot •Communication: Poor - Rich •Processors: Fast, Accurate - Slow,Sloppy•Knowledge: Local - Distributed •Hardware: General Purpose -Dedicated•Design: Programed - Learned |
|
|
WhyNeural Networks
|
•Massive parallelism.
•Massive constraint satisfaction forill-defined input. •Simple computing units. •Many processing units, manyinterconnections. •Uniformity (-> sensor fusion) •Non-linear classifiers/ mapping(-> good performance) •Learning/ adapting |
|
|
Using of Neural Nets? |
•Classification •Prediction •Function Approximation •Continuous Mapping •Pattern Completion •Coding |
|
|
DesignCriteria |
•Recognition Error Rate •Training Time •Recognition Time •Memory Requirements •Training Complexity •Ease of Implementation •Ease of Adaptation |
|
|
Possible NetworkSpecification? |
–Net Topology –Node Characteristics –Learning Rule –Objective Function –(Initial) Weights –Learning Parameters |
|
|
DesignProblems? |
•Local Minima
•Speed of Learning •Architecture must be selected •Choice of Feature Representation •Scaling •Systems, Modularity •Treatment of Temporal Features andSequences |
|
|
Pattern recognition Unterteilung? |
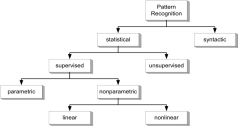
|
|
|
Parametric VS Non-parametric |
– Parametric: assume underlying probability distribution;estimatetheparametersofthisdistribution - Non: Estimate probability of error or error citerion directly from training data.Examples:Parzen Window, k-nearest neighbor, perceptron |
|
|
Bayes! |
- Formel, Beschreibung - Warum optimal? |
|
|
Problems of ClassifierDesign |
–Whatandhowmanyfeaturesshouldbeselected?–Anyfeatures?–Themorethebetter?–Ifadditional featuresnot useful(same meanand covariance),classifierwill automaticallyignorethem?a |
|
|
Curse of Dimensionality |
•Generally,addingmorefeaturesindiscriminantlyleadstoworseperformance!•Reason:–TrainingData vs. NumberofParameters–Limitedtrainingdata.•Solution:–selectfeaturescarefully–reducedimensionality–PrincipleComponentAnalysis |
|
|
Non-Parametric Techniques? |
Aufzählen und erklären: Parzen Window Volume toolarge -> looseresolutionVolume toosmall-> erratic,poorestimate K-NearestNeighbors(KNN) •Forfinite numberofsamplesn,wewantk tobe:large for reliableestimatesmall to guaranteethatall k neighborsarereasonablyclose.•Needtrainingdatabasetobelarger."There is no data like more data." |
|
|
Fisher Linear Discriminant ? |
nachschauen. |
|
|
bessere generalisierung? |
- brain damage - weight decay? - cascade correlation - odb /obs - meiosis |
|
|
Boltzman maschine |
? |
|
|
Hopfield net |
? |
|
|
LVQ Stufen |
- Learning Vector Quantifikation - supervised - examples audio compression, features extraction (- filters not so relavant infos) -related to kNN - LVQ1: bestimme neuron wo gewichte am besten zum Sample passen. Passe die gewichte dieses neurons mit update an (+ wenn selbe klasse, - wenn false klasse) und lernrate alpha. LVQ2: wie davor, nur werden die 2 besten neuronen gesucht. Für den Fall das eine Klasse mit der von dem input übereinstimmt. Beide Neuronen verschiedenen Klassen. Und Mittelsenkrechte test mit min(di/dj, dj/di) > s. wobei s = 1 - v / 1+ v mit z.B. v = 0,2. Dann updateregel + bei richtiger und minus bei falscher klasse LVQ3: Verteilt die Gewichtung zusätzlich innerhalb der Klassen. D.h. wenn die beiden nähesten vektoren die gleiche Klasse haben dann ist das update mit + für beide neuronen, aber nochmal abgeschwächt durch epsilon wert OLVQ1: mit angepasster Lernrate für jeden Neuron, je nach Historie. Lernarte a_t = a(t-1) / 1+ s(t) * a(t-1), wobei s(t) = 1 wenn gleich Klasse und -1 wenn nicht |
|
|
Warum MLP anstatt vieler einfacher Perceptronen? |
Die gegenseitige Abhänigkeit wird nicht modelliert. |
|
|
Wovon hängt die Generalisierung ab |
E_test = E_train + #Paramter/#Trainingsdaten |
|
|
Wie kommt Zickzack in Trainfehler zustande |
Man springt über das Ziel (minimum) hinaus. |
|
|
Woran liegt es wenn die Fehlerfunktion nicht besser wird? |
Gradientenbeitrag zu klein oder zu gross. Man kommt erst garnicht vom platue runter oder springt die ganze zeit um es herum. Was ist der Fall? Gradienten in die selbe Richtung Fall 1, Gradienten in verschiedene Richtung Fall 2. |
|
|
Was ist Reinformcement Learning |
Zwischenstufe zu überwachten und unüberachten lernen. Gibt zu bestimmten Zeitpunkten eine Belohnung oder Bestrafung für gute/ schlechte Aktionen. |
|
|
Welche Aufteilung von Klassifkation gibt es? |
- überwacht/ nicht - linear / nicht linear - parametrisch / nicht parametrisch |
|
|
kohent som |
? roginas script mehr details |
|
|
Entscheidungsfläche? XOR Problem |
malen |
|
|
wie meiosis? |
Bei Varianz splitten Was für eine Varianz denn? |
|
|
Welche Fehlerfunktionen |
- MSE - CE - CFM |
|
|
Wie kann man training beschleiningen |
Momentum, Qickprop, Resilent Propagation |
|
|
Wie kann man NN in der Spracherkennung einsetzen |
Schätzen der Emissionen, Sprachmodell Man erhält posteriori und muss in klassenbedingte umwandeln. |
|
|
Stärken Schwächen BP? |
? |
|
|
TDNN erklären |
paper Weight sharing!!!! |
|
|
Sto modale Netze |
? |
|
|
Ist ein MLP linear |
Nein! Tam nochmal fragen ob Aktivierungsfunktion eine Rolle spielt |
|
|
Kann man MLP unüberwacht trainieren? |
Ja durch Autoencoder :) |
|
|
Generalisierbarkeit |
- weight decay - weight elimination - dropout - weight limitation |
|
|
Wozu sind neurale Netze gut |
In Aufgaben die Menschen in Verlgeich zu Computern gut sind, z.B. Mustererkennung. Oder auch Klassifkation. |
|
|
Zeichne und erkläre Perceptron |
Mit Tam durchgehen |
|
|
Wieso sind NN eine Zeit aus der Mode gekommen? |
Gab Paper wo gezeigt wurde das Perceptons nur lineare Problem lösen können. Mit der Verbindung in MLPs sind sie mächtiger |
|
|
Wie einzlenes Neuron trainieren? |
Deltaregel? |
|
|
Was kann ich machen wenn ich verrauschte Daten habe |
Denoising Autoencoder |
|
|
Welche Aktivierungsfunktionen |
Alle malen und Eigenschafen! Mit TAM nochmal: - Stufenfuntkion - Linear - Sigmoid - Softmax - ReLU - Softplus - tanh |
|
|
Nachteil Sigmoid |
Kann saturieren, dann ist der Gradient sehr klein und der Lernvorgang langsam. Gerade in Verbindung mit dem MSEist dies oft problematisch, da ein Sample mit bspw. t_x=0 und o_x fast 1 viel zum Fehler beiträgt, aber es sehr langedauert bis dieser Fehlerbeitrag behoben ist. |
|
|
Was kennen Sie noch für Fehlerfunktionen? |
Cross entropy, gut für Klassifikationsaufgaben zusammen mit Softmax, maximiert die Log-Wahrscheinlichtkeit, desTargets. Dann gibt es noch Classification Figure of Merit, man versucht den Abstand der Targetklasse und derzweitbesten Klasse zu maximieren. |
|
|
Nachteil der Softmax? |
Im Output blöd, weil sie von alle Neuronen abhängt und e^x nicht so schnell zu berechnen. |
|
|
Wie stelle ich die Lernrate ein? |
- Exponentially Decying und Newbob-Scheduling - AdaGrad, Resilient Propagation, Weiterentwicklung MeanSquare Resilient Propagation |
|
|
Wie werden die Neuronen/ Synapsen trainiert und wie macht man das beim NN? |
Beim NN: mit den Gewichten. In der Natur: Synapsen, je öfter sie verwendet werden, je dicker/stärker werdenSie. (Eher wie dings verfahren?) |
|
|
Was ist denn der Vorteil der Momentum Methode gegenüber der Scheduling Methode? |
Kann mich aus lokalen Minima retten |
|
|
Wie wird die Aktivierung der Neuronen in BMs berechnet? |
BMs sind stochastisch (Aktivierung ist Wahrscheinlichkeit Abhängig von Sigmoidfunktion), im Gegensatz zu Hopfieldnetzen(Schwellwertfunktion). |
|
|
Was ist das Problem von BMs? |
Training ineffizienz da voll verbundener Graph RBMs, bipartiter Graph, Daten werden in Eingabeschicht eingegeben, verdeckte Schicht repräsentiert innere Verteilung |
|
|
Welche Möglichkeiten gibt es zur Bestimmung der Lernrate |
Feste LR, Definierte Folge, Zeitabhängig, Gewichtsabhängig, Abhängig vom Fehler, Abhängig vom Gradienten, Momentum |
|
|
Wie funktioniert Momentum? Formel? |
W' = W + lernrate * (alpha * delta W_alt + delta W) |
|
|
Was wäre denn die ungeglättete Version von tanh? |
geglättest sign funktion (nicht ableitbar) --> naschschlagen geglätte step? --> sigmoid |
|
|
Welche Methoden gibt es denn zur Bestimmung der Gewichte eines MLPs? |
(L-)BFGS, Conjugate Gradient, Quasinewton |
|
|
Was sind Hopfield Netze |
- Netze bestehend aus McCulloch-Pits Neuronen. - Jeder mit jeder verbunden, nur nicht mit sich selbst. - Knoten sind Ein und Ausgabe - nicht sehr leistungsfähig - können Muster wieder herstellen - durch symmetrische Gewichte konvergiert das Netz (stabiler Zustand). - stabiler Zustand ist ein lokales Minima |
|
|
Was ist eine BM? |
- Energy based NN. - mehr. |
|
|
Was ist SOM |
- Self-Organizing Map (SOM) - unsupervised learning method - two-dimensional array of neuron (often) - extra input neuronen die voll verdrahtet mit SOM Neuronen - winner takes it all, welches neuron am ähnlichsten zum input, und alle nachbarn werden nach lernregel angepasst 1) random gewichte 2) sample ziehen 3) matching (welches neuron gewinnt) 4) update nachbarn 5) wieder zu 2) |
|
|
Hebbian learning |
was genau? -genutzt in LVQ 1) self amplification: wenn neuronen auf beiden seiten aktiv, stärken, wenn unterschiedlich verbindung schwächen w_ij = x_i * x_j 2) competition: winner takes at all. the most similiar one wins. 3) cooperation: neurons tend to cooperate with each other. 4) structural information. |
|
|
Clustering Methoden? |
- k-Means: Anzahl der Partionen bekannt. Dann zufällig einzeichen, alle Punkte zum nähesten Cluster zuweisen. Neuen Mittelpunkt bestimmen und nochmals ausführen. - fuzzy k-Means not picking nearest center, stattdessen zugehörigkeitswarscheinlichkeit ausrechnen (zu welchen ist man wieviel näher als zum anderen) - GMM mit EM, könnten z.B. K-Means zur initialisierung verwenden. - und VQ!! - SOM |
|
|
Wie EM? |
Zwei schritte, Expectation (neu Zuordnung der Punkte) und Maximation (Anpassung des Models zu den Daten). Diese wiederholen bis sich model nicht ändert |
|
|
Male Perceptron, MCP, Rosenblatt Neuron |
V04_ Folie 5 |
|
|
was heist lineare separierbar? |
Wenn 2 Mengen unterschiedlicher Klassen. --> konvexe Hülle beider disjunkt -- > wenn es ein w gibt, das x_c1 * w >0 und x_c2 *w <= 0 |
|
|
Perceptron Algo |
- supervised learning - data is linear seperable - invertieren aller features der anderen Klasse (inverted data trick) - update bei falscher Klassifizierung w_t = w_t-1 + alpha * x; |
|
|
Wie Klassifiziere ich mit einem Perceptron mehrere Klassen? |
- pairwise classifkatoren: für jede Kombination eigenen Klassifkator= k * (k+1) Stück oder layer von perceptron - individual: jeder sagt wie sicher er sich ist das es die Klasse ist. Der mit der höchsten warsch. gewinnt. |
|
|
Arten der Features |
Nominal: no median, stattdessen mode (am häufigsten) Ordinal: mit Ordnung Interval: no true zero, temperaturen Ratio Feature: ist halb so gross |
|
|
Distanz metriken |
4 Eigenschaften d(x,y) >= 0 d(x,y) = 0 <=> x=y (pseudometric - after Dim Red) d(x,y) = d(y,x) (Quasimetric) d(x,z) = d(x,y) + d(y+z) alles Jacardi, Levnesthein metric |
|
|
preprossing? |
leads to more circular error funtions for linear activation: - mean substraction - rescale |
|
|
SDG |
Stochast descent gradient 1: randomize training 2: foreach x in Training forward pass |
|
|
MLP Design criteria |
-Network Topology -Activation functions - Error function - Initial weights - Learning Rate - Mini-Batch size - Data pre-processing |
|
|
Autoencoder Problems? |
Which AF for hidden unit? Linear: - is like PCA - pass tough instead of learning --> non linear are needed AF for output? Depends on training data, because whole spectrum has to be mapped Error function? CE for binary MSE for real L1 and L2 regulaitions are good :) --> Denoisung, with random mask in input |
|
|
Cascade correlation |
- nach und nach hidden layers hinzugefügt - zuerst nur in und output - verbindung wird trainiert und dann fixiert - dann wird candidaten pool aufgemacht und die candidaten auf den resudial error trainiert - der candidate der den fehler am besten approximiert wird genommen und hinzugefügt. - dann wieder zu Schritt 2 und die verbindung zu den outputs lernen - stop wenn fehler nicht mehr besser wird oder so |
|
|
meiosos |
hinfügen von hidden units wenn hohe unsicherheit - mittelwert und gewicht wird gelernt, wenn varianz zu hoch richtung input und output dann wird hidden unit geteilt sum(mean) / sum(var) > 1 - instabilität beim hinzufügen |
|
|
computer vision task nach schwierigkeit |
-classifaction - localisation - detection - segmentation |