![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
90 Cards in this Set
- Front
- Back
|
Symmetric (Hermintian) |
AT=A |
|
|
Screw Symmetric |
AT=-A |
|
|
Orthagonal |
AtA=AAt=I |
|
|
Lower triangular |
|
|
|
a symmetric n-by-n matrix M is ________ if the scaler z^T*M*z is postive for every non-zero column vector z of n real numbers |
positive definite [2 -1 0; -1 2 0; 0 -1 2] |
|
|
herminitian Matrix |
A^T=A |
|
|
skew herminitian |
A^T= -A |
|
|
orthagonal matrix |
(Q^T)Q=Q(Q^T)=I |
|
|
if the entries in a matrix above the main diagonal are zero the matrix is called |
lower triangular |
|
|
if the entries in a matrix below the main diagonal are all zero the matrix is called |
an upper triangular |
|
|
a square matrix is a called ________________ if it is invertable |
non-singular(invertible) |
|
|
a matrix that is not invertible is called a ______________ |
singular matrix |
|
|
any of a number of results about linear operators or matrices |
spectral theorem |
|
|
_________________ for an inner product space V with finite dimension is a basis of V whose vectors are orthonormal, that is, they are all unit vectors and orthogonal to each other |
orthonormal basis |
|
|
a collection of objects called vectors which may be added together and multiplied by numbers called scalars |
vector space |
|
|
for every _____________ there exists a ______ |
vector space there exists a basis |
|
|
the ________________ of a vector space V is the number of vectors of a basis of V |
dimension |
|
|
a set of vectors are linearly independent iff |
all the coefficients in the a1x1 + a2x2 + ... +anxn=0 equals 0 |
|
|
this is a function that assigns a strictly positive length or size to each vector in a vector space |
norm |
|
|
the p-norm is equal to |
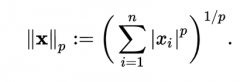
|
|
|
for a matrix norm ||A|| is |
greater than or equal to 0 |
|
|
||A||=0 iff |
A=0 |
|
|
||oA|| = |
|o|||A|| where o is a scaler |
|
|
||A+B|| ________||A|| + ||B|| |
less than or equal to |
|
|
for all square matrices ||AB|| ____||A|| ||B|| |
less than or equal to |
|
|
a factorization of a real or complex matrix and is the generalization of the eigendecompostion of a positive semidefinite normal matrix |
Singular Value Decomposition |
|
|
The uses of singular value decomposition |
signal processing and statistics, determination of the rank, range, and null space of a matrix |
|
|
a faster more economical computation of SVD |
reduced version of SVD |
|
|
If n< |
QR decomposition |
|
|
a decomposition of a matrix A into a product A=QR where Q =______ and R=_______ |
Q=orthogonal matrix and R is a upper triangular matrix |
|
|
the rank of A is equal to the rank of |
the transpose of A
|
|
|
the SVD can be useful because it can find the ______ of a matrix |
the rank |
|
|
lower triangular matrices can be solved by |
forward substitution |
|
|
upper triangular matrices can be solved by |
backward substitution |
|
|
_________ is the matrix form of Gaussian Elimination |
LU decomposition |
|
|
systems of linear equations are often solved by the |
LU decomposition |
|
|
any square matrix has a |
LUP factorization |
|
|
any matrix that is invertible, has a ________ factorization iff its leading principle minors are nonzero |
LU |
|
|
computing the LU decomposition requires how many steps |
2(n^3)/3 |
|
|
It is faster and more efficient to compute the LU decomposition of a matrix A once and then solve the triangular matrices for the different b rather than performing |
Gaussian Elimination |
|
|
Once you have PA=LU you can use forward and backward substitution on the equations |
Ly=Pb and then Ux=y |
|
|
The advantage of LU decompostion over QR Decompostion |
LU is approximately 2(n^3)/3 steps and QR is approximately 4(n^3)/3 (LU IS TWICE AS FAST) |
|
|
a square binary matrix that has exactly one entry of 1 in each row and each column and 0's elsewhere |
permutation matrix |
|
|
the dimension of a rowspace is called ________ |
the rank of the matrix |
|
|
elementary row operations have no effect on __________ |
the rowspace of the matrix |
|
|
when a matrix is in rref the non zero rows are |
linearly independent |
|
|
the rank of the matrix is equal to _________ in rref |
number of non zero rows |
|
|
the rank of a matrix plus the dimension is equal to |
the number of columns |
|
|
in a matrix if the rows are linearly independent then the rank is equal to |
the amount of linearly independent rows |
|
|
the column space is key to |
existence of solutions
|
|
|
the nullspace is the key to existence of |
uniqueness |
|
|
in general is the rank is equal to the nullspace |
the null(A) is equal to the zero vector and the solution to Ax=b (if there is one) is unique |
|
|
fewer equations than unknowns (r |
undetermined system (Infinitely many solutions) |
|
|
same number of equations as unknowns |
possibly one unique solution |
|
|
more equations than unknowns |
no solution |
|
|
the row space is ___________ to the nullspace |
perpendicular |
|
|
the column space is ___________ to the left nullspace |
perpendicular |
|
|
a matrix A is non singular iff |
i) A^-1 exists ii) R(A)=R^n (dimR(A)=n) iii) N(A)=0(vec) iv) no zero eigenvalues |
|
|
if the rank of matrix A is equal to the num of rows and columns then |
the solution is unique |
|
|
if the rank is equal to the num of rows and less than the num of columns (norm >rows) |
there is an infinite amount of solutions |
|
|
if the rank is less than the number of rows and equal to the number of columns then |
there is 0 solutions if rows>col and 1 solution if N(A)=0 |
|
|
if rank is less than both rows and columns then Ax=b has |
zero solutions |
|
|
one key applications of the SVD is |
the construction of low rank approximations to a matrix |
|
|
In a square matrix: if the rank is = the number of rows and col |
there is a unique solution |
|
|
In a square matrix: if the rank is less than the num of rows or columns then |
there are infinite solutions |
|
|
If there are more equations than unknowns then |
there is no solution |
|
|
the instability in the guass elimination method could be solved by
|
permuting the order of the rows by pivoting
|
|
|
the pivot is choosen by |
the largest absolute value in a subdiagonal entry in the column |
|
|
Gauss Elimination and Gauss Elimination Partial Pivoting is a |
direct method |
|
|
Iterative methods for Ax=b approximate solutions of a linear equation and find solutions that |
converge to an exact solution |
|
|
two types of iterative methods |
i) classical ii) minimization algorithms |
|
|
if a matrix is _____________ then the Jacobi method converges for any initial guess x(0) |
strictly diagonally dominant |
|
|
classical iterative methods take advantage of the decomposition |
A=D+L+U |
|
|
three types of iterative methods
|
Jacobian, Gauss Siegel, Successive over relaxation(SOR) |
|
|
methods that give solutions after an amount of computation that can be specified in advance |
direct methods |
|
|
iterative method |
starts from an approximation to the true solution and if successful obtain a better and better approximation from a computation cycle repeated as often as may be necessary for achieving required accuracy |
|
|
If matrices have large main diagonal entries, we use which method |
iterative methods |
|
|
you would use what method if your matrix is sparse or with many zeros in it and why? |
an iterative method because you wouldnt want to waste space storing zeros |
|
|
a sufficient condition for convergence in the gauss seidel method is |
||C||<1 where ||C|| = sqrt(sumj sumk cjk^2) |
|
|
Why is the gauss seidal a method of successive corrections? |
because for each component we successively replace an approximation of a component by a corresponding new approximation as soon as the latter has been computed |
|
|
What is a simultaneous correction iteration method? |
this is when no component of an approximation is used until ALL the components of x(m) have been computed (Jacobi iteration) |
|
|
the important facotrs in judging the quality of a numeric method are |
amont of storage amount of time (number of operations) effect of roundoff error |
|
|
minimization algorithms |
extremely useful techniques for solving large linear systems of equations |
|
|
advantages/disadvantages of direct methods |
they compute the exact solution but with high computational cost and (o(N^3)/3) |
|
|
advantages/disadvantages of iterative methods |
they converge to the exact solution with some tolerance they are faster with O(mn^2) but they are not garenteed to converge |
|
|
pivoting in the gauss elimination is unnecessary with what kind of matrices |
positive definite systems |
|
|
why can direct methods be bad |
direct methods could use a great deal of storage and perhaps computation time |
|
|
why isnt jacobis method used |
slowest iteration method |
|
|
in the Succession over relaxation, the acceleration factor is used to |
minimize the M0 and maximized the convergence rate |
|
|
|
|