![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
39 Cards in this Set
- Front
- Back
|
Welche Fehlerquellen für Bitfehler gibt es? |
- können während des Ablaufs eines Programms in der CPU auftreten - oder bei der Übertragung von Daten zu anderen Systemkomponenten durch - Langzeitarchivierung von Daten auf Magnetbändern oder Platten als weitere Fehlerquelle. - Während den Bitfehlern in einem Computer meist ein Defekt in der Hardware zugrunde liegt, sind es Umwelteinflüsse wie Strahlung, Temperatur und magnetische Induktion, |
|
|
Welche Arten von Bitfehlern werden unterschieden? |
- einfache Bitfehler (isolierte Bits) - Fehlerfolgen (Burst-Errors), also Gruppen aufeinanderfolgender Bitfehler
|
|
|
Welche Fehler sind trotz moderner Technik unvermeidbar und welche sind seltener geworden? |
- seltener: Bitfehler - unvermeidbar: Ubertragungsfehler und Archivierungsfehler (flipped bits) |
|
|
Welche Ursachen gibt es für Fehler bei der Datenübertragung und Langzeitspeicherung? |
- thermisches Rauschen - Siganstörung - elektrische Impulse |
|
|
Wie kann mit auftretenden Fehlern generell umgegangen werden? |
- Versuch der Fehlerkorrektur - Ist dies nicht möglich, muss der fehlerbehaftete Datenblock verworfen werden |
|
|
Welche Voraussetzung muss gegeben sein, damit Fehler erkannt werden können? |
- zusätzliche Informationen verfügbar gemacht werden, die darüber Aufschluss geben - Diese Zusatzinformation muss natürlich dem ursprünglichen Datenblock zugeordnet werden. - Somit erhöht sich gleichzeitig die Anzahl der Bits, die notwendig sind, um den Datenblock zu speichern oder zu übertragen |
|
|
Was sind Redundanzbits? |
die zusätzlichen Bits, die zur Fehlererkennung oder Korrektur von Fehlern dienen |
|
|
Was ist ein Code? |
- Menge P von Bitmustern, mit denen die zu repräsentierenden Informationsworte dargestellt werden können. - Die Anzahl der Bits eines Codes bestimmt die Anzahl der möglichen Worte, die mit diesem Code dargestellt werden können. - Die meisten Codes verwenden die gleiche Anzahl an Bits für jedes der darzustellenden Codeworte. - Es existieren allerdings Codierungsverfahren bei denen die Anzahl der verwendeten Bits der Häufigkeit des Auftretens eines Bitmusters |
|
|
Wie kann die Effizienz / der Nutzungsfaktor eines Codes berechnet werden? |
- Sei ψ die Länge der Worte in einem Code - Code kann 2^ψ Bitmuster darstellen - Werden allerdings nur |P| = Υ Codeworte verwendet, hat der Code ψ - ln_2(Υ) redunante Bits - Effizienz: ρ = 2^Υ / 2^ψ |
|
|
Was ist die Parität? |
- die Information darüber, ob ein bestimmtes Codewort eine gerade oder ungerade Anzahl an Bitstellen besitzt, die eine logische 1 enthalten. - Man unterscheidet die gerade und ungerade Parität, wobei ein Paritätsbit dem Datenwort hinzugefügt wird, welches den Wert 1 oder 0 enthält, je nachdem wie viele Datenbits den Wert 1 aufweisen und welche Parität man anwendet. |
|
|
Was ist das Prinzip der geraden Parität? |
- Paritätsbit = 1, wenn die Anzahl der Datenbits mit dem Wert 1 ungerade ist - Somit wird gewährleistet, dass die Anzahl der 1-Bits in einem fehlerfreien Codewort immer ge- |
|
|
Was ist das Prinzip der ungeraden Parität? |
das Paritätsbit wird so gesetzt, dass die |
|
|
Wie kann das Paritätsbit für die gerade Parität berechnet werden? |
durch eine XOR-Verknüpfung aller Datenbits. |
|
|
Wo liegen die Grenzen der Parität? |
- ermöglicht nur Erkennung von Fehlern - ermöglicht nur die Erkennung eines ungeraden Auftretens von Fehlern - genaue Bitposition eines Fehlers kann nicht bestimmt werden |
|
|
Wie kann die Parität erweitert werden, damit eine genauere Fehlererkennung ermöglicht wird? |
- Mehrere Codewörter können zu Blöcken zusammengefasst werden - Die Parität jeder Zeile und jeder Spalte wird berechnet - Ein Fehler ändert die Parität des Datenwortes (Querparität) und der Spalte (Längsparität) - Dadurch kann die Stelle des Bitfehlers genau identifiziert werden |
|
|
Was ist der Hammingabstand? |
die Anzahl der Bitstellen, an denen sich zwei Codeworte unterscheiden |
|
|
Wie groß muss der Hammingabstand des Code sein, um k Fehler zu erkennen? |
k + 1 |
|
|
Wie groß muss der Hammingabstand des Code sein, um k Fehler zu korrigieren? |
2k + 1 |
|
|
Wie viele redundante Stellen werden bei der Hamming-Distanz mindestens benötigt? |
- m: Anzahl der Nachrichtenbitstellen - r: Anzahl der Redundanzbitstellen - (m + r + 1) |
|
|
Wie wird die Hammingmethode angewendet? |
- Dabei werden die Bits des Codes der Länge n fortlaufend mit eins beginnend nummeriert. |
|
|
Wie werden bei der Hammingmethode die Kontrollbits bei sieben Nachrichtenbits bestimmt? |
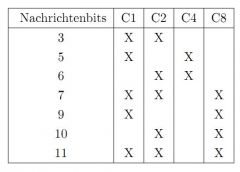
C8 an Stelle 7 wahrscheinlich falsch! |
|
|
Wie kann man mit der Hammingmethode auch Bitfehlergruppen oder Bursts der Länge <= k korrigieren? |
- Man ordne k Codeworte in einer Matrix mit einem Wort pro Zeile an. - Normalerweise würde ein Codewort nach dem anderen mit all seinen Checkbits von links - Stattdessen wird die Matrix Spalte für Spalte - Beim Lesen wird die Matrix dann spaltenweise rekonstruiert. - Falls sich ein Burst Error der Länge k ereignet, ist höchstens ein Bit in jedem der k Codeworte betroffen. |
|
|
Welche Arten der Fehlerüberwachung gibt es bei der Datenübertragung? |
vorwärts gerichtete Fehlerüberwachung und rückwärts gerichtete Fehlerüberwachung |
|
|
Was ist Forward Control? |
Der Empfänger kann Fehler erkennen und korrigieren. |
|
|
Was ist Backward Control? |
Erneutes Übertragen ist erforderlich. Dies wird durch timerbasierende Mechanismen und/oder mittels Empfangsbestätigung (Acknowlege- |
|
|
Warum wird meistens eine rückwärtsgerichtete Fehlerkontrolle verwendet? |
Zwar kann die vorwärtsgerichtete Fehlerkontrolle Fehler korrigieren, aber der Rechenaufwand, der notwendig ist um die Daten zunächst so zu kodieren, dass eine Fehlerkorrektur möglich ist, ist hoch - Ein ähnlicher Aufwand ist für den Datenempfang notwendig. Diese Pro- - Außerdem verringert die notwendige Redundanz die effektive, verfügbare Bandbreite des Datenübertragungskanals |
|
|
Wie funktioniert CRC? |
– Die Datenbits D werden als Binärzahl betrachtet – Der Empfänger kennt G, teilt < D,R > durch G. - Falls ein Rest entsteht wurde ein Fehler erkannt |
|
|
Was ist Raid 0? |
- In dieser Konfiguration simuliert das RAID einen alleinstehenden Plattenspeicher, dessen Speicherkapazität in Streifen (engl. stripes) mit je k Sektoren unterteilt ist - Es ist die Verantwortung des RAID Kontrollers die Daten entsprechend auf die Platten zu verteilen und den entsprechenden Datenblock beim Lesen wiederherzustellen. - Die Effzienz einer RAID-0 Konfiguration für das Speichern großer Datenmengen hängt natürlich von dem jeweiligen Betriebssystem ab, das dafür verantwortlich ist die jeweiligen Lese- und Schreibbefehle in die Übertragung |
|
|
Welches Problem löst Raid 0 und welches nicht? |

- Lösung für das Problem des großen Speicherbedarfs - es hilft nicht die Fehlertoleranz |
|
|
Was ist das gefährliche an Raid 0? |
die Fehlerwahrscheinlichkeit des RAID-0 gegenüber der eines einzelnen Laufwerks erhöht sich |
|
|
Was ist RAID 1? |
- der gesamte Plattenbereich wird kopiert und man hat somit eine primäre und eine sekundäre Version der gespeicherten Daten - Der RAID Kontroller ist dafür verantwortlich identische Versionen der Daten zu garantieren - Die beiden redundanten RAID-1 Komponenten werden als unabhängig betrachtet und haben individuelle Fehlerverhalten |
|
|
Welchen Vorteil hat Raid 1 bzgl. der Fehlertoleranz? |
- RAID-1 hat den Vorteil, dass das Versagen - Es müssen dann allerdings sofort alle Sektoren des fehlerhaften Laufwerks von dem funktionsfähigen Laufwerk kopiert werden, um eine neue Primär- oder Sekundärversion der Daten wiederherzustellen |
|
|
Was ist RAID 2? |
- Speicherung in 4-bit nibbles (halbe Bytes) und Generierung des jeweiligen Hamming-codes - Somit werden die 4-bit Daten in ein 7-bit Wort umgewandelt, welches auf 7 verschiedenen Laufwerken abgelegt wird - Wenn man nun die 7 Laufwerke so synchronisiert, dass die zu einem Wort gehörenden Daten auf gleichen Zylindern liegen, können 7-Bit Bitmuster parallel geschrieben und gelesen werden |
|
|
Welchen Nachteil hat RAID 2? |
Einer der Nachteile dieser Konfiguration |
|
|
Was ist RAID 3? |
- eine vereinfachte Version des RAID-2, - Somit liegt zwar jedes der Datenbits auf einem unabhängigen Laufwerk, die Paritätsbits werden jedoch gemeinsam auf ein zusätzliches Laufwerk geschrieben. - Mit diesem Ansatz reduziert man natürlich den Grad der Redundanz und somit ist der Overhead reduziert. |
|
|
Kann man in RAID2- und 3-Systemen Bitfehler erkennen und beheben? |
- man kann in den RAID-2 und RAID-3 Systemen genau entscheiden welches Bit bei einem Crash eines Laufwerkes verloren gegangen ist. - Diese zusätzliche Information erlaubt es den - Da die Berechnung der Parität eine aufeinanderfolgende Anwendung einer Exklusiv-Oder Funktion (also - Dieses Verfahren funktioniert allerdings nur für Fehler, die nur ein Laufwerk betreffen |
|
|
Was ist RAID 4? |
Es gibt ein komplettes Laufwerk für die Paritätsdaten
|
|
|
Was ist RAID 5? |
Der Paritätsstreifen wird über alle Laufwerke verteilt. |
|
|
Was ist der Nachteil von RAID 4? |
- Während die RAID-4 Konfiguration gegen Datenverlust durch das Ausfallen eines - Der Grund dafür ist, dass die Veränderung eines Sektors das Lesen aller Streifen erfordert, um die korrekte Parität zu berechnen. - Eine kleine Datenveränderung erfordert somit zwei Lesezugriffe und zwei Schreibzugriffe - Auf das Paritätslaufwerk muss jedes Mal zugegriffen werden, wenn Daten geschrieben werden, und somit kann es zu einem Flaschenhals werden |