![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
30 Cards in this Set
- Front
- Back
|
Data Mining
|
The nontrivial process ofidentifying valid, novel, potentially useful, and ultimately understandablepatterns in data stored in structured databases
|
|
|
Data
|
- Categorical
Nominal Ordinal - Numerical Interval Ratio |
|
|
Types of Data Mining Patterns
|
1. Association
2. Prediction (supervised) 3. Cluster 4. Sequential |
|
|
Types of data mining
|
1. Discovery driven
2. Hypothesis driven |
|
|
Data Mining Process
|
1. CRISP-DM (Cross-Industry Standard Process)
2. SEMMA (Sample, Explore, Modify, Model and Assess) 3. KDD (Knwledge Discovery Database) |
|
|
CRISP DM
|
Step 1: BusinessUnderstanding
Step 2: DataUnderstanding Step 3: DataPreparation (!) Step 4:ModelBuilding Step 5: Testingand Evaluation Step 6: Deployment |
|
|
SEMMA (Sample, Explore, Modify, Model and Assess)
|
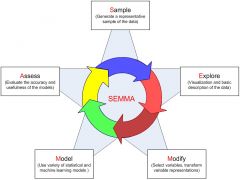
|
|
|
Classification
|
- Partof the machine-learning family
- Employsupervised learningLearnfrom past data, classify new data - Theoutput variable is categorical (nominal or ordinal) |
|
|
Assessment Methods for Classification
|
- Predictiveaccuracy (Hitrate)
- Speed(Modelbuilding; predicting) - Robustness - Scalability - Interpritability (Transparency;ease of understanding) |
|
|
Accuracy of Classification Models
|
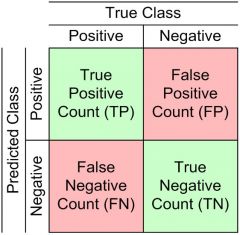
Confusion matrix
|
|
|
Accuracy of Classification Models
|
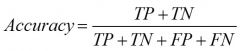
|
|
|
True Positive Rate - Accuracy of Classification Models
|

|
|
|
True Negative Rate - Accuracy of Classification Models
|

|
|
|
Recall - Accuracy of Classification Models
|
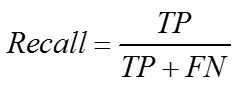
|
|
|
Precision - Accuracy of Classification Models
|
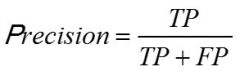
|
|
|
EstimationMethodologies for Classification
|
- Simple Split: Splitthe data into 2 mutually exclusive sets, training ~70%and testing 30%
- ForANN: the data is split into three sub-sets: training~60%, validation~20%, testing~20% |
|
|
Estimation Methodologies forClassification
|
k-FoldCross Validation (rotation estimation)
Leave-one-out bootstrapping jackknifing |
|
|
Classification TechniquesEnd Fragment
|
Decisiontree analysis
Statisticalanalysis Neuralnetworks Supportvector machinesCase-basedreasoning Bayesianclassifiers Geneticalgorithms Roughsets |
|
|
Decision Trees
|
Recursivelydivides a training set until each division consists of examples from one class
DT algorithms varies from splitting criteria, pruning criteria and stopping criteria ID3, C4.5, C5; CART; CHAID; M5 |
|
|
Cluster Analysis for Data Mining
|
Usedfor automatic identification of natural groupings of things
Partof the machine-learning family Employunsupervised learning “Learnsthe clusters of things” from past data, then assigns new instances Thereis no output variable Alsoknown as segmentation |
|
|
Applications of Cluster Analysis
|
- Natural groupings ofcustomers
- Identify rules for assigning newcases to classes for targeting/diagnostic purposes - Provide characterization,definition, labeling of populations - Decrease the size and complexityof problems for other data mining methods - Identify outliers in a specificdomain |
|
|
Clustering methods
|
- Statisticalmethods
such as k-means,k-modes,and so on. - Neuralnetworks adaptiveresonance theory - ART, self-organizing map - SOM - Fuzzylogic e.g.,fuzzy c-means algorithm - Geneticalgorithms Divisiveversus Agglomeration methods |
|
|
Association Rule Mining
|
- Avery popular DM method in businessFindsinteresting relationships (affinities) between variables (items or events)
- Partof machine learning family - Employsunsupervised learning - Thereis no output variable - Alsoknown as marketbasket analysis - Usedas an example to describe DM to non-data mining people, such as the“relationship between diapers & beer!” |
|
|
Association Rule Results for Business Use
|
- Put the items next to each other for easeof finding
- Promote items as a package: do not put one on sale if the others are onsale - Place items far apart from each other sothat the customer has to walk the aisles to search for it, and by doing sopotentially see and buy other items - On an e-commerce site, promote “Customers |
|
|
Applications of Association Rule Mining
|
Inbusiness: cross-marketing, cross-selling,store design, catalog design, e-commerce site design, optimization of onlineadvertising, product pricing, and sales/promotion configuration
Inmedicine: relationshipsbetween symptoms and illnesses; |
|
|
Algorithms for Assocaition
|
- Apriori
- Eclat - FP-Growth+ Derivatives - hybrids of the three |
|
|
Artificial Neural Networks forDM
|
- Artificialneural networks (ANN or NN) is a brain metaphor for information processing
- a.k.a.Neural Computing - Verygood at capturing highly complex non-linear functions! - Manyuses – prediction (regression, classification), clustering/segmentation - Manyapplication areas – finance, medicine, marketing, manufacturing, serviceoperations, information systems. |
|
|
Elements/Concepts of ANN/body
|
- Processingelement (PE)
- Informationprocessing - Networkstructure - Learningparameters - ANNSoftware |
|
|
Data Mining myths
|
- provides instantsolutions/predictions. - is not yet viable for businessapplications. - requires a separate, dedicateddatabase. - can only be done by those withadvanced degrees. - is only for large firms that havelots of customer data. - is another name for good-oldstatistics. |
|
|
Common DM Blunders
|
1.Selectingthe wrongproblem forDM
2.Ignoringwhat your sponsor thinks DM is, what it reallycan do 3.Notleaving sufficient time for data acquisition, selectionand preparation 4.Lookingonly at aggregatedresults andnot at individual records/predictions 5.Beingsloppy aboutkeeping track of the data mining procedure and results 6.Ignoringsuspicious (goodor bad) findings and quickly moving on 7.Runningalgorithmsrepeatedly & blindly, w/o thinking about the nextstage 8.Naivelybelieving everything you are told about the data 9.Naivelybelieving everything you are told about your own DM analysis 10.Measuringresults differently from the way your sponsormeasures them |