![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
22 Cards in this Set
- Front
- Back
|
Classical normal linear regression model (Assumptions) |
1. The regression model is linear in the parameters 2. The values of the regressors, the X's are fixed, or X values are independent of the error term. Here, this means we require zero covariance between ui and each X variable. 3. For given X's, the mean value of disturbance u is zero. 4. For given X's, the variance of u is constant or homoscedastic. 5. For given X's, there is no autocorrelation, or serial correlation, between the disturbances. 6. The number of observations n must be greater than the number of parameters to be estimated. 7. There must be sufficient variation in the values of the X variables. 8. There is no exact collinearity between the X variables 9. The model is correctly specified, so there is no specification bias 10. The stochastic (disturbance) term u is normally distributed. |
|
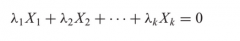
The term Multicollinearity |
Originally meant the existence of a "perfect", or exact, linear relationship among some or all explanatory variables of a regression model. |
|
|
Perfect or less than perfect multicollinearity |
- If multicollinearity is perfect, the regression coefficients of the X variables are indeterminate and their standard error are infinite. - If multicollinearity is less than perfect, the regression coefficients, although determinate, possess large standard errors (in relation to the coeffcients themselves), which means the coeffcients cannot be estimated with great precision or accuracy. |
|
|
Reasons for multicollinearity |
1. The data collection method employed: sampling over a limited range of the values taken by the regressors in the population. 2. Constraints on the model or in the population being sampled: For examplle, in the regression of electricity consumption on income (X2) and house size (X3) there is a physical constraint in the population in that families with higher incomes generally have larger homes than families with lower incomes. 3. Model specification: Adding polynomial terms to a regression model, especially when the range of the X variable is small. 4. An overdetermined model: This happens when the model has more explanatory variables than the number of observations. 5. Especially in time series data: the regressors included in the model share a common trend, that is , they all increase or decrease over time. |
|
|
The multicollinearity problem |
Multicollinearity violates no regression assumptions. - Unbiased, consistent estimates will occur, and their standard errors will be correctly estimated. The only effect of multicollinearity is to make it hard to get coefficient estimates with small standard error. - But having a small number of observations also has that effect, as does having independent variables with small variances. Thus "What should I do about multicollinearity?" - Is a question like "What should I do if I don't have many observations?" No statistical answer can be given. |
|
|
Truths about multicollinearity |
1. Even in the case of near multicollinearity the OLS estimators are unbiased. 2. Collinearity does not destroy the property of minimum variance: In the class of all linear unbiased estimators, the OLS estimators have minimum variance, that is they are efficient. 3. Multicollinearity is essentially a sample (regression) phenomenon: even if the X variables are not linearly related in teh population, they may be so related in the particular sample at hand. |
|
|
Practical consequences of Multicollinearity |
1. Although BLUE, the OLS estimators have large variances and covariances, making precise estimation difficult. 2. Because of consequence 1, the confidence intervals tend to be much wider, leading to the acceptance of the ''zero null hypothesis'' more readily. 3.Also because of consequence 1, the t ratio of one or more coefficients tends to be statistically insignificant. 4. Although the t ratio of one or more coefficients is statistically insignificant R_squared, the overall measure of goodness of fit, can be very high. 5. The OLS estimators and their standard errors can be sensitive to small changes in the data. |
|
|
What multicollinearity does? |
The fact that the F test is significant but the t values of X2 and X3 are individually insignificant means that two variables are so highly correlated that it is impossible to isolate the individual impact of either (income) or (wealth) on consumption. |
|
|
How does one know that collinearity is present in any given situation, especially in models involving more than two explanatory variables? (WARNINGS) |
1. Multicollinearity is a question of degree and not of kind. Meaningful distinction is not between the presence and the absence of multicollinearity, but between its various degrees. 2. Since multicollinearity refers to the condition of the explanatory variables that are assumed to be nonstochastic, it is a feature of the sample and not of the population. Therefore, we do not "test for multicollinearity" but can, if we wish, measure its degree in any particular sample. Multicollinearity is essentially a sample phenomenon, arising out of the largely nonexperimental data collected in most social sciences, we do not have one unique method of detecting it or measuring its strength. |
|
|
Rules of thumb (informal and informal) |
1. High R_squared but few significan t ratios. 2. High pair-wise correlations among regressors: Another suggested rule of thumb is that if the pair-wise or zero-order correlation coefficient between two regressors is high, say, in excess of 0.8, then multicollinearity is a serious problem. 3. Examination of partial correlations. 4. Auxiliary regressions: finding out which X variable is related to other X variables is to regress each Xi on the remaining X variables and compute the corresponding R_squared. If the computed F exceeds the critical F at the chosen level of significance, it is taken to mean that the particular Xi is collinear with other Xs; if it does not exceed the critical F, we say that it is not collinear with other X's, in which case we may retain that variable in the model. (if not we may need to consider of dropping). |
|
|
Klein rule of thumb |
Suggests that multicollinearity may be a troublesome problem only if the R_squared obtained from an auxiliary regression is greater than the overall R_squared, that is, that obtained from the regression of Y on all the regressors. |
|
|
Rule of thumbs (continue) |
5. Eigenvalues and condition index: to diagnose multicollinearity. |
|
|
6. Tolerance and variance inflation factor (VIF) |
As R_squared, the coefficient of determination in the regression of regressor Xj on the remaining regressors in the model, increases toward unity, that is, as the collinearity of Xj with the other regressors increases, VIF also increases and in the limit it can be infinite. -> The larger the value of VIF, the more troublesome or collinear the variable Xj. -> As a rule of thumb, if the VIF of a variable exceeds 10, which will happen if R_square exceeds 0.90, that variable is said to be highly collinear. |
|
|
7. Scatterplot |
It is a good practice to use a scatterplot to see how the various variables in a regression model are related. -> Four by four box diagram because we have four variables in the model, a dependent variable (c) and three explanatory. |
|
|
Do Nothing school of thought (Blanchard) |
- When students run their first ordinary least squares (OLS) regression, the first problem that they usually encounter is that of multicollinearity. - Many of them conclude that there is something wrong with OLS; some resort to new and often creative techniques to get around the problem. - But we tell them this is wrong. Multicollinearity is God's will, not a problem with OLS or statistical technique in general. -> Multicollinearity is essentially a data deficiency problem (micronumerosity, again) and sometimes we have no choice over the data we have available for empirical analysis. |
|
|
How to address the issue of multicollinearity (rule of thumb) |
1. A priori information: It could come from previous empirical work in which the collinearity problem happens to be less serious or from the relevant theory underlying the field of study. 2. Combining cross-sectional and time series data: pooling the data. 3. Dropping a variable(s) and specification bias. BUT: in dropping a variable from the model we may be committing a specification bias or specification error. 4. Transformation of variables. (first difference form, ratio transformation) 5. Additional or new data. 6. Reducing collinearity in polynomial regressions. Factor analysis and principal components such as ridge regression. |
|
|
Is Multicollinearity bad? |
Maybe not, if the objective is Prediction Only. -> Forecasting: the higher the R_squared the better the prediction. -> If not: also reliable estimation of the parameters, serious multicollinearity will be a problem because we have seen that it leads to large standard errors of the estimators. |
|
|
Conclusions |
1. One of the assumptions of the classical linear regression model is that there is no multicolinearity among the explanatory, the X's. Broadly interpreted, multicollinearity refers to the situation where there is either an exact or approximately exact linear relationship among the X variables. 2. The consequences of multicollinearity are as follows: If there is perfect collinearity among the X's, their regression coefficients are indeterminate and their standard errors are not defined. If collinearity is high but not perfect, estimation of regression coefficients is possible but their standard errors tend to be large. As a result, the population values of the coefficients cannot be estimated precisely. However, if the objective is to estimate linear combinations of these coefficients, the estimate functions, this can be done even in the presence of perfect multicollinearity. |
|
|
Although there are no sure methods of detecting collinearity, there are several indicators : |
1. The clearest sign of multicollinearity is when R_squared is very high but none of the regression coeffcients is statistically significant on the basis of the conventional t test.
2. In the models involving just two explanatory variables, a fairly good idea of collinearity can be obtained by examining the zero-order, or simple, correlation coeffcient between the two variables. If this correlation is high, multicollinearity is generally the culprit. 3. The zero-order correlation coefficients can be misleading in models involving more that two X variables since it is possible to have low zero-order correlations and yet find high multicollinearity. 4. If R_squared is high but the partial correlations are low, multicollinearity is a possibility. Here one or more variables may be superfluous. But if R_squared is high and the partial correlations are also high, multicollinearity may not be readily detectable. 5. One may regress each of the X bariables on the remaining X variables in the model and find out the corresponding coefficients of determination R)square. Drop it, provided that it does not lead to serious specification bias. |
|
|
Detection of multicollinearity is half the battle, the other half is concerned with how to get rid of the problem. |
1. Using extraneous or prior information 2. Combining cross-sectional and time series data 3. Omitting a highly collinear variable 4. Transforming data 5. Obtaining additional or new data. |
|
|
Conclusion |
5. We noted the role of multicollinearity in prediction and pointed out that unless the collinearity structure continues in the future sample it is hazardous to use the estimated regression that has been plagued by multicollinearity for the purpose of forecasting. |
|
|
Conclusion |
6. Although multicollinearity has received extensive (some would say excessive) attention in the literature, an equally important problem encountered in empirical research is that of micronumerosity, smallness of sample size. -> Goldberger "When a research article complains about multicollinearity, readers ought to see whether the complaints would be convincing if "micronumerosity" were substituted for "multicollinearity". He suggests that the reader ought to decide how small n, the number of observations, is before deciding that one has a small-sample problem, just one decides how high an R_squared value is in an auxiliary regression before declaring that the collinearity problem is very severe. |