Reading...
![]()
Play button
![]()
Play button
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
114 Cards in this Set
- Front
- Back
|
Auf welcher Ebene sind Betriebssysteme einzuordnen?
|
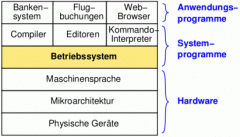
|
|
|
Was sollen Betriebssysteme leisten?
|
- Erweiterung (Veredelung) der Hardware: Hardware muss billig/schnell/zuverlässig sein und sich folglich auf das notwendigste beschränken - in der Folge schwierige Programmierung. Beispiel Schreiben auf Festplatte: BS findet freie Blöcke/legt Verwaltungsinformationen an, innere Struktur (Anzahl Köpfe, Zylinder, Sektoren,...) für Anwendung nicht mehr sichtbar.
- Abstraktion der Hardware: Unterschiedliche Architektur im Detail: Einteilung des Adressraums (Speicher, E/A-Controller), verschiedene E/A-Controller und Geräte. Fallunterscheidung durch BS, BS realisiert einheitliche Sicht für Anwendungen - Beispiel Dateien abstrahierender Speicher, wobei für Anwendungen kein Unterschied zwischen Festplatte, CD, USB-Stick, Netzlaufwerk sichtbar ist. Unter Unix selbst Drucker u.ä. wie Datein behandelt - daher _virtuelle Maschine_ durch BS. - Verwaltung von Betriebsmitteln: Prozessor, Speicher, Geräte - früher zu jedem Zeitpunkt nur eine Anwendung, heute Mehrprozess-/Mehrbenutzerbetrieb. Daher _Fairness_ und _Sicherheit_ notwendig: Beispiel Datei (Rechte durch BS eingehalten), Drucker (Auftragssortierung) |
|
|
Welcher Aspekt ist essentiell bei der Rolle als Mittler eines BS und welche Hardware-Mechanismen spielen dabei eine Rolle?
|
<p>Anwendungen können nicht <em>direkt</em>, d.h. unkontrolliert auf Hardware zugreifen.</p><br><p> </p><br><p>Unterstützend: Ausführungsmodi des Prozessors (System-/Benutzermodus), Adressumsetzung (virtueller Speicher).</p>
|
|
|
<p>Welche <strong>Generationen von Betriebssystemen</strong> gab es?</p>
|
<p> </p><br><ul><br> <li>1. Generation (-1955): Kein Betriebssystem - auf Basis von Elektronenröhren</li><br></ul><br><p>Programm (jedes mal) manuell in Speicher eingeben</p><br><ul><br> <li>2. Generation (-1965): Stapelverarbeitung mit Transistoren</li><br></ul><br><br><div>Lochkarten mit Programmcode (Assembler/Fortran): BS startet Übersetzer & Programm, nimmt Ergebnis entgegen, gibt es auf Drucker aus. Später mehrere Programme (<em>Jobs</em>) nacheinander auf Magnetband: <strong>Stapelbetrieb</strong> (<em>batch</em>). Bei nicht-interaktiven Jobs (Jahresabrechnungen) z.T. heute noch sinnvoll.<br><ul><br> <li>3. Generation (-1980): Einheitlicher Befehlssatz - integrierte Schaltkreise und Multiprogrammierung</li><br></ul><br><p>Betriebssystem abstrahiert Unterschiede der Rechner.</p><br><p>Einführung des Mehrprogrammbetriebs: CPU wartet 90% der Zeit, besser anderen Job abarbeiten statt zu warten durch Partition für jeden Job - hiermit Problematik der Verwaltung/Zuteilung von Betriebsmitteln.</p><br></div><p>Interaktive Nutzung der Rechner: Terminals statt Lochkarten/Drucker, mehrere Benutzer aktiv bei nötigem gegenseitigem Schutz.</p><br><ul><br> <li>4. Generation (1980-) Personal Computer</li><br></ul><br><br><div>Einführung von Mikroprozessoren (klein & billig), Rückkehr zu Einbenutzersystemen (DOS/Win95).<br></div><p>Zunehmende Vernetzung (Client/Server wieder mit mehreren Benutzern) bei Unix, Linux Windows ab NT.</p><br><p>Trend zu <em>verteilten Betriebssystemen</em>: Mehrere Rechner erscheinen wie ein einziger mit dem Ziel, höhere Leistungsfähigkeit und Zuverlässigkeit zu gewährleisten.</p>
|
|
|
Welche Arten von Betriebssystemen gibt es?
|
<strong>Mainframe</strong>: Schnelle E/A, viele Prozesse, Transaktionen<p><strong>Server</strong>: Viele Benutzer gleichzeitig, Netzwerkanbindung</p><br><p><strong>Multiprozessor-OS</strong>: Für Parallelrechner.</p><br><p><strong>Echtzeit-OS</strong>: <em>Hard</em>- (Fertigungssteuerung, Militär...: Zeitkritisch) vs. <em>soft-real-time</em> (Deadline toleriert ohne permanenten Schaden)</p><br><p><strong>OS für ES</strong>: Gesamte Software im ROM, i.d.R. nicht nachladbar. Beispiele QNX und VxWorks.</p><br><p><strong>OS für Chipkarten</strong>: Z.T. durch Kontakt mit Lesegerät via Induktion betrieben. Teilweise Java-orientiert, sodass Karten viele Java-Applets gleichzeitig bedienen können, sodass Multiprogrammierung gegeben ist und Aufteilen der Rechenzeit notwendig macht.</p>
|
|
|
Wie sieht die typische Architektur eines Multiprozessorsystems aus?
|
<p>Im Speicher: Eine OS-Instanz für <em>alle</em> Prozessoren</p><br><p>Jeder Prozessor kann OS-Code ausführen</p><br><p><em>Symmetrisches</em> Multicore-System: Gemeinsamer Adressraum für mehrere Prozessoren</p>
|
|
|
Welches sind die Elemente einer CPU?
|
<strong>Register</strong>: Ganzzahl-/Gleitkomma-Register, Befehlszähler (<em>Program Counter</em>), Kellerzeiger (<em>Stack Pointer</em>), Statusregister (<em>Program Status Word</em>)<p><strong>ALU</strong>: Führt eigentliche Berechnungen durch</p><br><p><strong>Steuerwerk</strong>: Holt/interpretiert Maschinenbefehle</p>
|
|
|
Welche Operationen beherrscht eine CPU?
|
<ul><br> <li>Lade-/Speicheroperationen</li><br> <li>Arithmetische und logische Operationen</li><br> <li>Sprünge (Änderungen des Befehlszählers): Bedingt/unbedingt, Unterprogrammaufrufe/-Rücksprünge</li><br></ul>
|
|
|
<p>Welche <em>Ausführungsmodi</em> gibt es, um direkten Zugriff auf Systemressourcen durch Anwendungsprogramme zu unterbinden?</p> gibt es, um direkten Zugriff auf Systemressourcen durch Anwendungsprogramme zu unterbinden?
|
<p><strong>Systemmodus</strong>, wobei das Programm vollen Zugriff auf alle Rechnerkomponenten hat: Für das Betriebssystem</p><p><strong>Benutzermodus</strong>, wobei der Zugriff eingeschränkt ist und Speicher nur über Adressabbildung zugänglich ist. Keine <em>privilegierten Befehle</em> wie E/A, Zugriff auf Konfigurationsregister,...</p><br><p>Ausführung eines <strong>privilegierten Befehls</strong> führt zu <em>Ausnahme</em> (Exception/Software Interrupt): Prozessor bricht ausgeführten Befehl ab, sichert PC (Adresse des Befehls) im Keller (Rückkehradresse). Programm wird an <em>vordefinierter</em> Adresse im Systemmodus fortgesetzt - d.h. Verzweigung an feste Stelle im OS. BS behandelt die Ausnahme (bspw. Abbruch des laufenden Prozesses, ggf. andere Behandlung und Rückkehr in Anwendung), Rückkehrbefehl schaltet wieder in Benutzermodus.</p><br><p><strong>Kontrollierter Moduswechsel</strong> - spezieller Befehl <em>Systemaufruf</em> (Trap/System Call). Bei Ausführung des Befehls sichert Prozessor PC im Keller (Rückkehradresse), Umschalten in Systemmodus, Verzweigung an <em>vordefinierte Adresse</em> im OS, OS analysiert Art des Systemaufrufs und führt diesen aus, Rückkehrbefehl schaltet wieder in Benutzermodus.</p><br><p><strong>Interrupts</strong>: Prozessor kann auf externe/asynchrone Ereignisse mit einem <em>Unterbrechungssignal</em> reagieren. Dieses wird jeweils nach Abarbeitung eines Befehls abgefragt. Falls Signal gesetzt: Prozessor sichert PC im Keller (Rückkehradresse), Umschalten in Systemmodus, Verzweigung an <em>vordefinierte Adresse</em> im OS (<strong>Unterbrechungsbehandlungsroutine</strong>). Im OS Behandlung der Unterbrechung, Rückkehrbefehl schaltet wieder in Benutzermodus.</p><br><p>Bei i.d.R. mehreren Interrupts mit verschiedenen Prioritäten kann jedem eine Behandlungsroutine zugewiesen werden (Tabelle von Adressen: <strong>Unterbrechungsvektor</strong>) - ggf. Unterbrechung aktiver Behandlungsroutinen. Interrupts können <strong>maskiert</strong> (ausgeschaltet) werden -> Privilegierter Befehl, wobei Programm <em>ISR</em> (Interrupt Service Routine)-Aufruf unterbindet.</p>
|
|
|
Welche Arten von <strong>Unterbrechungen des Programmablaufs</strong> gibt es?
|
<strong>Synchron</strong>: Ausnahme (<em>Exception</em>), Systemaufruf (<em>Trap</em>)<p><strong>Asynchron</strong>: <em>Interrupt</em></p>
|
|
|
<p>Wie ist die <strong>Speicherhierarchie</strong> aufgebaut?</p>
|
<p><img src="http://250kb.de/u/130320/g/KZerMPTa1ilj.gif"></p><p>Verwaltung von Haupt-/Magnetspeicher erfolgt durch das BS</p>
|
|
|
Welche Besonderheiten haben Caches in Multicoresystemen?
|
<p>i.A. Blöcke mit 32-64 Byte-Größe.</p><br><p>Für Multicoresysteme essentiell, da Cachezugriff 10-1000x schneller als Hauptspeicherzugriff, sodass Entlastung von Hauptspeicher & Bus möglich ist. Jedoch bei mehreren Kopien von Daten Problematik der Inkonsistenz: <strong>Cache-Kohärenz-Problem</strong>. Bspw. greifen 3 Prozessoren auf das selbe Speicherwort zu und erhalten dabei verschiedene Ergebnisse, sofern der Schreibzugriff auch den Hauptspeicher aktualisiert.</p>
|
|
|
Wie erfolgt die <strong>Sicherstellung der Cache-Kohärenz</strong>?
|
<p>Grundprinzip, dass bei einem Schreibzugriff alle <em>betroffenen</em> Caches (d.h. Caches mit Kopien) benachrichtigt werden.</p><br><p>Einfachste Möglichkeit <strong>Bus Snooping</strong>: Caches horchen auf Speicherbus mit - bei Schreibzugriff Invalidierung zugehöriger Cachezeile, falls Datum im Cache - Cachezeile wird beim nächsten Zugriff neu geladen.</p><br><p><strong>Ansteuerung der Geräte durch Controller</strong> mit spezieller Hardware (ggf. eigene Mikroprozessoren). Dieser steuert Gerät weitgehend autonom und verfügt über Register für Kommandos, Daten, Status. Falls Eingabedaten vorhanden oder Ausgabeoperation abgeschlossen, kann dieser Interrupt an CPU senden.</p><br><p><strong>Durch Anbindung Controller - CPU</strong>: Speicherbasierte EA -> Register des Controllers sind in Speicheradressraum eingeblendet, Zugriff über normale Lese-/Schreibbefehle, Zugriffsschutz über <em>Memory Management Unit</em>. Separater E/A-Adressraum (z.B. x86) mit Zugriff auf Controller-Register nur über spezielle (privilegierte) E/A-Befehle.</p>
|
|
|
Welche <strong>Klassen von E/A-Geräten</strong> gibt es?
|
<ul><br> <li><strong>Zeichen-orientierte Geräte</strong></li><br></ul><br><p>Ein-/Ausgabe einzelner Zeichen etwa bei Tastatur, Maus, Modem</p><br><ul><br> <li><strong>Block-orientierte Größe</strong></li><br></ul><br><p> Ein-/Ausgabe größerer Datenblöcke etwa bei Festplatte, Netzwerk - Vorteil: Reduzierung der Interrupt-Rate, welche für Programm-Geschwindigkeit wichtig ist.</p><br><div><p> </p><br></div>
|
|
|
<p>Welche <strong>Konzepte</strong> und welche <strong>orthogonalen Aufgaben</strong> haben Betriebssysteme?</p>
|
<p><strong>Konzepte</strong>: Prozesse/Threads, Speicherverwaltung, Ein-/Ausgabe, Dateiverwaltung.</p><br><br><p><strong>Orthogonale Aufgaben</strong>: Sicherheit, Ablaufplanung und Resourcenverwaltung</p>
|
|
|
Worin liegt der Unterschied zwischen <strong>Prozessen</strong> und <strong>Threads</strong>?
|
<p>Der wesentliche Unterschied ist, dass Prozesse über einen eigenen Speicherbereich verfügen, während sich alle (zum gleichen Prozess gehörenden) Threads den (Prozess-) Speicherbereich teilen.</p>
|
|
|
Worum handelt es sich bei einem <strong>Prozess</strong>?
|
<p>Um ein <em>Programm in Ausführung</em>!</p><br><p>-> Aktivitätseinheit mit Ausführungsumgebung (Adressraum aus Programmcode/Daten sowie Zustandsinformationen benutzter Ressourcen wie offene Dateien, Position der Lesezeiger) und einem oder mehreren <em>Threads</em> (Aktivitätsträgern). Klassischer Prozess enthält genau einen Thread, heute in den meisten OS mehrfädige Prozesse möglich.</p>
|
|
|
Wie funktioniert das <strong>Timesharing</strong> und was ist darunter zu verstehen?
|
<p>Threads werden abwechselnd von Prozessoren bearbeitet, wobei das OS entschiedet, wer wie lange auf welchem Prozessor rechnen darf.</p><br><p>Gründe: Bedürfnisse des Nutzers (mehrere Anwendungen) sowie bessere Auslastung des Rechners.</p><br><p><em>Prozesswechsel</em> bedingt Wechsel der Ausführungsumgebung. Threads teilen sich die Ausführungsumgebung - Wechsel zwischen Threads desselben Prozesses ist effizienter.</p>
|
|
|
<p>Wie sieht ein <strong>virtueller Adressraum</strong> aus und was enthält er?</p>
|
<img src="http://250kb.de/u/130320/g/ohd1XSNJl3cV.gif" /><br><p>Beginnt bei Adresse 0, durchnummeriert bis Obergrenze - <em>linearer Adressraum</em></p><br><p>Abstraktion des physischen Speichers unabhängig von Größe/Technologie dessen.</p>
|
|
|
Welchen Daten gehören zum <strong>Ausführungskontext</strong>?
|
<p>Alle sonstigen, welche zur Ausführung gebraucht werden:</p><br><p>-> Prozessorstatus (Datenregister, PC, PSW,...)</p><br><p>-> BS-relevante Daten (Eigentümer, Priorität, Eltern-Prozess, genutzte Betriebsmittel)</p><br><p>Aufgeteilt in Prozess-/Threadkontext</p><br><p>Speicherung des Ausführungskontextes: Im Adressraum <em>Prozess-</em> bzw. <em>Threadtabelle</em> oder alternativ (geschützter) Teil des Prozessadressraums.</p>
|
|
|
Woraus besteht die Prozessinteraktion (IPC) und welches Problem tritt dabei auf?
|
<strong>Kommunikation</strong>: Durch Verwendung eines gemeinsamen Adressraums zwischen Threads eines Prozesses (<em>Speicherkopplung</em>) bzw. durch explizites Senden/Empfangen Nachrichten zwischen Prozessen (<em>Nachrichtenkopplung</em>)<p><strong>Synchronisation</strong>: Steuerung der zeitlichen Aktivitätsreihenfolge (idR Zugriff auf gemeinsame Ressourcen). Problem: <em>Verklemmungen</em> (Deadlocks) -> zyklische Wartebeziehungen</p>
|
|
|
Welche Probleme treten für das Betriebssystem durch die <em>Speicherverwaltung</em> auf?
|
<p>Zuteilung von Speicherbereichen an Prozesse: OS muss ausreichend großen Speicher finden - doch was, wenn laufender Prozess mehr Speicher anfordert?</p><br><p>Programme enthalten Adressen - kann man Programm dabei an beliebige Adresse schieben?</p><br><p>Prozesse werden gegenseitig geschützt - wie kann dabei verhindert werden, dass ein Prozess auf den Speicher eines Drittprozesses oder des OS zugreift?</p><br><p>Hauptspeicher ist begrenzt - was passiert, wenn nicht alle Prozesse in den Hauptspeicher passen?</p><br><p>Transparenz für Anwendungen, welche idR annehmen dürfen, den Rechner für sich alleine zu haben - Programmieraufwand sollte sich durch Speicherverwaltung nicht erhöhen.</p><br><p><strong>Lösung</strong>: Adressabbildung: Virtuelle Adresse werden durch MMU auf Speicheradressen (physisch!) umgesetzt. Einfachster Fall: Addition Basis-Adresse und Limit.</p><br><p>Weiterer Vorteil: Adressraum kann auf Haupt-/Hintergrundspeicher aufgeteilt werden.</p><br><img src="http://250kb.de/u/121212/g/Mp08oXu60ezT.gif" />
|
|
|
Wie sind <strong>Dateien</strong> strukturiert und welche Typen gibt es?
|
<p>Datei = Einheit zur Speicherung von Daten -> <em>persistente Speicherung</em> über das Ende von Prozessen hinaus.</p><br><p><strong>Struktur</strong>: Bei heutigen PC-/Server-Betriebssystemen unstrukturierte Folge von Bytes, die das OS nicht kennt. Bei <em>Mainframe-OS</em>: Sequenz von Datensätzen fester Struktur, Index zum schnellen Zugriff auf Datensätze.</p><br><p><strong>Typen</strong>: Reguläre Dateien, Verzeichnisse, Gerätedateien [falls Geräte in Dateisystemen abgebildet sind]</p>
|
|
|
Welche <strong>Dateioperationen</strong> gibt es?
|
Öffnen<p>Schließen</p><br><p>Lesen/Schreiben: Meist sequentiell (historisch bedingt), auch wahlfreier Zugriff möglich (Offset bei R/W oder explizites <em>seek</em>-Positionieren). Alternative: Einblenden in den Prozess-Adressraum</p><br><p>Erzeugen, Löschen, Umbenennen</p><br><p>Lesen/Schreiben von Dateiattributen (z.B. Zugriffsrechte)</p>
|
|
|
Wie ist das <strong>sequentielle Dateimodell</strong> aufgebaut?
|
<p>Datei als unstrukturierte Byte-Folge</p><br><p>Nach Öffnen einer Datei besitzt Prozess einen privaten <em>Dateizeiger</em> mit nächstem zu lesenden Byte bzw. Schreibposition</p><br><p>R/W-Operationen kopieren Datenblock zwischen Hauptspeicher/Datei -> Dateizeiger wird entsprechend weitergeschoben</p><br><p>Lesen über Dateiende hinaus (<em>end-of-file</em>) ist nicht möglich</p><br><p>Schreiben über Dateiende führt zum Anfügen an Datei</p><br><p>Dateizeiger kann auch explizit positioniert werden</p>
|
|
|
Wie sind <strong>Verzeichnisse</strong> aufgebaut?
|
<p>Zur hierarchischen Organisation - Benennung von Dateien über Pfadnamen</p><br><p><em>Absolute</em> Pfadnamen beginnend am Wurzelnverzeichnis (/home/wismueller/Vorlesungen/BS1/v02.pdf) vs.</p><br><p><em>Relative</em> Pfadnamen, beginnend beim aktuellen Arbeitsverzeichnis. D.h. BS1/vf02.pdf, sofern aktuelles Verzeichnis /home/wismueller/Vorlesungen</p><br><p>Oft Einführung von<em> Links</em> - somit Datei/Verzeichnis mehr als einmal in Verzeichnis vorhanden, jedoch nur einmal physisch existent. Links sind dabei i.d.R. transparent für Anwendungen.</p>
|
|
|
Welches sind typische <strong>Aufgaben/Konzepte von Betriebssystemen</strong>?
|
- Realisierung von Dateien/Verzeichnishierarchien: Abbildung von Dateien/Verzeichnis auf Speichermedien<p>- Realisierung der Dateioperationen - dabei Überprüfung von Zugriffsrechten</p><br><p>- Einhängen von Dateisystemen in Verzeichnishierarchie bei einheitlicher Sicht auf alle Dateisysteme</p><br><p>- Spezialdateien (Gerätedateien, Pipes, Prozessdateisysteme)</p>
|
|
|
Welche <strong>Sicherheitsaufgaben</strong> gibt es (unter Linux)?
|
- Einführung Benutzer/Benutzergruppen sowie spezieller Benutzer <em>root</em><p>- Prozesse/Dateien haben Eigentümer(-gruppe)</p><br><p>- Zugriff auf Prozesse nur für Eigentümer/root</p><br><p>- Zugriff auf Dateien über 9 Rechtebits (rwx für user/group/others)</p><br><p>- Rechte werden bei jedem relevanten Zugriff durch OS geprüft</p>
|
|
|
Welche Aufgaben gibt es bzgl. der <strong>Ressourcen-Verwendung</strong> und welche <strong>Ziele</strong> sind dabei anzustreben?
|
<p>Ziele: <em>Fairness, Differenzierung (Anforderungen v. Job-Klassen berücksichtigen), Effizienz</em></p><br><p>Aufgaben bei Verwendung/Planung der Verwendung:</p><br><p>Hauptspeicher -> Welcher Prozess erhält wann wo wie viel Speicher und wie wird dieser ausgelagert?</p><br><p>Platten-E/A -> Optimierung der Armbewegung</p>
|
|
|
Was geschieht bei einem <strong>Systemaufruf</strong>?
|
<p>Schnittstelle zwischen Benutzerprogrammen/OS:</p><br><p>Systemaufrufe i.d.R. in Bibliotheksfunktion gekapselt - Details sind hardwareabhängig.</p><br><p>I.d.R.: Systemaufrufe durchnummeriert, Nummer wird vor Ausführung des <em>Trap-Befehls</em> in festes Register geschrieben. In OS dann Verzweigung über Funktionstabelle:</p><br><p>OS sichert zunächst vollständigen Prozessorstatus</p><br><p>Aufrufender Thread/Prozess kann blockiert werden (bspw. Warten auf Eingabe)</p><br><p>Rückkehr aus OS über Scheduler -> bestimmt über Thread, der weitergeführt wird - daher nicht unbedingt zum aufrufenden Thread</p><br><p>Bei Rückkehr Restaurieren des Prozessorstatus des weitergeführten Threads</p>
|
|
|
Welches sind <strong>typische System-(<em>trap-</em>)Aufrufe</strong> unter Linux?
|
<p><strong>Prozessmanagement</strong>: fork, waitpid (Warten auf Ende eines Kindprozesses), execve (Ausführen eines anderen Programms), exit (Prozess beenden und Statuswert zurückgeben)</p><br><p><strong>Dateimanagement</strong>: open, close, read, write, lseek (Dateizeiger verschieben)</p><br><p><strong>Verzeichnismanagement</strong>: mkdir, rmdir, unlink (Datei löschen), mount</p><br><p>chdir, chmod (Dateizugriffsrechte ändern), kill, time</p>
|
|
|
<p>Was ist ein <strong>Prozess</strong> und wie lautet das Konzept dahinter?</p>
|
<p>Prozess = Programm in Ausführung.</p><br><p><strong>Konzeptuell</strong> jeder Prozess durch eigene, virtuelle CPU ausgeführt - daher <em>nebenläufige</em>, d.h. quasi-parallele Abarbeitung der Prozesse, wobei jeder über einen eigenen (virtuellen) Adressraum (Speicher) verfügt.</p><br><p><strong>Real</strong> schaltet CPU zwischen den Prozessen hin- und her: <em>Multiprogrammierung</em>/<em>Mehrprogrammbetrieb</em>. Umschalten durch Umladen der CPU-Register (inkl. PC). Annahmen über Geschwindigkeit der Ausführung sind nicht zulässig.</p><br><img src="http://250kb.de/u/121217/g/uxFORyxjwt4h.gif" />
|
|
|
Welche <strong>Aspekte</strong> sind bei <strong>klassischen Prozessen</strong> von Bedeutung?
|
<strong>Einheit des Ressourcenbesitzes</strong> sowie <strong>der Ablaufplanung/Ausführung</strong><p><em>Ressourcenbesitz</em>: Eigener (virtueller) Adressraum, Besitz/Kontrolle von Ressourcen, Schutzfunktion durch OS</p><br><p><em>Ablaufplanung</em>: Ausführung folgt einem Weg (<em>Trace</em>) durch das Programm - verzahnt mit Ausführung anderer Prozesse, wobei OS über CPU-Zuteilung entscheidet.</p>
|
|
|
Welche <strong>Aspekte</strong> sind bei <strong>heutigen Betriebssystemen von Bedeutung</strong>?
|
<p>Aufteilung <strong>Prozess</strong> (Einheit Ressourcenbesitz/Schutz) und <strong>Thread</strong> (Einheit Ausführung/Prozessorzuteilung -> Ausführungsfaden, leichgewichtiger Prozess).</p><br><p>Somit mehrere Threads innerhalb von Prozessen möglich, sodass Anwendungen <em>nebenläufige Aktivitäten</em> besitzen können.</p><br><p><strong>Vorteil des Multithreading</strong>: Nebenläufige Programmierung möglich (mehrere Kontrollflüsse), bei Warten auf E/A können andere weiterarbeiten, kürzere Reaktionszeit auf Benutzereingaben, bei Multicore echte parallele Abarbeitung möglich.</p>
|
|
|
Welche 2 <strong>Arten der E/A-Verwaltung</strong> existieren?
|
<strong>Interrupts</strong>: Geringe Wartezeit - direkt nach Auftreten des Ereignisses. Nachteil des Mehraufwandes, da Kontextwechsel notwendig wird und Interrupts auf Pipeline, TLB und Cache Einfluss haben.<p><strong>Polling</strong>: Anwendungen fragen ständig ab, ob das erwartete Ereignis eingetroffen ist, wodurch Interrupts vermieden werden, jedoch zusätzlich Wartezeit entsteht, da ein Ereignis oft nach Abfrage der Anwendung eintreten kann und dann ein ganzes Polling-Intervall abzuwarten ist.</p>
|
|
|
Welche Vor-/Nachteile bieten <strong>nebenläufige Programme</strong>?
|
<p><strong>Vorteil</strong>: Einfachere Programmstruktur</p><br><p><strong>Nachteil</strong>: Zugriff auf gemeinsame Variable erfordert Synchronisation</p>
|
|
|
Wie erfolgt die <strong>Realisierung von Threads</strong> konzeptuell bzw. real?
|
<strong>Konzeptuell</strong>: Jeder Thread wird durch eigene, virtuelle CPU ausgeführt -> nebenläufige/quasi-parallele Abarbeitung von Threads. Nutzt alle anderen Ressourcen des Prozesses gemeinsam mit dessen anderen Threads.<p><strong>Real</strong>: CPU schaltet zwischen Threads hin- und her: <em>Multithreading</em>. Umschaltung durch Umladen der CPU-Register.</p><br><img src="http://250kb.de/u/121217/g/fIOwTnQDVVpK.gif" />
|
|
|
Wie sieht ein <strong>Zustandsgraph</strong> für ein erweitertes Thread-/Prozess-Modell aus?
|
<img src="http://250kb.de/u/121221/g/cJCgDkCMt66k.gif" />
|
|
|
Wie sieht eine <strong>Warteschlange für alle blockierten Threads</strong> bzw. <strong>pro Ereignis</strong> aus?
|
<p> </p><br><img src="http://250kb.de/u/121221/g/6END9i1kUj44.gif" /><br><img src="http://250kb.de/u/121221/g/7FgLQ8Pp4Uue.gif" />
|
|
|
Welche <strong>Gründe</strong> gibt es für die <strong>Prozesserzeugung</strong>?
|
- Initialisierung des Systems: Hintergrundprozesse (<em>Daemons</em>) für OS-Dienste<p>- Benutzeranfrage: Interaktive Anmeldung, Start eines Programms</p><br><p>- Erzeugung durch Systemaufruf eines bestehenden Prozesses</p><br><p>- Initiierung von <em>Batch-Jobs</em> in Mainframe-OS</p><br><p>- Technisch wird neuer Prozess i.d.R. durch Systemaufruf (z.B. <em>fork</em>/<em>CreateProcess</em>) erzeugt -> <em>Prozesshierarchie</em>!</p><br><img src="http://250kb.de/u/121222/g/C5o9Wf35ORzn.gif" />
|
|
|
Welche <strong>Gründe für Prozessterminierungen</strong> gibt es?
|
<strong>Freiwillig</strong>: Durch Aufruf von z.B. <em>exit</em> bzw. <em>ExitProcess</em>. Normal oder wegen Fehler.<p><strong>Unfreiwillig</strong> (Abbruch durch OS): Wegen schwerwiegender Fehler (Speicherüberschreitung, Ausnahme, E/A-Fehler, Schutzverletzung), durch andere [berechtigte] Prozesse via Systemaufruf (<em>kill</em> bzw. <em>TerminateProcess</em>) oder teilweise ist noch eine Reaktion des Prozesses auf Ereignis möglich.</p>
|
|
|
Wie funktioniert die <strong>Implementierung von Prozessen/Threads</strong>?
|
- OS pflegt <strong>Prozess-/Threadtabelle</strong> mit Informationen - einzelner Eintrag heißt <em>Prozess-/Threadkontrollblock</em><p><em>- </em><strong>Prozessadressraum, Prozesskontrollblock</strong> und <em>Threadkontrollblöcke</em> beschreiben einen Prozess vollständig.</p><br><p>Elemente eines <strong>PKB</strong>: Prozessidentifikation (Kennung Prozess/Elternprozess), Zustands-/Ressourceninformation (Priorität, verbrauchte CPU-Zeit), Verwaltungsinformation (Daten für IPC, Prozessprivilegien, Tabelle für Speicherabbildung, Ressourcenbesitz/-nutzung)</p><br><p>Elemente eines <strong>TKB</strong>: Threadidentifikation (Kennung Thread/zug. Prozesse), Scheduling-/Zustandsinformationen (Threadzustand, ggf. abzuwartendes Ereignis, Priorität, CPU-Zeit), Prozessorstatus-Informationen (Datenregister, Steuer-/Statusregister [PC, PSW], Kellerzeiger [SP]).</p>
|
|
|
Wie läuft eine <strong>Prozesserzeugung</strong> ab?
|
- Eintrag mit Kennung in Prozesstabelle erzeugen<p>- Zuteilung von Speicherplatz an Prozess (für Programmcode, Daten, Keller)</p><br><p>- Initialisierung des Prozesskontrollblocks -> Ressourcen evtl. von Elternprozess geerbt</p><br><p>- Erzeugung und Initialisierung eines Threadkontrollblocks: PC/SP und alle anderen Register, Threadzustand: bereit, Prozess startet mit genau einem Thread</p><br><p>- Einhängen des Threads in Bereit-Warteschlange</p>
|
|
|
<p>Wie läuft ein <strong>Threadwechsel</strong> ab?</p>
|
<ol><br> <li>Prozessorstatus im Threadkontrollblock sichern (PC, PSW, SP, andere Register)</li><br> <li>Thread-/Prozesskontrollblock aktualisieren (Zustand, Grund der Deaktivierung, Buchhaltung)</li><br> <li>Thread in entsprechende Warteschlange einreihen</li><br> <li>Nächsten bereiten Thread auswählen (Scheduling!)</li><br> <li>Threadkontrollblock des neuen Threads aktualisieren (Zustand auf <em>rechnend</em> setzen)</li><br> <li>Falls neuer Thread in anderem Prozess -> Aktualisierung der Speicherverwaltungsstrukturen</li><br> <li>Prozessorstatus aus neuem Threadkontrollblock laden</li><br></ol>
|
|
|
Wann <strong>erfolgt ein Threadwechsel</strong>?
|
<p>Bei Systemaufruf (z.B. E/A -> Thread gibt Prozessor freiwillig ab)</p><br><p>Bei Ausnahme</p><br><p>Bei Interrupt (z.B. E/A-Gerät, Timer -> Behandlung erfolgt in BS, periodischer Timer stellt sicher, dass kein Thread CPU monopolisieren kann)</p>
|
|
|
Wie läuft ein <strong>Systemaufruf</strong> ab?
|
<p>Hardware-Einsprung in OS (Systemmodus), dann:</p><br><p>Sichern des OS-Status</p><br><p>Thread <em>bereit</em> setzen</p><br><p>Ausführung/Initiierung des Auftrags (evtl. <em>blockiert</em> setzen)</p><br><p>Sprung zum Scheduler (Aktivierung anderen Threads, dieser wird nach Rückkehr in Benutzermodus fortgesetzt)</p>
|
|
|
Wie läuft eine <strong>Ausnahme</strong> ab?
|
<p>Hardware-Einsprung in OS (Systemmodus), dann:</p><br><p>Sichern des gesamten Prozessorstatus</p><br><p>je nach Ausnahme: <em>Beenden, Blockieren</em> (z.B. Seitenfehler -> dyn. Seitenersetzung) oder <em>Behebung der Ausnahmenursache</em></p><br><p>Sprung zum Scheduler</p>
|
|
|
Wie läuft ein <strong>Interrupt</strong> ab?
|
<p>Hardware-Einsprung in OS (Systemmodus), dann:</p><br><p>Sichern des gesamten Prozessorstatus</p><br><p>Aktuellen Thread auf <em>bereit</em></p><br><p>Ursache der Unterbrechung ermitteln</p><br><p>Ereignis (bspw. Ende der E/A) behandeln</p><br><p>evtl. blockierte Threads <em>bereit</em> setzen</p><br><p>Sprung zum Schedular</p>
|
|
|
Welche <strong>Realisierungsvarianten</strong> gibt es für Threads?
|
<strong>BS-Kern</strong>: Bei Blockierung kann OS anderen Thread desselben Prozesses auswählen, bei Multicore echte Parallelität innerhalb eines Prozesses. Nachteil des hohen Overheads (Threadwechsel benötigt Moduswechsel in Kern, Erzeugen/Beenden/usw. benötigt Systemaufruf)<p><strong>Benutzeradressraum</strong>: Keine OS-Unterstützung nötig, schnelle Threaderzeugung/-wechsel, individuelle Scheduling-Algorithmen. Jedoch durch Systemaufruf -> Threadblockierung. Threads müssen Prozessor i.d.R. freiwillig durch Bibliotheksfunktion abgeben.</p><br><p><strong>Hybride Realisierung</strong>: In alten Versionen von Solaris, heute für Programme mit vielen nebenläufigen Aktivitäten.</p>
|
|
|
Welche <strong>Schnittstellen zur Threadnutzung</strong> werden heute i.d.R. verwendet?
|
<p>Höherer Programmierschnittstellen anstatt Systemaufrufen, bspw. POSIX Threads (Programmierbibliothek, OS-unabhängig -> bei Programmstart ein Master-Thread, welcher andere Threads erzeugt und auf deren Beendigung) oder</p><br><p>Java-Threads (Sprachkonstrukt -> Grundlage Klasse Thread, Konstruktor <em>Thread()</em>, Methoden <em>void start()</em>, <em>void join()</em> ...).</p>
|
|
|
<p>Wie funktionieren <strong>POSIX Threads</strong> und welche Funktionen sind enthalten?</p>
|
<p>Bei Programmstart ein (Master-)Thread, welcher andere Threads erzeugt und auf deren Beendigung wartet. Prozess terminiert bei Beendigung des Master-Threads.</p><br><p>Funktionen zur Threadverwaltung u.a.:</p><br><p><strong>pthread_create</strong> (Parameter: Prozedur, die der Thread abarbeiten soll, Ergebnis Thread-Handle=Referenz)</p><br><p><strong>pthread_exit</strong> Eigene Terminierung</p><br><p><strong>pthread_cancel</strong> Terminierung anderen Threads</p><br><p><strong>pthread_join</strong> Warten auf Terminierung eines anderen Threads, liefert Ergebniswert</p>
|
|
|
Wie funktionieren <strong>Java Threads</strong> und wie werden diese definiert?
|
<p>Grundlage ist die Klasse <em>Thread</em> mit entsprechenden Konstuktoren/Methoden:</p><br><p>Thread(), Thread(Runnable target)</p><br><p>void start() <em>Startet einen Thread</em></p><br><p>void join() <em>Wartet auf Ende des Threads</em></p><br><p>Definition über Deklaration neuer Klasse als Unterklasse von [Thread] oder als Implementierung der Schnittstelle [Runnable]. Überschreiben/Implementieren der Methode <em>void run()</em> mit auszuführendem Code.</p>
|
|
|
Wie läuft die <strong>Nutzung gemeinsamer Ressourcen</strong> bei <strong>Threads</strong> ab?
|
<p>Threads kennen einander nicht, nutzen gemeinsame Ressourcen (Dateien, Geräte,...) <strong>unbewusst</strong> (Wettstreit) oder <strong>bewusst</strong> (Kooperation durch Teilen) -> Synchronisation</p><br><p>Threads kennen sich (ihre Prozess-/Threadkennungen): Kooperation durch Kommunikation</p>
|
|
|
Was geschieht beim <strong>Race Condition</strong>-Problem?
|
<p>Prozess A liest in aus und speichert Wert 7 in lokaler Variable <em>next_free_slot</em>. Genau dann tritt eine Unterbrechung durch die Uhr auf und die CPU entscheidet, dass Prozess A lange genug lief, sodass Wechsel zu B erfolgt. B liest ebenfalls <em>in</em> aus und bekommt auch eine 7, speichert sie in <em>seiner</em> lokalen Variable <em>next_free_slot</em>, sodass beide Prozesse glauben, dass der nächste verfügbare Eintrag 7 ist.</p><br><p>B speichert Namen seiner Datei in Eintrag 7 und aktualisiert <em>in</em> auf 8. A läuft an vorheriger Stelle, findet für <em>in</em> eine 7 und schreibt seinen Dateinamen in 7. Eintrag, wobei der Eintrag von B gelöscht wird und A auf 8 gesetzt wird. B wartet nun ewig auf eine Ausgabe, die nie kommen wird.</p><br><p>Nötig ist ein Verbot, gleichzeitig mit einem anderen Prozess gemeinsam genutzte Daten zu lesen oder zu schreiben -> <strong>wechselseitiger Ausschluss</strong></p>
|
|
|
Welche <strong>Arten der Synchronisation</strong> gibt es und wie lauten ihre Merkmale?
|
<strong>Sperrsynchronisation</strong> stellt sicher, dass Aktivitäten verschiedener Threads <em>nicht gleichzeiti</em><em>g</em>, sondern nacheinander ausgeführt werden.<p><strong>Reihenfolgesynchronisation</strong> stellt sicher, dass Aktivitäten in verschiedenen Threads in <em>bestimmter Reihenfolge</em> ausgeführt werden (Erst Datei erzeugen, dann lesen)</p><br><p>Gesucht wird eine Methode zu wechselseitigem Ausschluss kritischer Abschnitte.</p>
|
|
|
Welche <strong>Anforderungen</strong> gibt es an Lösungen zum <strong>Wechselseitigen Ausschluss</strong>?
|
<ol><br> <li>Max. 1 Thread in kritischem Abschnitt</li><br> <li>Keine Annahmen über Geschwindigkeit/Anzahl CPUs</li><br> <li>Thread von außerhalb darf andere nicht behindern</li><br> <li>Kein Thread darf ewig warten müssen (-> kein Thread darf ewig belegen)</li><br> <li>Sofortiger Zugang zu kritischem Abschnitt, wenn kein anderer Thread diesen belegt,</li><br></ol>
|
|
|
Welche <strong>Lösungsversuche</strong> des <strong>wechselseitigen Ausschlusses</strong> gibt es?
|
<strong>Sperren des Interrupts</strong>: Abgesehen von freiwilliger Abgabe durch CPU nur Threadwechsel bei Interrupt - Sperrung/Freigabe durch begin_region() / end_region(). Problem: E/A ist blockiert, OS verliert Threadkontrolle, nur bei Single-Core möglich.<p><strong>Sperrvariable</strong>: Variable zeigt, ob kritischer Abschnitt belegt -> while(belegt) belegt=true [...] belegt = false. Problem: Race Condition.</p><br><p><strong>Strikter Wechsel</strong>: Variable <em>turn</em> gibt an, wer an der Reihe ist -> while (turn!=0) [kA] turn=1;. Problem: Threads müssen abwechselnd in kA</p><br><p><strong>Erst belegen, dann prüfen</strong> Variable [i] zeigt an, ob <em>i</em> in kA will: interested[0]=true -> while (interested[1]); ... [kA] ... interested[0]=false; Problem der Verklemmung, falls Threads gleichzeitig auf true setzen</p><br><p><strong>Peterson-Algorithmus</strong> Kombination An-die-Reihe-nehmen & Sperrvariablen: Bevor gemeinsam genutzte Variablen verwendet werden, ruft jeder Prozess interested mit eigener Prozessnummer als Paramerter auf. Nachdem gemeinsam genutzte Variable fertig ist, ruft der Prozess leave_region auf. Verklemmung durch <em>turn</em> verhindert, jeder Thread bekommt Chance auf kritischen Bereich <em>ohne Verklemmung</em>!</p>
|
|
|
Welche <strong>Nachteile </strong>gibt es beim Aktiven Warten<strong> </strong>(<strong>Spinlock</strong>)?
|
<p>Thread belegt CPU während des Wartens, zudem sind bei Einprozessorsystemen und Threads mit Prioritäten Verklemmungen möglich:</p><br><p><span style="color: rgb(119, 119, 119);">Thread H hat höhere Priorität als L, ist aber blockiert-> L rechnet, wird in kritischem Abschnitt unterbrochen; H wird rechenbereit -> H will in kritischen Abschnitt, wartet auf L; L kommt nicht zum Zug, solange H rechenbereit ist</span></p>
|
|
|
Was ist ein <strong>Semaphor</strong> und aus welchen atomaren Operationen besteht er?
|
<p>Allgemeines Synchronisationskonstrukt - nicht nur wechselseitiger Ausschluss, sondern auch Reihenfolgesynchronisation mit <strong>atomaren Operationen</strong></p><br><p>P() -> alias <em>wait</em>, <em>down</em> oder <em>acquire</em> verringert Wert um 1, falls Wert <0: Thread blockierne</p><br><p>V() -> alias <em>signal</em>, <em>up</em> oder <em>release</em> erhöht Wert um 1, falls <=0 blockierten Thread wecken.</p><br><p>Zähler >=0: Anzahl freier Ressourcen</p><br><p>Zähler <0: Anzahl wartender Threads</p>
|
|
|
Welche Situation beschreibt das <strong>Erzeuger/Verbraucher-Problem</strong> und wie wird sie behoben?
|
<p>Zwei Prozesse benutzen einen gemeinsamen allgemeinen Puffer. Der Erzeuger legt Informationen in den Puffer, der Verbraucher nimmt sie heraus. Ein Problem entsteht, wenn der Erzeuger eine neue Nachricht in den Puffer legen möchte, dieser aber bereits voll ist. Die Lösung besteht darin, den Erzeuger schlafen zu legen und wieder aufzuwecken, wenn der Verbraucher eine oder mehrere Nachrichten entfernt hat. Gleichsam geht der Verbraucher schlafen, wenn er eine Nachricht aus dem Puffer entfernen möchte und einen leeren Puffer vorfindet - bis der Erzeuger etwas in den Puffer legt und ihn aufweckt.</p><br><p>Die Operation verwendet 3 Semaphore: <em>full</em>, um Einträge zu zählen, die belegt sind, <em>empty</em>, um leere Einträge zu zählen und <em>mutex</em>, um sicherzustellen, dass Erzeuger und Verbraucher nicht gleichzeitig auf den Puffer zugreifen.</p>
|
|
|
Worum geht es beim <strong>Leser/Schreiber-Problem</strong> und wie wird dieses gelöst?
|
<p>Entspricht der Problematik eines Reservierungssystems bei einer Fluggesellschaft mit vielen konkurrierenden Prozessen, welche Lese-/Schreibrechte wünschen. Hier ist es akzeptabel, dass mehrere Prozesse gleichzeitig die Datenbank auslesen, aber wenn ein Prozess die Datenbank aktualisiert (beschreibt), darf kein anderer Prozess auf die Datenbank zugreifen - auch nicht zum Lesen, um inkonsistente Daten zu vermeiden.</p><br><p>Zur Lösung führt der erste Leser, der Zugriff auf die Datenbank bekommt, ein <em>down</em> auf Semaphor db aus. Nachfolgende Leser erhöhen den Zähler <em>rc</em>. Sind die Leser fertig, erniedrigen sie den Zähler und der Letzte führt ein <em>up</em> auf das Semaphor aus.</p>
|
|
|
Wie funktionieren <strong>Monitore</strong>?
|
<p>Sammlung von Variablen, Prozeduren und Datenstrukturen - Zugriff auf Daten dabei nur über Monitor-Prozesse. Prozeduren stehen jeweils unter wechselseitigem Ausschluss, sodass jeweils nur ein Thread den Monitor benutzen kann. Zudem kann jeweils nur ein Monitor aktiv sein. Wenn ein Prozess eine Monitor-Prozedur aufruft, prüfen die ersten Anweisungen der Prozedur, ob ein anderer Prozess gerade im Monitor aktiv ist - falls ja, wird der aufrufende Prozess eingestellt, bis der andere Prozess den Monitor verlassen hat. Falls kein anderer Prozess den Monitor benutzt, darf der aufrufende Prozess eintreten.</p><br><p>Programmiersprachenkonstrukt -> Realisierung durch Übersetzer mit <strong>2 Zustandsvariablen </strong><em>wait()</em> und <em>signal()</em>. Wenn eine Monitor-Prozedur entdeckt, dass sie nicht weitermachen kann (Erzeuger sieht, dass Puffer voll ist), führt sie ein <em>wait</em> auf eine Zustandsvariable <em>full</em> aus. Dadurch blockiert der aufzurufende Prozess. Dieser andere Prozess (Verbraucher) kann schlafenden Partner wecken, indem er ein <em>signal</em> an die Zustandvariable schickt, auf die der Partner wartet. 2 Varianten: Signalisierender Thread bleibt in Besitz des Monitors <em>oder</em> geweckter Thread erhält Monitor sofort</p><br><p>Alternative <strong>Broadcast-Signalisierung</strong>, sodass alle Threads bei unterschiedlichen Wartebedingungen geweckt werden. Nachteil, dass viele Threads um Wiedereintritt in Monitor konkurrieren.</p>
|
|
|
Wie funktioniert die <strong>Synchronisation mit Java</strong>?
|
Über Monitor-ähnliche Konstrukte -> Klassen statt Module.<p>Synchronisierte Methoden, welche explizit als <em>synchronized</em> deklariert werden müssen und pro Objekt unter wechselseitigem Ausschluss stehen. Keine explizite Bedingungsvariablen, stattdessen genau eine implizite Bedingungsvariable pro Objekt.</p><br><p>Basisklasse <em>Object</em> definiert Methoden <em>wait()</em>, <em>notify()</em> und <em>notifyAll()</em>, welche von allen Klassen geerbt werden.</p>
|
|
|
Wie funktioniert die Klasse <strong>Semaphore</strong> in Java?
|
<p>Konstruktor <em><font color="#777777">Semaphore(int wert)</font></em> erzeugt Semaphor mit angegebenem Initialwert. Wichtigste Methoden:</p><br><p><font color="#777777">void acquire()</font> entspricht P-Operation</p><br><p><font color="#777777">void release()</font> entspricht V-Operation</p>
|
|
|
Wie funktioniert die <strong>Schnittstelle Lock unter Java</strong>?
|
<font color="#777777">void lock()</font> Sperren - entspricht P bei binärem Semaphor<p><font color="#777777">void unlock()</font> Freigeben - entspricht V bei binärem Semaphor</p><br><p><font color="#777777">Condition newCondition()</font> Erzeugt neue Bedingungsvariable, die an dieses <em>Lock</em>-Objekt gebunden ist. Beim Warten an der Bedingungsvariable wird dieses Lock freigegeben.</p><br><p><font color="#777777">ReentrantLock</font> Klasse, deren neu erzeugte Sperre zunächst frei ist</p>
|
|
|
Welches sind die Operatoren der <strong>Schnittstelle Condition</strong> in Java?
|
<font color="#777777">void await()</font> Warten auf Signalisierung - Thread wird blockiert, zu <em>Condition</em> gehöriges <em>Lock</em> wird freigegeben. Nach Signalisierung kehrt <em>await</em> erst zurück, wenn <em>Lock</em> wieder erfolgreich gesperrt ist.<p><font color="#777777">void signal()</font> Signalisierung eines wartenden Threads</p><br><p><font color="#777777">void signalAll()</font> Signalisierung aller wartenden Threads</p>
|
|
|
Welche <strong>Methoden zur Kommunikation</strong> gibt es?
|
<strong>Speicherbasierte Kommunikation</strong> über gemeinsame Speicher (s. Erzeuger/Verbraucher-Problem) - i.d.R. zwischen Threads desselben Prozesses. Gemeinsamer Speicher dabei auch zwischen Prozessen möglich, Synchronisation muss explizit programmiert werden.<p><strong>Nachrichtenbasierte Kommunikation</strong> Senden/Empfangen von Nachrichten über das OS i.d.R. zwischen Threads verschiedener Prozesse auch über Rechnergrenzen hinweg bei impliziter Synchronisation.</p><br><p>send(Ziel, Nachricht)</p><br><p>receive(Quelle,Nachricht)</p><br><p>Oft spezieller Parameterwert für belibige Quelle, evtl. Quelle auch als Rückgabewert.</p><br><p>Implizite Synchronisation: Empfang einer Nachricht erst <span style="text-decoration: underline;">nach</span> dem Senden möglich - <em>receive</em> blockiert, bis Nachricht vorhanden ist.</p>
|
|
|
Wie äußert sich die <strong>Erzeuger/Verbraucher-Kommunikation</strong> mit Nachrichten?
|
OS puffert Nachrichten bis zum Anschlag, wobei die Puffergröße vom OS bestimmt wird (und meist konfigurierbar ist). Ist der Puffer voll, wird Sender in <em>send()</em>-Operation blockiert (Flusskontrolle).
|
|
|
Worin unterscheiden sich <strong>elementaren Kommunikationsmodelle</strong>?
|
<strong>Zeitliche Kopplung der Kommunikationspartner</strong>: Synchron vs. asynchron, blockierend vs. nicht-blockierend, wird Sender bis Nachrichtenempfang blockiert<p><strong>Muster des Informationsflusses</strong>: Meldung vs. Auftrag, Einweg-Nachricht oder Auftragserteilung mit Ergebnis?</p>
|
|
|
Worin unterscheiden sich <strong>asynchrone</strong> und <strong>synchrone Meldung/Auftrag</strong>?
|
<p>Sender wird (nicht) mit Empfänger synchronisiert.</p><br><p><strong>Asynchrone Meldung</strong>: Kommunikationssystem (OS) muss Nachricht ggf. Puffern, falls Empfänger (noch) nicht auf Nachricht wartet.</p><br><p><strong>Synchrone Meldung</strong>: Rendezvous-Technik: Sender wird blockiert, bis ACK erfolgt - keine Pufferung erforderlich.</p><br><p><strong>Synchroner Auftrag</strong>: Empfänger sendet ACK, Sender wird blockiert, bis Resultat vorliegt</p><br><p><strong>Asynchroner Auftrag</strong>: Sender kann mehrere Aufträge gleichzeitig erstellen -> Parallelverarbeitung möglich.</p>
|
|
|
Welche <strong>Formen der Adressierung</strong> von Sender/Empfänger gibt es?
|
<strong>Direkte Adressierung</strong> mit Kennung des jeweiligen Prozesses<p><strong>Indirekte Adressierung</strong> Nachrichten werden an Wartschlangen-Objekt (<strong>Mailbox</strong>) gesendet und von dort gelesen - höhere Flexibilität, da Mailbox von mehreren Prozessen gleichzeitig gelesen werden kann. Ausnahme <strong>Port</strong>: Mailbox mit nur einem möglichen Empfängerprozess.</p><br><p>Empfänger kann bei indirekter Adressierung mehrere Mailboxen/Ports besitzen.</p><br><p>Server kann nach Anmeldung eines Clients für jeden Client einen eigenen Port aufbauen, jeder Port kann durch eigenen Worker-Prozess/-Thread bedient werden.</p><br><img src="http://250kb.de/u/130207/p/w2SLv7K8Lmou.PNG" />
|
|
|
Wie funktioniert die Übertragung über <strong>Kanäle</strong>?
|
<p>Bisher: Verbindungslose Kommunikation, sodass senden kann, wer Adresse eines Ports kennt.</p><br><p>Kanal: Logische Verbindung zwischen 2 Kommunikationspartnern.</p><br><img src="http://250kb.de/u/130207/p/xyKHicO0uc2E.PNG" /><br><p>Expliziter Auf-/Abbau einer Verbindung zwischen 2 Ports, dabei Verbindung meist bidirektional (Ports für Senden und Empfangen). Garantierte Nachrichtenreihenfolge FIFO - bspw. bei TCP/IP-Verbindung.</p>
|
|
|
Wie funktioniert die Übertragung über <strong>Ströme (Streams)</strong>?
|
<p>Kanal zur Übertragung von Zeichensequenzen (Bytes) oder Grenzen. Bspw. TCP/IP, UNIX Pipes, Java Streams. In <strong>POSIX</strong> Pipes: Unidirektionaler Stream.</p><br><p>Schreiben von Daten in die Pipe:</p><br><p><font color="#777777">write(int pipe_desc, char *msg, int msg_len)</font> pipe_desc = Dateideskriptor</p><br><p>Bei vollem Puffer wird Schreiber blockiert!</p><br><p>Lesen aus der Pipe:</p><br><p>int read(int pipe_desc, char *buff, int max_len) max_len: Größe des Empfangsbuffers <em>buff</em>. Rückgabewert: Länge tatsächlich gelesener Daten.</p><br><p>Bei leerem Puffer wird Leser blockiert!</p><br><p><em>Unbenannte Pipe</em>, die zunächst zur erzeugendem Prozess bekannt ist - Dateideskriptoren werden an Kindprozesse vererbt.</p><br><p><em>Benannte Pipe</em> ist als spezielle "Datei" im Dateisystem sichtbar, wobei der Zugriff wie auf normale Datei (open, close, read, write) erfolgt. Erzeugung über Systemaufruf</p><br><p>mkfifo(char *name, mode_t mode)</p>
|
|
|
Wie funktioniert die <strong>Remote Procedure Call</strong> (RPC)?
|
<p>Vereinfachung der Realisierung von synchronen Aufträgen: Aufruf einer Prozedur in einem anderen Prozess. Client muss sich zunächst an den richtigen Server binden, Namensdienste verwalten Adressen derer. Danach RPC syntaktisch exakt wie lokaler Prozeduraufruf.</p><br><p>Semantische Probleme: Call-by-Reference-Parameterübergabe sehr problematisch, kein Zugriff auf globale Variablen, nur streng getypte Schnittstellen verwendbar, Datentyp muss zum Ein-/Auspacken (<em>Marshaling</em>) genau bekannt sein. Fehlerbehandlung problematisch.</p>
|
|
|
Wie funktioniert die Übertragung über <strong>Signale</strong>?
|
<p>Sofortige Reaktion des Empfängers auf eine Nachricht (asynchrones Empfangen) möglich. Asynchrone Unterbrechung des Empfänger-Prozesses (Software-Interrupt). Operationen (abstrakt):</p><br><p>Receive(Signalnummer, HandlerAdresse)</p><br><p>Signal(Empfänger, Signalnummer, Parameter)</p><br><p>Ideal: Erzeugung eines neuen Threads bei Eintreffen des Signals, der Signal-Handler abarbeitet. Historisch: Signal wird durch unterbrochenen Thread behandelt.</p><br><img src="http://250kb.de/u/130207/p/EQsEtlSSuEsJ.PNG" /><br><p>OS sichert Threadzustand im Thread-Kontrollblock und stellt Zustand für Signalbehandlung her - wechselseitiger Ausschluss á la Semaphore nicht möglich. Signale müssen ggf. gesperrt werden. In POSIX Signal an Prozess (<span style="text-decoration: underline;">nicht</span> Thread!):</p><br><p>kill(pid_t pid, int signo)</p><br><p><font color="#777777">SIGINT</font> Terminieren des Prozesses (^C)</p><br><p><font color="#777777">SIGKILL</font> Terminieren des Prozesses (nicht änderbar)</p><br><p><font color="#777777">SIGCHLD</font> Ignorieren (Kind-Prozess wurde beendet)</p><br><p><font color="#777777">SIGSTOP</font> Suspendieren des Prozesses (^Z)</p><br><p><font color="#777777">SIGCONT</font> Weiterführen des Prozesses falls gestoppt.</p>
|
|
|
Durch welche Tätigkeit des Betriebssystems entstehen <strong>Deadlocks</strong>?
|
<p>Verwaltung von Ressourcen, welche Prozessen zugeteilt werden: Ressource kann nur jeweils von einem Prozess genutzt werden (wechselseitiger Ausschluss), aber mehrere Instanzen der selben Ressource möglich.</p><br><p>Mögliches Problem: Deadlocks entstehen - Prozess A hat Scanner belegt und möchte CD-Brenner, Prozess B hat CD-Brenner belegt und möchte Scanner. A wartet auf B, B wartet auf A -> Deadlock.</p>
|
|
|
Worin unterscheiden sich <strong>unterbrechbare</strong> und <strong>ununterbrechbare Ressourcen</strong>?
|
<strong>Unterbrechbare Ressourcen</strong> können einem Prozess ohne Schaden wieder entzogen werden - so Prozessor (Sichern/Wiederherstellen des CPU-Zustandes bei Threadwechsel), Hauptspeicher (Plattenauslagerung). Deadlocks können verhindert werden.<p><strong>Ununterbrechbare Ressourcen</strong> können einem Prozess nicht ohne Ausführungsstörung entzogen werden - z.B. Brenner.</p>
|
|
|
Was ist unter einem <strong>Deadlock-Zustand</strong> zu verstehen?
|
<p>Eine Menge von Prozessen befindet sich in einem Deadlock-Zustand (Verklemmungs-Zustand), wenn jeder Prozess aus der Menge auf ein Ereignis wartet, das nur ein anderer Prozess aus dieser Menge auslösen kann.</p>
|
|
|
Welches sind die <strong>4 formalen Bedingungen für einen Ressourcen-Deadlock?</strong>
|
<strong>Wechselseitiger Ausschluss</strong>: Ressource kann zu einem Zeitpunkt von höchstens einem Prozess genutzt werden<p><strong>Hold-and-Wait</strong>: Ein Prozess, der bereits Ressourcen besitzt, kann weitere anfordern</p><br><p><strong>Ununterbrechbarkeit</strong> (kein Ressourcenentzug): Einem Prozess in Besitz einer Ressource kann dieser nicht gewaltsam entzogen werden</p><br><p><strong>Zyklisches Warten</strong> Es gibt eine zyklische Kette von Prozessen, bei der jeder Prozess auf eine andere Ressource wartet, die vom nächsten Prozess in der Kette belegt ist.</p>
|
|
|
Welche Arten von <strong>Knoten</strong> gibt es bei der <strong>Modellierung von Deadlocks</strong>?
|
<p>Prozesse O</p><br><p>Ressourcen [ ]</p><br><p>Kante Ressource -> Prozess: Ressource ist von Prozess belegt</p><br><p>Kante Prozess -> Ressource: Prozess wartet auf Zuteilung der Ressource</p><br><p><strong>Deadlock</strong> genau dann, wenn Graph einen <strong>Zyklus</strong> enthält.</p>
|
|
|
Welche <strong>Möglichkeiten zur Behandlung von Deadlocks</strong> gibt es?
|
<strong>Vogel-Strauss-Algorithmus</strong><p><strong>Deadlock-Erkennung und -Behebung</strong> lässt zunächst alle Anforderungen zu und löst Deadlock ggf. auf.</p><br><p><strong>Deadlock-Avoidance</strong> (Vermeidung): Ressourcenanforderung wird nicht zugelassen, wenn Deadlock entstehen könnte</p><br><p><strong>Deadlock-Prevention</strong> (Verhinderung) macht eine der 4 Deadlock-Bedingungen unerfüllbar.</p>
|
|
|
Wie unterscheidet sich die <strong>Deadlock-Erkennung</strong> bei <strong>einer bzw. mehrerer Ressourcen</strong> pro Typ?
|
<p>Eine Ressource: Belegungs-Anforderungs-Graph enthält Zyklus - benötigt Algorithmus, der Zyklen in Graphen findet.</p><br><p>Mehrere Ressourcen: Prozess wartet nicht mehr auf <em>bestimmte</em>, sondern <em>beliebige</em> Ressource des passenden Typs.</p><br><p><strong>Matrix-Algorithmus</strong>: <em>n</em> Prozesse, <em>m</em> Klassen von Ressourcen. Ressourcenvektoren</p><br><p><em>E</em> Anzahl verfügbarer Ressourcen für jede Klasse</p><br><p><em>A</em> Wieviele freie Ressourcen für jede Klasse</p><br><p>Belegungsmatrix <em>C</em> Anzahl der Ressourcen der Klasse <em>j</em>, die Prozess <em>P</em> belegt.</p><br><p>Anforderungsmatrix <em>R</em> Anzahl der Ressourcen von Klasse <em>j</em>, die Prozess <em>P</em> noch benötigt/im Moment anfordert.</p>
|
|
|
Wie funktioniert der <strong>Matrix-/Bankier-Algorithmus</strong>?
|
<p>1. Suche unmarkierten Prozess, wobei jede <em>i</em>-te Zeile von <em>R</em> <= <em>A</em> ist.</p><br><p>2. Wenn gefunden: Addiere Zeile von <em>C</em> zu <em>A</em>, markiere Prozess <em>P</em>, gehe zu 1.</p><br><p>3. Andernfalls: Ende</p><br><p>Alle am Ende nicht markierten Prozesse sind an Deadlock beteiligt. Schritt 1 sucht Prozess, der zu Ende laufen könnte, Schritt 2 simuliert Freigabe der Ressourcen am Prozessende.</p>
|
|
|
Wann wird <strong>Deadlock-Erkennung durchgeführt</strong> und welche Möglichkeiten zur Behebung gibt es??
|
<strong>Bei jeder Ressourcen-Anforderung</strong>: Schnellstmögliche Deadlock-Erkennung, jedoch ggf. zu hoher Rechenaufwand<p><strong>In regelmäßigen Abständen</strong></p><br><p><strong>Bei niedriger Prozessorauslastung</strong>: Niedrige Auslastung kann Hinweis auf Deadlock sein</p><br><p>Behebung durch</p><br><p><strong>Temporären Ressourcen-Entzug</strong> Schwierig bis unmöglich</p><br><p><strong>Rücksetzen eines Prozesses</strong> Regelmäßige Sicherung (Checkpoint) des Prozesszustandes - bei Verklemmung Rücksetzung auf Checkpoint. Auch schwierig.</p><br><p><strong>Abbruch eines Prozesses</strong> wählt Prozess, der problemlos neu gestartet werden kann - etwa in DBS-Transaktionen.</p>
|
|
|
Wie funktioniert <strong>Deadlock-Avoidance</strong> per <strong>Bankiers-Algorithmus</strong>?
|
<p>Es gibt <em>sichere Zustände</em> (Ausführungsreihenfolge der Prozesse, in der alle Prozesse selbst bei maximaler Ressourcenanforderung ohne Deadlock zu Ende laufen) und <em>unsichere Zustände</em>.</p><br><p>OS teilt Ressource nur zu, wenn Deadlock ausgeschlossen ist - Prüfung bei Anforderung, ob Zustand <em>nach</em> der Anforderung noch sicher ist. Wenn nicht, wird anfordernder Prozess blockiert. Hierzu muss OS die (maximalen) zukünftigen Forderungen aller Prozesse kennen, was nur in speziellen Anwendungsfällen möglich ist.</p><br><p>Verwendung des Matrix-Algorithmus, wobei <em>R</em> nun die <em>maximalen zukünftigen Forderungen</em> beschreibt</p>
|
|
|
Wie funktioniert vorbeugendes Verhindern von Deadlocks per <strong>wechselseitigem Ausschluss</strong>?
|
<p>Eine der vier Deadlock-Bedingungen wird unerfüllbar gemacht, sodass Deadlocks unmöglich sind - häufigste Praxislösung.</p><br><p><strong>Wechselseitiger Ausschluss</strong>: Ressourcen nur dann an Prozesse zuteilen, wenn dies unvermeidlich ist - bspw. Drucker-Spooler, sodass keine Konkurrenz entstehen kann. Jedoch Deadlocks bspw. durch Konkurrenz um Spooler-Platzierung möglich.</p><br><p><strong>Hold-and-Wait-Bedingung</strong>: Forderung, das jeder Prozess seine Ressourcen bereits beim Start anfordern muss. I.d.R. jedoch nicht bekannt und Ressourcen-Verschwendung. Anwendung bei DBS-Systemen (Sperr-/Zugriffsphase). Alternative: Vor Ressourcen-Anforderung kurz alle belegten Ressourcen freigeben, jedoch wg. wechselseitigem Ausschluss unpraktikabel.</p><br><p><strong>Ununterbrechbarkeit</strong> (kein Ressourcenentzug): I.A. unpraktikabel.</p><br><p><strong>Zyklisches Warten</strong>: In der Praxis erfolgsversprechend: Durchnummerieren aller Ressourcen, Anforderungen derer zu beliebigem Zeitpunkt, jedoch nur in aufsteigender Reihenfolge - Prozess darf nur Ressource mit größerer Nummer als bereits belegte Ressource anfordern. Deadlocks zu jedem Zeitpunkt unmöglich durch Betrachtung der reservierten Ressource mit höchster Nummer. Prozess, der diese Ressource belegt, kann zu Ende laufen (wird nur Ressourcen mit höherer ID anfordern). Induktion: Alle Prozesse können zu Ende laufen. Probleme: Festlegung der Ordnung nicht immer praktikabel, u.U. Ressourcenverschwendung durch Reservierung von nicht genutzten Ressourcen.</p>
|
|
|
Wie kommt <strong>Verhungerung</strong> zustande und wie wird sie vermieden?
|
<p>Ein Prozess bekommt wegen ständiger Ressourcenanforderungen anderer Prozesse eine Ressource nie zugeteilt, obwohl kein Deadlock vorliegt (Beispiel Leser/Schreiber-Problem).</p><br><p>Vermeidung bspw. durch <strong>FIFO</strong>: Teile Ressource an den Prozess zu, der am längsten wartet.</p>
|
|
|
Wie lautet die <strong>Alternative zum Threadwechsel</strong>?
|
Thread-Scheduling! Auswahlstrategie, welcher Thread als nächstes wie lange rechnen darf. Verwaltung des Betriebsmittels Prozessor.
|
|
|
Welche <strong>Formen der Betriebsarten</strong> eines Systems gibt es?
|
<strong>Stapelverarbeitung</strong> arbeitet nicht-interaktive Aufträge ab, häufig bei Großrechnern<p><strong>Interaktiver Betrieb</strong> bei Arbeitsplatzrechnern/Servern</p><br><p><strong>Echtzeitbetrieb</strong> bei Steueraufgaben, Multimedia-Anwendungen</p>
|
|
|
Welche <strong>Kriterien</strong> gibt es beim <strong>Scheduling</strong>?
|
<p><strong><span style="text-decoration: underline;">Benutzersicht</span></strong></p><br><p><strong>Minimierung der Durchlaufzeit</strong> im Stapelbetrieb: Zeit zwsciehn Eingang/Abschluss eines Jobs inkl. Wartezeiten</p><br><p><strong>Minimierung der Antwortzeit</strong> im Interaktiven Betrieb: Zeit zwischen Eingabe einer Anfrage und Beginn der Ausgabe</p><br><p><strong>Einhaltung von Terminen</strong> im Realzeitbetrieb: Ausgabe muss nach bestimmter Zeit erfolgt sein</p><br><p><strong>Vorhersehbarkeit</strong>: Durchlaufzeit/Antwortzeit i.W. unabhängig von der Auslastung des Systems</p><br><strong><p><b><span style="text-decoration: underline;">Systemsicht</span></strong></p><br>Maximierung des Durchsatzes</b> im Stapelbetrieb: Anzahl der fertiggestellten Jobs pro Zeiteinheit<p><strong>Optimierung der Prozessorauslastung</strong> im Stapelbetrieb: Prozentualer Anteil der Zeit, in der der Prozessor beschäftigt ist</p><br><p><strong>Balance</strong>: Gleichmäßige Auslastung aller Ressourcen</p><br><p><strong>Fairness</strong>: Vergleichbare Threads sollen gleich behandelt werden</p><br><p><strong>Durchsetzung von Prioritäten</strong>: Threads mit höherer Priorität sind bevorzugt zu behandeln</p>
|
|
|
Welche 3 <strong>Ebenen des Schedulings</strong> gibt es?
|
<strong>Langfristig: Eingangs-Scheduler</strong> bei Systemen mit Stapelverarbeitung, d.h. wann werden Prozesse für den Job erzeugt? Ziel: Mischung aus CPU-/E/A-lastigen Prozessen<p><strong>Mittelfristig: Speicher-Scheduler</strong> Auslagern und Suspendierung von Prozessen bspw. bei Speicherengpässen, legt Multiprogramming-Grad fest</p><br><p><strong>Kurzfristig: CPU-Scheduler</strong> Zuteilung der CPU an bereite Threads</p>
|
|
|
Worin unterscheiden sich <strong>nicht-präemptives</strong> und <strong>präemptives Scheduling</strong>?
|
<strong>Nicht-präemptives Scheduling</strong>: Thread darf rechnen, bis er freiwillig die CPU aufgibt oder blockiert. Sinnvoll bei Stapel-/Echtzeitsystemen<p><strong>Präemptives Scheduling</strong>: Scheduler kann einem Thread die CPU zwangsweise entziehen - entweder nach Ablauf einer Zeit oder wegen rechenbereitem Thread mit höherer Priorität. Unterstützt interaktive- und Echtzeitsysteme.</p>
|
|
|
Welche <strong>Scheduling-Zeitpunkte</strong> gibt es beim <strong>CPU-Scheduler</strong>?
|
<p>Bei Beendigung eines Threads</p><br><p>Bei freiwilliger CPU-Aufgabe eines Threads</p><br><p>Bei Blockierung eines Threads <em>Grund sollte berücksichtigt werden</em></p><br><p><font color="#993300">Bei Erzeugung eines Threads</font></p><br><p><font color="#993300">Bei E/A-Interrupt <em>Evtl. werden blockierende Threads rechenbereit</em></font></p><br><p><font color="#993300">Regelmäßig bei Timer-Interrupt</font></p><br><p><span style="color: rgb(153, 51, 0);"><em>nur bei präemptivem Scheduling</em></span></p>
|
|
|
Was hat es mit <strong>Cache-Affinity</strong> / <strong>Affinitys Scheduling</strong> auf sich?
|
<p>Ein einmal auf einer CPU ausgeführter Thread sollte nach Möglichkeit auf dieser CPU bleiben. Jeder Thread erhält eine oder mehrere bevorzugte CPUs, einfache Realisierung durch getrennte Wartschlangen je CPU.</p><br><p>Falls leer: Warteschlangen anderer CPUs inspizieren.</p>
|
|
|
<p>Welche <strong>Scheduling-Algorithmen</strong> gibt es?</p>
|
<strong>FCFS</strong> Sehr einfach, gute CPU-Auslastung, vorwiegend Stapelverarbeitung. Durchlaufzeit nicht optimiert, Balance durch <em>Convoy-Effekt</em> evtl. schlecht.<p><strong>SJF</strong> Ziel der Durchlaufzeit-Optimierung - Dauer muss vorab bekannt sein, was im Stapelbetrieb i.A. erfüllt ist. I.A. nicht-präemptiv, keine Blockierung durch E/A. Im präemptiven Fall und bei Blockierung betrachtete <span style="text-decoration: underline;">Rest</span>laufzeiten. In interaktiven Systemen: Betrachte CPU-Burst als Job mit Schätzung der Dauer.</p><br><p><strong>RR</strong> Präemptive Variante von FCFS - jeder Thread darf höchstens eine bestimmte Zeit (Quantum, Zeitscheibe, Time Slice) rechnen. Ebenso einfach zu realisieren über Warteschlange aller rechenbereiten Threads und Timer-Interrupt. Bei kurzem Quantum kurze AW-Zeiten/schlechte CPU-Nutzung durch häufige Thread-Wechsel, bei langem Quantum umgekehrt. Nicht fair, da E/A-lastige Threads benachteiligt werden.</p><br><p><strong>Prioritätenbasiertes Scheduling</strong> I.d.R. präemptiv. Statische Prioritäten bei Threaderzeugung festgelegt, häufig bei Realzeit-Systemen. Oder: Dynamische Prioritäten können abhängig vom Threadverhalten laufend geändert werden - z.B. bestimmt durch Länge des letzten CPU-Burst des Threads.</p><br><p><strong>Multilevel Scheduling</strong> Mehrere Warteschlangen für bereite Threads - je Warteschlange eigene Auswahlstrategie möglich, zusätzlich Strategie zur Auswahl der <em>aktuellen</em> Warteschlange (PriO/RR/...). Statisches Verfahren (Thread fest einer Warteschlange zugeordnet) oder dynamisch (Thread in Abhängigkeit des Verhaltens zwischen Warteschlangen wechselnd). Threads werden in Prioritäten<span style="text-decoration: underline;">klassen</span> eingeteilt - je Klasse 1 Warteschlange, unterschiedliche Scheduling-Strategien innerhalb der Warteschlange.</p>
|
|
|
Worin liegt der Unterschied zwischen <strong>Adressraum</strong> und <strong>Speicher</strong>?
|
<strong>Adressraum</strong> ist die Menge aller verwendbaren Adressen (<em>logisch</em> aus Sicht eines Programms, den ein Prozess verwenden kann, <em>physisch</em> Adressen, die die Hardware verwendet). Nicht immer identisch, siehe <em>Paging</em>.<p><strong>Speicher</strong> ist das Stück Hardware, das die Daten speichert - oft Synonym für physischen Adressraum.</p>
|
|
|
<p>Wie funktionierte die <strong>statische Relokation</strong>?</p>
|
Wenn ein Programm an die Adresse 16.384 geladen wurde, wurde während des Ladevorgangs die Konstante 16.384 zu jeder Programmadresse addiert. Zwar grundsätzlich praktikabel, jedoch keine allgemeine Lösung, die dazu das Laden verlangsamt.
|
|
|
Durch welche 2 Methoden ist <strong>Relokation & Speicherschutz</strong> durch Hardware realisierbar?
|
<strong>Basisregister</strong>: Anfangsadresse der Partition<p><strong>Grenzregister</strong>: Länge der Partition</p><br><p>Werden bei Prozesswechsel vom OS mit Werten des aktuellen Prozesses geladen. Bei jedem Speicherzugriff in Hardware Vergleich der <em>logischen</em> Adresse mit Grenzregister (>=Ausnahme), addiere Basisregister zu logischer Adresse, Ergebnis physische Speicheradresse.</p>
|
|
|
Was geschieht bei der Methode des <strong>Swappings</strong> und worin liegt deren Nachteil?
|
<p>Feste Partitionen sind nur für Stapelverarbeitung geeignet, bei interaktiven Systemen hingegen brauchen alle aktiven Programme u.U. mehr Speicher/Partitionen als vorhanden, daher temporäre Auslagerung von Speicherbereichen auf Festplatte - einfachste Variante <em>Swapping</em>. Kompletter Prozessadressraum wird ausgelagert und Prozess suspendiert, Wieder-Einlagerung erfolgt evtl. an anderer Stelle im Speicher - Relokation dabei i.d.R. über Basisregister.</p><br><p>Unterschied zu festen Partitionen in variabler Zahl/Größe/Ort der Partitionen. Löcher im Speicher können durch Verschieben zusammengefasst werden, Ein-/Auslagern jedoch sehr zeitaufwendig. Prozess kann evtl. zur Laufzeit mehr Speicher anfordern und benötigt evtl. Verschiebung/Auslagerung von Prozessen.</p><br><p>Zudem schlechte Speicherausnutzung: Prozess benötigt i.d.R. nicht immer seinen ganzen Adressraum.</p>
|
|
|
Welche 2 <strong>Suchverfahren</strong> gibt es in der <strong>Dynamischen Speicherverwaltung</strong>?
|
<p>Ziel, einen passenden Eintrag in der Freispeicherliste zu finden, sodass benötigter Anteil an Prozess zugewiesen wird. Der Rest wird wieder in Freispeicherliste eingetragen, was zu (externer) Fragmentierung des Speichers führt.</p><br><p><strong>First Fit</strong>: Die Speicherverwaltung geht die Liste der Reihe nach durch, bis eine ausreichend große Lücke gefunden wird, diese wird in zwei Teile geteilt - einen für den Prozess und einen für den unbenutzten Speicher. Verwende ersten passenden Speicherbereich. Einfach & relativ gut.</p><br><p><strong>Quick Fit</strong>: Verschiedene Listen für Freibereiche mit gebräuchlichen Größen - schnelle Suche, jedoch Problem der Verschmelzung freier Speicherbereiche. <strong>Buddy-System</strong>: Blockgrößen sind Zweierpotenzen - einfaches Verschmelzen, aber interne Fragmentierung.</p>
|
|
|
Wie funktioniert die <strong>Seitenbasierte Speicherverwaltung (Paging)</strong>?
|
<p>Strikte Trennung zwischen <em>logischen Adressen</em> (virtuelle Adressen) und <em>physischen Adressen</em>, die der Hauptspeicher nutzt. Bei jedem Speicherzugriff wird die vom Prozess erzeugte logische Adresse durch Hardware (MMU) auf eine physische Adresse abgebildet. Hierzu Aufteilung der Adressraum-Blöcke in feste Größe:</p><br><p><strong>Seite</strong> Block im virtuellen Adressraum</p><br><p><strong>Kachel</strong> (Seitenrahmen): Block im physischen Adressraum</p><br><p>Typische Seitengröße 4 KByte</p><br><p>Umsetzungstabelle definiert für jede Seite physische Adresse der zugehörigen Kachel, sofern vorhanden sowie die Zugriffsrechte.</p><br><img src="http://250kb.de/u/130210/p/nCxr3ScFNcJu.PNG" /><br><p>Adressabbildung = Zusammenspiel von OS und MMU. OS setzt für jeden Prozess eine Seitentabelle auf, Tabelle wird bei Prozesswechsel ausgetauscht. Die MMU realisiert dabei die Adressumsetzung</p><br><p>Falls einer Seite keine Kachel zugeordnet ist (Present-Bit gelöscht) -> Ausnahme (<strong>Seitenfehler</strong>)</p><br><p>Speicherschutz ist automatisch durch Seitentabellen-Kachelverweis-Zuordnung gegeben</p><br><p>Zusätzlich Zugriffsrechte für einzelne Seiten z.B. Schreibschutz für Programmcode, Erzeugung einer Ausnahme bei Verletzung.</p>
|
|
|
Was ist bei <strong>mehrstufigen Seitentabellen</strong> zu beachten?
|
<p>Jeder Seite muss eine Kachel zugeordnet werden könne - Problem des Speicherplatzbedarfs.</p><br><p>Lösung: Mehrstufige Tabellen - bei 2^20 Seiten 1. Stufe mit 1.024 Einträge, 2. Stufe <=1.024 Seitentabellen á 1.024 Einträge - Tabellen nur vorhanden, wenn notwendig.</p><br><p><span style="text-decoration: underline;">Alternative</span>: <strong>Invertierte Seitentabellen</strong></p>
|
|
|
Wie funktioniert der <strong>Translation Lookaside Buffer</strong>?
|
<p>Seitentabellen liegen im Speicher, für jeden Speicherzugriff mehrere zusätzliche Zugriffe für Adressumsetzung nötig.</p><br><p>Optimierung der MMU, welche kleinen Teil der Adressabbildung in internem Speicher hält <em>TLB</em>!</p><br><p>Verwaltung entweder durch Hardware (MMU) bei CISC á x86 oder durch Software bei einigen RISC-Prozessoren: MMU erzeugt Ausnahme, falls für eine Seite kein TLB-Eintrag vorliegt, OS behandelt Ausnahme per Durchsuchung der Seitentabellen und Ersetzen eines TLB-Eintrags.</p><br><p>Dadurch: Höherer Multiprogramming-Grad möglich, Prozessadressraum (logischer) kann größer als Hauptspeicher (physischer Adressraum) sein.</p><br><p>OS muss genügend Speicher bereitstellen, um für jeden Prozess das <em>Working Set</em> für genügend großes <em>k</em> im Hauptspeicher zu halten. Falls nicht: <strong>Thrashing</strong>, <strong>Seitenflattern</strong>, sodass Prozesse ständig ausgelagerte Werte benötigen, zum Einlagern aber auf andere Seite verdrängt verdrängen. Systemleistung sinkt dramatisch, mögliche Abhilfe durch <em>Swapping</em> - verdränge einen Prozess komplett aus dem Speicher.</p>
|
|
|
<p>Welche <strong>Seitenersetzungsalgorithmen</strong> gibt es?</p>
|
<p><strong>Optimale nach Belady</strong>: Verdränge Seite, die am längsten nicht mehr benötigt wird. I.d.P. nicht realisierbar, jedoch Referenz für andere Verfahren.</p><br><p><strong>Not Recently Used</strong> MMU-Statusbits R (bei Lese-Zugriff gesetzt)/M (Schreib-Zugriff) als Basis</p><br><p><strong>FIFO</strong> Verdränge die Seite, die am längsten im Hauptspeicher ist - einfach, aber schlecht, da Zugriffsverhalten (<em>Working Set</em>) ignoriert wird</p><br><p><strong>Second Chance/Clock</strong> Bei Seitenfehler wird die Seite geprüft, auf die der Zeiger zeigt. Ist das R-Bit 0, wird die Seite ausgelagert und die neue an der Stelle in der Uhr eingefügt und der Zeiger um eine Stelle vorgerückt. Bei R1 wird es gelöscht, der Zeiger vorgerückt und der Vorgang so löange wiederholt, bis Seite mit R0 gefunden wurde.</p><br><p><strong>Least Recently Used</strong> Verdränge die Seite, die am längsten nicht benutzt wurde - Vermutung, dass diese auch in Zukunft nicht mehr benutzt wird. Nahezu optimal, sofern Lokalität gegeben. Problem der (Software-)Implementierung, da bei jedem Zugriff ein Zeitstempel aktualisiert werden muss und somit nur Näherungen (z.B. <em>Aging</em>) möglich sind.</p>
|
|
|
Welche <strong>Lösungsansätze</strong> gibt es bzgl. instabiler Treiber?
|
<p>Zertifizierte Treiber</p><br><p>Treiber als Systemprozesse im Benutzeradressraum</p><br><p>Universalgeräte mit universalen Treibern</p>
|
|
|
Welche <strong>Aufgaben</strong> und <strong>Grundfunktionen</strong> hat geräteunabhängige E/A-Software mitzubringen?
|
<strong>Aufgaben</strong>: Einheitliche Schnittstelle für Gerätetreiber (Namensgebung für Geräte, Zuordnung von Treibern, Zugriffsschutz), Pufferung von Daten, Fehlerbehandlung, Anforderung/Freigabe von Geräten (für exklusive Nutzung, z.B. Brenner), Verdeckung von Unterschieden der Geräte (bspw. unterschiedliche Blockgrößen).<p><strong>Grundfunktionen</strong>: Öffnen eines Geräts (Argumente: Gerätename, Betriebsparameter. Ergebnis: <em>Handle</em> zum Zugriff auf das Gerät), Schließen des Geräts, Lesen/Schreiben von Daten(blöcken).</p>
|
|
|
Welche <strong>Ansätze zur E/A-Durchführung</strong> gibt es?
|
<strong>Programmierte E/A</strong> Gerätetreiber wartet nach Auftrag an Controller <span style="text-decoration: underline;">aktiv</span> in Warteschlange auf Ergebnis (<em>busy waiting</em>): Beispiel Treiber-Code zur Ausgabe auf Drucker - Puffer aus Benutzer-Adressraum in Kern-Adressraum kopieren. Ineffizient, da CPU in Zwischenzeit andere Aufgaben erfüllen könnte.<p><strong>Interrupt-gesteuerte E/A</strong> Treiber beauftragt Controller und kehrt sofort zurück, wobei auftraggebender Thread ggf. blockiert wird. Controller -Interrupt> CPU wenn Auftrag erledigt. Gerät wieder bereit, i.d.R. identifiziert Interrupt-Nummer das Gerät. Treiber behandelt die Unterbrechung, auftraggebender Thread wird ggf. wieder rechnend gesetzt. Sinnvoll bei langsamen E/A-Geräten.</p><br><p><strong>Direkter Speicherzugriff (DMA)</strong> Transport der Daten zwischen Controller <-> Speicher durch separate Hardware: DMA-Controller, der oft in Geräte-Controller integriert ist. Treiber sendert Geräte-Adresse, Startadresse/Länge der Daten und Transferrichtugn an DMA-Controller -> DMA-Controller erzeugt Interrupt als Fehlermeldung. Vorteil der CPU-Entlastung, Einsparung von Interrupts. Jedoch nur sinnvoll bei Übertragung größerer Datenblöcke.</p>
|
|
|
Wie ist eine <strong>Festplatte aufgebaut</strong>?
|
<strong>Spur</strong>wechsel durch Verschieben des <strong>Arms</strong>, d.h. aller Köpfe.<p>Einteilung der Festplatte in <strong>Oberfläche</strong> (Kopf), <strong>Zylinder</strong>, <strong>Sektor</strong>. Sektor einer Spur nimmt einen Datenblock á 512 Byte auf. 18.3GB: 12 Oberflächen, 10.601 Zylinder, 281 Sektoren.</p><br><p>Früher zeigte Controller dem OS eine virtuelle Geometrie an, heute lineare Adressierung der Blöcke (LBA).</p><br><p><strong>Bestimmende Faktoren</strong>: Suchzeit (5-10ms), Rotationsverzögerung (2-6ms), Dauer der Datenübertragung (5-100µs pro Block).</p><br><p>Zugriffszeit <strong>dominiert durch Suchzeit</strong>, daher Dateien möglichst in aufeinanderfolgenden Sektoren (Prefetching + Caching), geeignetes Scheduling der Plattenzugriffe.</p>
|
|
|
Welche Formen des <strong>Schedulings von Plattenzugriffen</strong> gibt es?
|
<strong>FCFS</strong> Viele unnötige Bewegungen des Plattenarms<p><strong>SSF</strong> Zugriffe in Nähe der aktuellen Position bevorzugen. Problem der Unfairness und möglichen Verhungerung</p><br><p><strong>Aufzug-Algorithmus</strong> Erst in eine Richtung, bis es in dieser keine Anfragen mehr gibt, dann Richtung wechseln.</p>
|
|
|
Wie erfolgt die <strong>Realisierung von Dateisystemen</strong>?
|
<p>Im <strong>Schichtenmodell</strong></p><br><p><strong>Datenträgerorganisation</strong> Einheitliche Schnittstelle zu allen Datenträgern, Datenträger als Folge von Blöcken betrachtet. Evtl. Einteilung in Partitionen. Diese werdne als Folge von (logischen) Blöcken betrachtet und fortlaufend numeriert. MBR|Partitionstabelle|P1|P2|... In der Partition: Superblock (Verwaltungsinformationen wie Größe), Superblock, Freispeicherverwaltung, I-Node, Wurzelverzeichnis, Dateien und Verzeichnisse</p><br><p><strong>Blockorientiertes Dateisystem</strong> Realisierung von Dateien</p><br><p><strong>Dateiverwaltung</strong> Dateinamen und Verzeichnisse</p>
|
|
|
Welche <strong>Aufgaben</strong> hat die Datenträgerorganisation?
|
<strong>Formatierung des Datenträgers</strong><p><strong>Lesen/Schreiben von Blöcken</strong></p><br><p><strong>Verwaltung freier Blöcke</strong>: Vgl. dynamische Speicherverwaltung, meist Bitvektoren statt Freispeicherliste</p><br><p><strong>Verwaltung defekter Blöcke</strong> (ebenfalls über Bitvektoren)</p>
|
|
|
Wie funktioniert das <strong>Blockorientierte Dateisystem</strong>?
|
<p>Datei als Folge von Blöcken realisiert, Zuteilung von Blöcken an Dateien in <strong>zusammenhängender Belegung</strong>. Datei durch Anfangsblock und Blockanzahl beschrieben, sehr gute Performance beim Lesen, jedoch Problem der Speicherverwaltung (anfügen von Dateien, Fragmentierung,...)</p><br><p><strong>Verteilte Belegung</strong> Einfache Speicherverwaltung, schlechte Performance. In der Praxis Belegung möglichst zusammenhängend. Realisierung durch verkettete Listen mit Nachteil ineffizienter wahlfreier Zugriffe, zudem Dateiblock-Länge keine Zweierpotenz mehr. Realisierung durch FAT: Verkettung außerhalb der Blöcke, Tabelle kann (teilweise) im Hauptspeicher gehalten werden.</p>
|
|
|
Wie funktioniert die <strong>Realisierung von Index-Knoten (I-Nodes)</strong> im blockorientierten Dateisystem?
|
<p>Jeder Datei ist eine Datenstruktur zugeordnet. Diese enthält Tabelle mit Verweisen auf Dateiblöcke - wg. Speicherplatzbedarf ggf. mehrstufig.</p><br><p>Tabelle kann im Hauptspeicher gehalten werden, schneller wahlfreier Zugriff auf Datei möglich.</p><br><img src="http://250kb.de/u/130210/p/ji2Osl4amo4v.PNG" />
|
|
|
Welche <strong>Aufgaben</strong> hat die <strong>Dateiverwaltung</strong>?
|
<p>Realisierung von Verzeichnissen</p><br><p>Verzeichnis enthält für jede Datei Name, Plattenadresse (erster Dateiblock, <em>I-Node</em>), Dateiattribute</p><br><p>Dateiattribute u.a. Eigentümer, Schutzinformation / Dateityp, Sperre, archiviert / Erstellungszeit, Zeit der letzten Änderung.</p>
|