![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
71 Cards in this Set
- Front
- Back
|
Frequentist view of probability |
Probabilities come from relative frequencies |
|
|
Subjectivist view of probability |
Probabilities are degrees of belief |
|
|
Expectation equation |
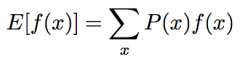
|
|
|
Independence of A and B (and & or) |
P(A and B) = P(A)P(B) P(A or B) = P(A) + P(B) - P(A)P(B) |
|
|
Mutual exclusion of A and B (and & or) |
P(A or B) = P(A) + P(B) P(A and B) = 0 |
|
|
Conditional probability P(a|b) |
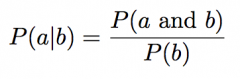
|
|
|
Bayes Rule |
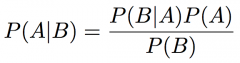
|
|
|
JPD |
Joint probability distribution |
|
|
Joint distributions |
P(X1, …, Xn) From this you can infer P(X1), P(X1|Xs) etc. |
|
|
What are joint distributions useful for? |
Classification - P(X1 | X2 … Xn) Co-occurence - P(Xa, Xb) Rare event detection - P(X1, …, Xn) |
|
|
Conditional independence of A and B |
P(A|B, C) = P(A|C) P(A, B|C) = P(A|C) P(B|C) |
|
|
Bayes Nets Given ____, each RV independent of ____ |
Given parents, each RV independent of non-descendants |
|
|
CPT |
Conditional probability table (use in Bayes Nets) |
|
|
JPD decomposes to... P(x1, ..., xn) |
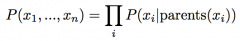
|
|
|
What does the CPT show? (equation) |
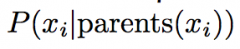
|
|
|
Naive Bayes |
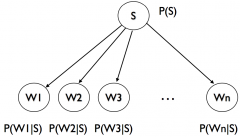
Want to find P(S|W1 … Wn) |
|
|
Sampling the conditional (2 approaches) |
Rejection sampling - Sample, throw away when mismatch occurs (B != b) Importance sampling - Bias the sampling process to get more “hits” - Use a reweighing trick to unbias probabilities |
|
|
|
probability density function |
|
|
How to use a PDF (equation) |
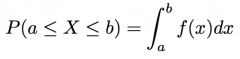
|
|
|
Markov assumption |
State at t depends only on state at t-1 (Future independent of past given present) We can write P(St|St-1, St-2, ..., S0) as P(St|St!1) |
|
|
Markov model |
A model operating under the Markov assumption |
|
|
Markov chain |
Sequence of events generated by Markov model |
|
|
Assumptions for state machine (Markov model) |
- Markov assumption - Transition probabilities don’t change with time - Event space doesn’t change with time - Time moves in discrete increments |
|
|
HMM |
Hidden Markov Model |
|
|
Uses for HMM |
Monitoring/Filtering - P(St | E0 … Et) - Estimate patient disease state - Where is the robot? Prediction - P(St | E0 … Ek), k < t - Where will the robot be in 3 steps? Smoothing - P(St | E0 … Ek), k > t - Where was the robot at t=3? Most likely state sequence - What was the robot's path? |
|
|
Viterbi Algorithm |
P(S0) = P(S0 | O0) P(S1) = P(S0) P(S1 | S0) P(S1 | 01) = P(S0 | O0) P(S1 | S0) P(S1 | 01) ...and recurse |
|
|
PDDL |
Planning Domain Description Language |
|
|
Components of PDDL |
Domain - describes a class of tasks - Predicates - Operators Task - an instance of domain - Objects - Start and goal states |
|
|
PDDL Predicate |
Given object(s), returns T/F |
|
|
PDDL Operator |
Operator has: - Name - Parameters - Preconditions - Effects *Note: Markov assumption |
|
|
PDDL State |
Describe the world at a moment in time Conjunction of positive literal predicates Those not mentioned assumed to be false (closed world assumption) |
|
|
PDDL Goal |
Partial state expression Conjunction of literal predicates Those not mentioned are don’t-cares |
|
|
When executing an action in PDDL... |
- Check preconditions - Delete negative effects - Add positive effects |
|
|
Planning approaches |
Forward search - Need a heuristic or it's hopeless FFPlan - Relaxation - make the problem easier Regression planning - Start at goal, regress backward, reversing operators |
|
|
MDP |
Markov Decision Process |
|
|
Components of MDP |
S set of states A set of actions γ discount factor R reward function - R(s, a, s′) T transition function - T(s′|s, a) |
|
|
Absorbing state |
Execution stops |
|
|
Markov property for MDPs (extended) |
s_t+1 depends only on s_t and a_t r_t depends only on s_t and a_t |
|
|
Goal of MDP is to find a ____ that maximizes ____ |
Goal of MDP is to find a policy that maximizes return (expected sum of rewards/min sum of costs) |
|
|
Policy (equation) |
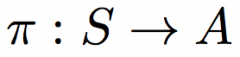
|
|
|
Return (equation & def) |
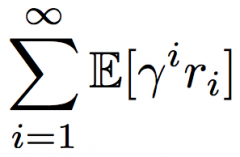
Max expected sum of rewards |
|
|
Policy vs. Plan |
Policy: an action for every state Plan: a sequence of actions |
|
|
Optimal policy (equation) |
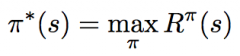
|
|
|
VF |
Value function |
|
|
Value function |
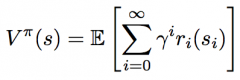
|
|
|
Bellman's equation |
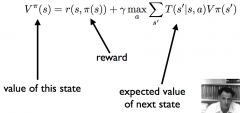
|
|
|
PPDDL |
probabilisticproblem domain definition language Now operators have probabilistic outcomes |
|
|
Machine learning |
Using experience to improve performance on some task |
|
|
Types of learning |
Supervised learning Labeled data Unsupervised learning No feedback, just data Reinforcement learning Sequential data, weak labels |
|
|
Supervised learning |
Given training data: X = {x1, …, xn} inputs Y = {y1, …, yn} labels Produce decision function f : X -> Y That minimizes error: Σ err(f(xi), yi) |
|
|
Classification vs. Regression |
Set of labels Y Y is discrete = Classification - Minimize number of errors Y is real-valued = Regression - Minimize sum squared error |
|
|
Hypothesis space |
Class of functions F, from which to find f that minimizes error |
|
|
Why test/train split? |
Do not measure error on the data you train on! May not generalize. Fit f using training set Measure error on test set |
|
|
Decision trees |
- If all the labels are the same, we have a leaf node - Pick an attribute and split data on it - Recurse on each half |
|
|
Information gain |
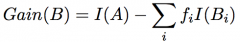
|
|
|
Perceptron equation |
𝑓(𝒙) = 𝑠𝑖𝑔𝑛(𝒘 ∙ 𝒙 + 𝑐) 𝑓(𝒙) : function of the perceptron 𝑠𝑖𝑔𝑛(𝑧) : returns true if 𝑧 ≥ 0, false otherwise 𝒙 : vector of inputs 𝒘 : vector of perceptron’s weights 𝑐 : bias |
|
|
Perceptrons - how they work |
For x = [x(1), … , x(n)]: [inputs] - Create an n-d line - Slope for each x(i) [weights] - Constant offset [bias] |
|
|
Perceptron Algorithm |
Set w and c to 0 for each xi: ---predict zi = sign(w.xi + c) ---if zi != yi: -------w = w + a(yi - zi)xi a = learning rate Converges if linearly separate. |
|
|
Probabilistic classifier |
Logistic regression ?????? |
|
|
K nearest neighbors |
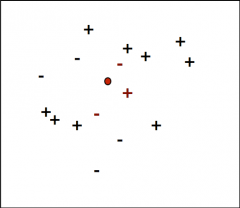
Distance metric D(xi, xj) For a new data point x_new: - Find k nearest points in X (measured via D) - Set y_new = the label that the majority of those neighbors have |
|
|
Unsupervised learning |
Given inputs: X = {x1, …, xn} Try to understand thestructure of the data. |
|
|
Clustering |
Split data into discrete clusters (types) Given: Data points X = {x1, …, xn} Find: - Number of clusters k - Assignment function f(x) = {1, …, k} * can answer "which cluster", but not "does this belong" |
|
|
k-means |
- Pick k - Place k points (“means”) in the data - Assign new point to ith cluster if nearest to ith “mean” |
|
|
k-means algorithm (decide where to put the means) |
- Place k “means” at random - Assign each point in the data to closest “mean” - Move “mean” to mean of assigned data |
|
|
GMM |
Gaussian mixture model |
|
|
PCA |
Principle Components Analysis Project data into a new space - Dimensions are linearly uncorrelated - Measure of importance for each dimension |
|
|
Reinforcement learning |
Learning how to interact with anenvironment to maximize reward. Learning counterpart of planning |
|
|
Goal of reinforcement learning |
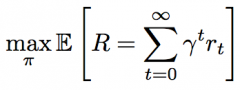
Find policy π that maximizes expected return (sum ofdiscounted future rewards) |
|
|
Reinforcement in relation to MDP |
S set of states A set of actions γ discount factor R reward function - R(s, a, s′) T transition function - T(s′|s, a) *** don't know R and/or T *** |
|
|
optimal policy (π) |
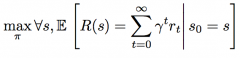
Maximizes thereturn from every state |
|
|
Value function |
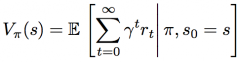
Value of state s under policy π - Estimate reward - Improve policy |